
Agent学会自己「长」Skill了!从失败里长出经验,比人类写的更好用|ICML 2026
Agent学会自己「长」Skill了!从失败里长出经验,比人类写的更好用|ICML 2026过去一年,Agent学会了两件事:会用工具、会调用Skill。
来自主题: AI技术研报
9469 点击 2026-05-19 10:00
 搜索
搜索
过去一年,Agent学会了两件事:会用工具、会调用Skill。
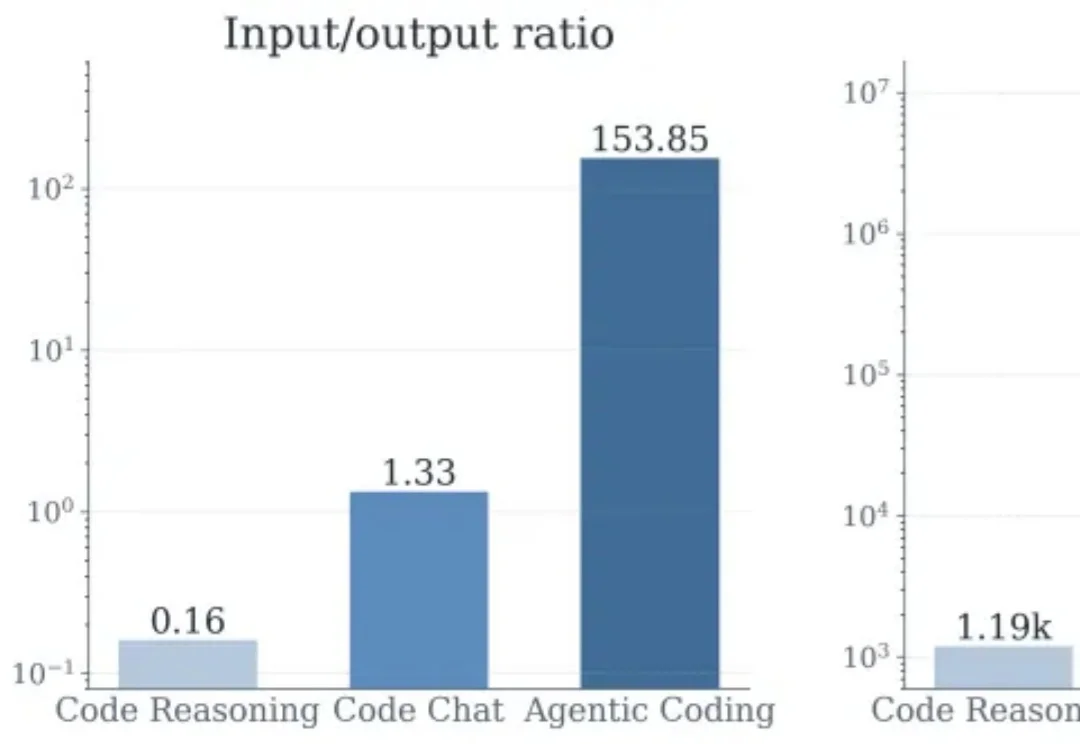
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
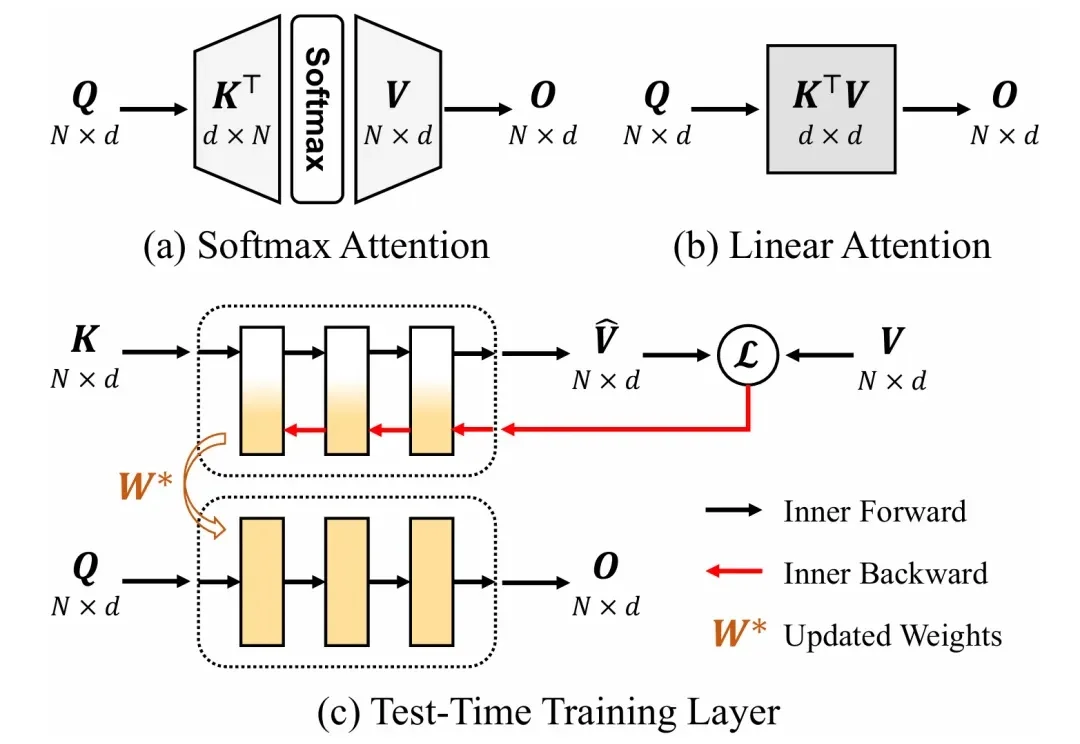
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
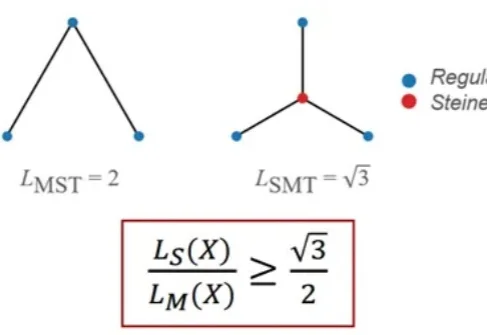
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
