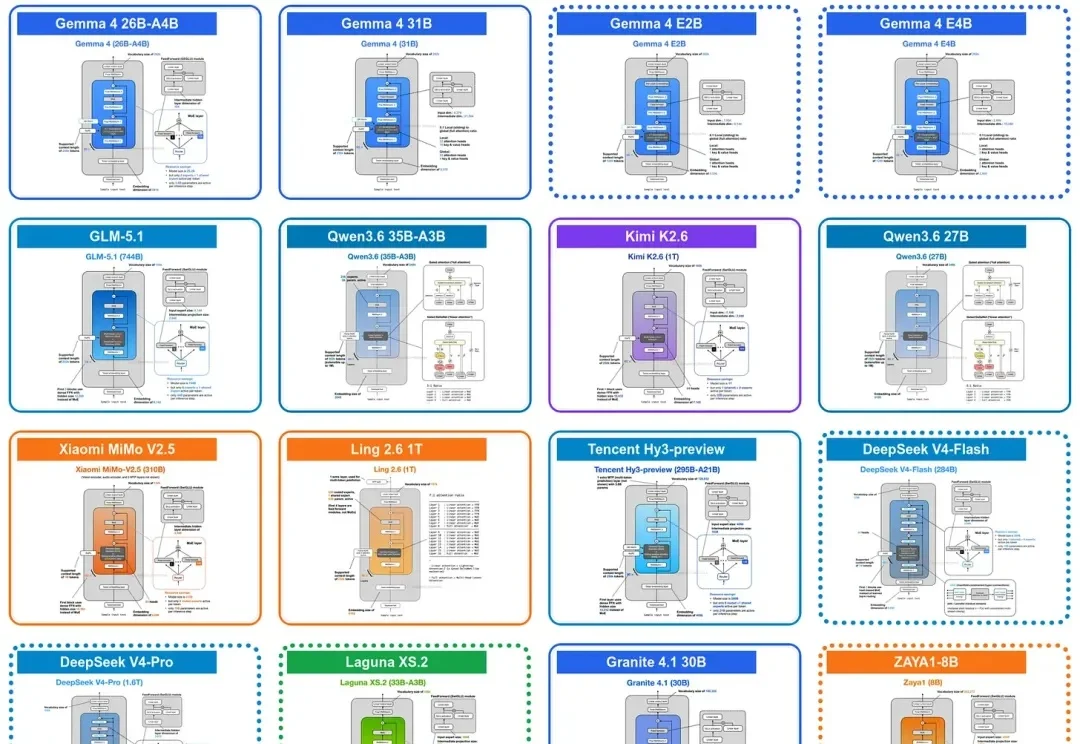
LLM近期重大架构进化一览:从Gemma 4到DeepSeek V4
LLM近期重大架构进化一览:从Gemma 4到DeepSeek V4过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
来自主题: AI技术研报
7829 点击 2026-05-19 15:32
 搜索
搜索
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。

你是否在使用Agent工作或者写代码时,总感觉上下文不够用?或者感觉反复使用Agent时并没有变得更聪明?感觉目前的记忆方案仍然不够用?今日,香港中文大学联合浙江大学发布的一篇论文关注了这个问题,并引起了学术界广泛讨论:你以为Agent在「记忆」,其实只是在记备忘录。
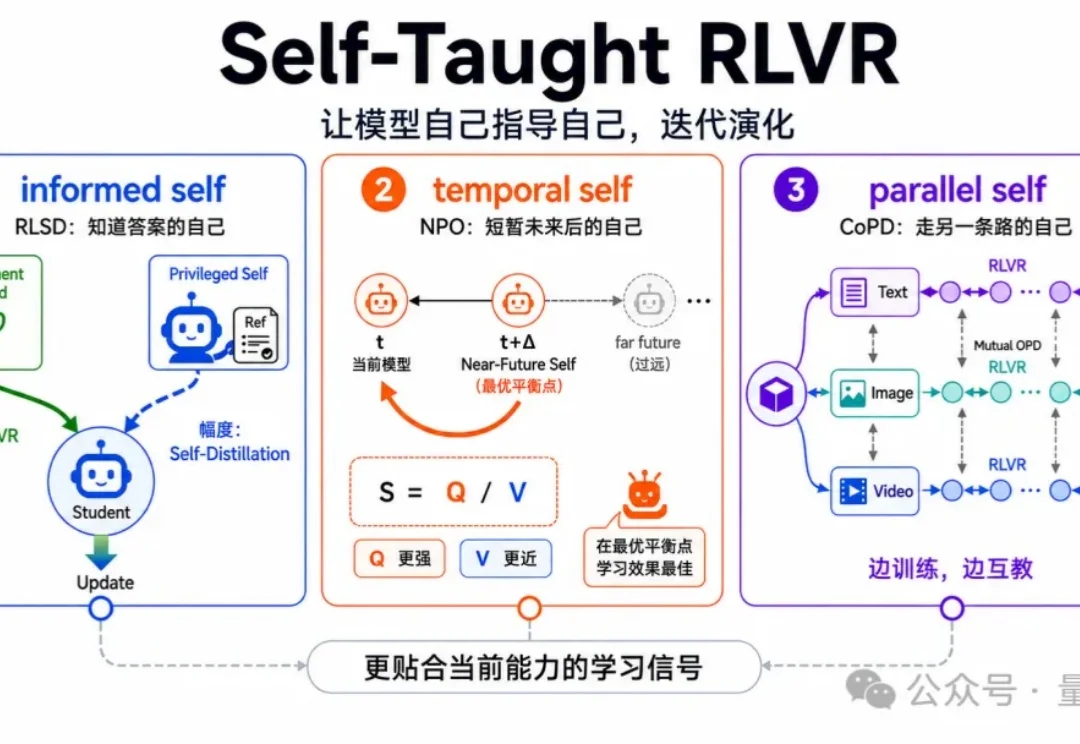
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。
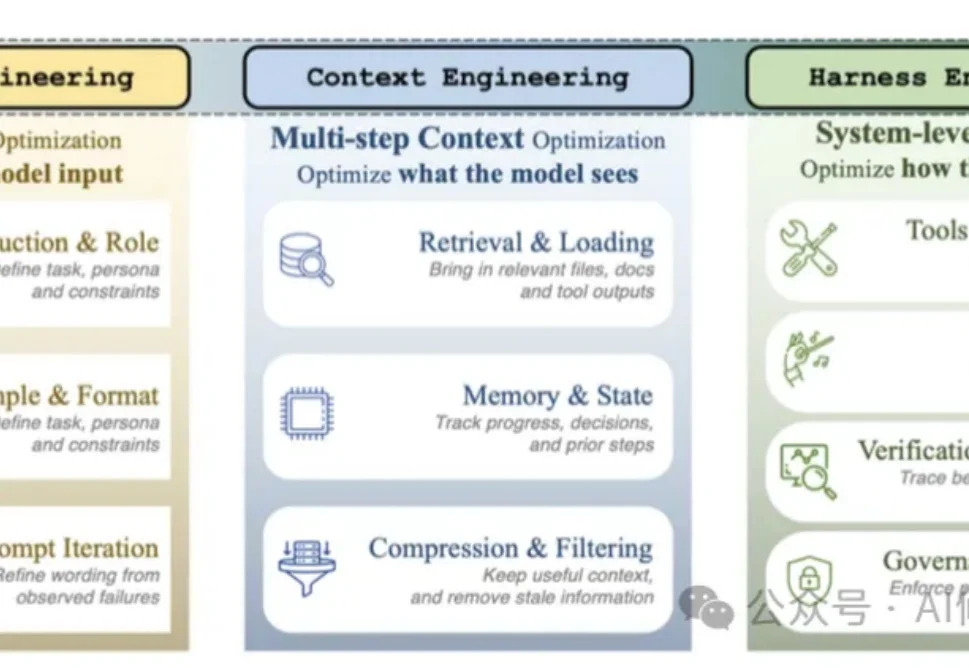
经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。
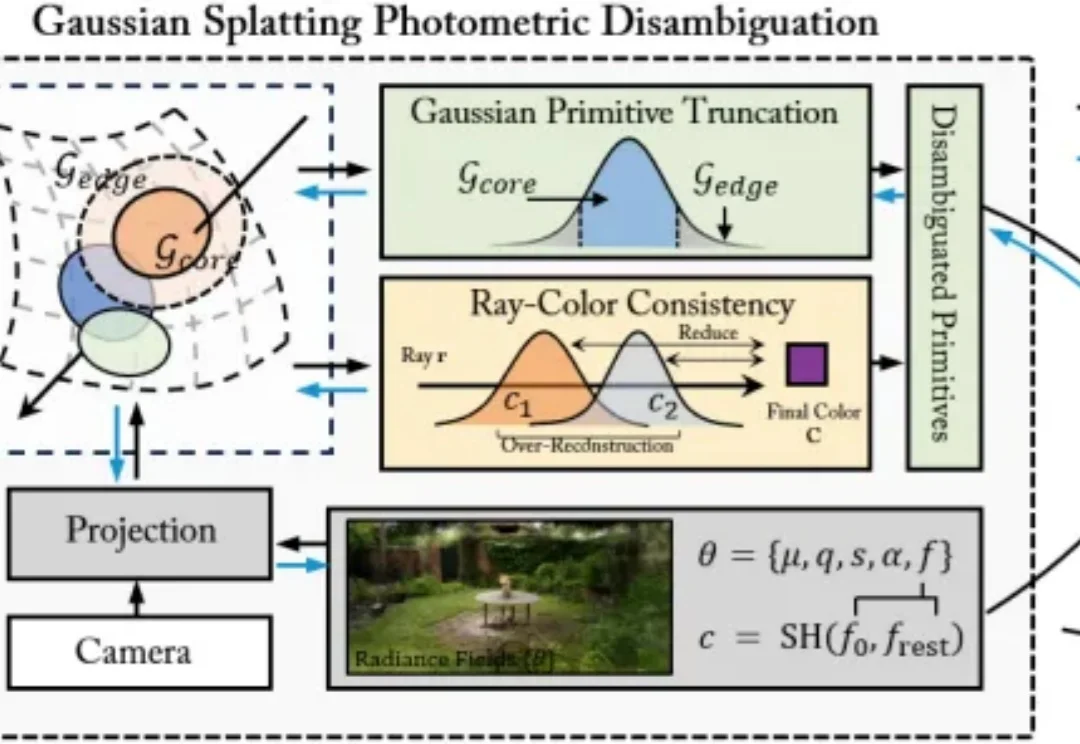
近年来,3D 高斯泼溅(3D Gaussian Splatting, 3DGS)凭借其卓越的新视角合成能力和实时的渲染效率,极大地推动了神经渲染技术的发展。然而,当研究者试图直接从 3DGS 中提取精确的 3D 几何表面(Mesh 等)时,往往会面临严重的几何失真问题。

最近一段时间,Agent 又一次成为 AI 圈最热的关键词。

全行业都在押注多Agent。
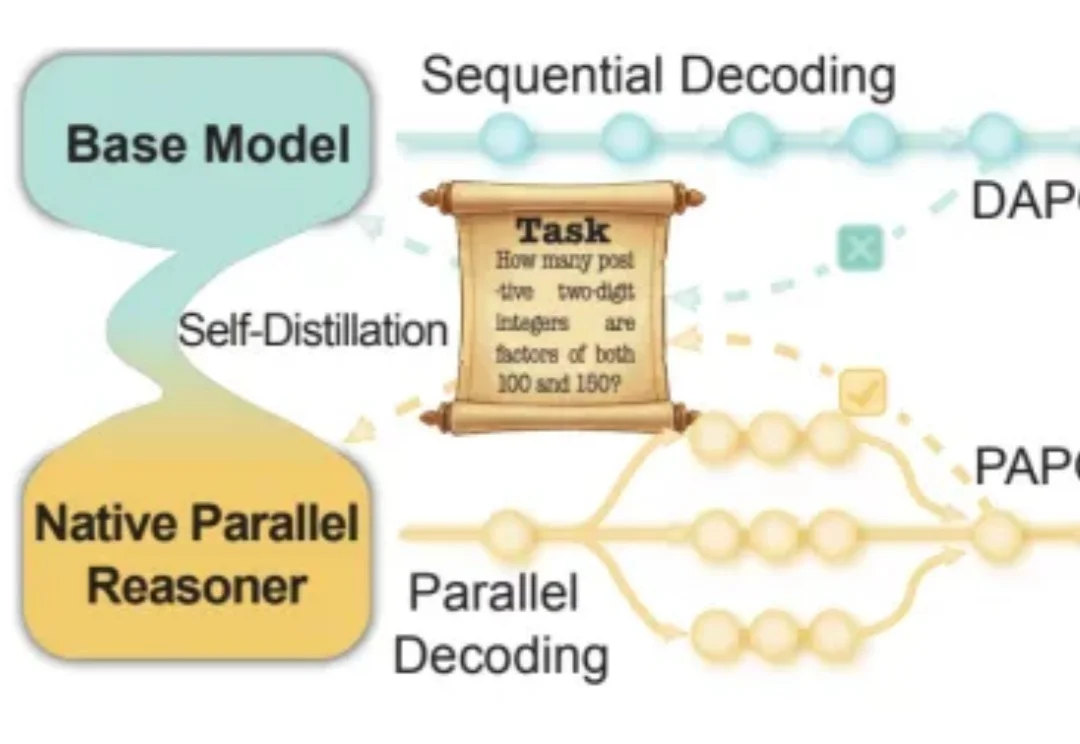
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。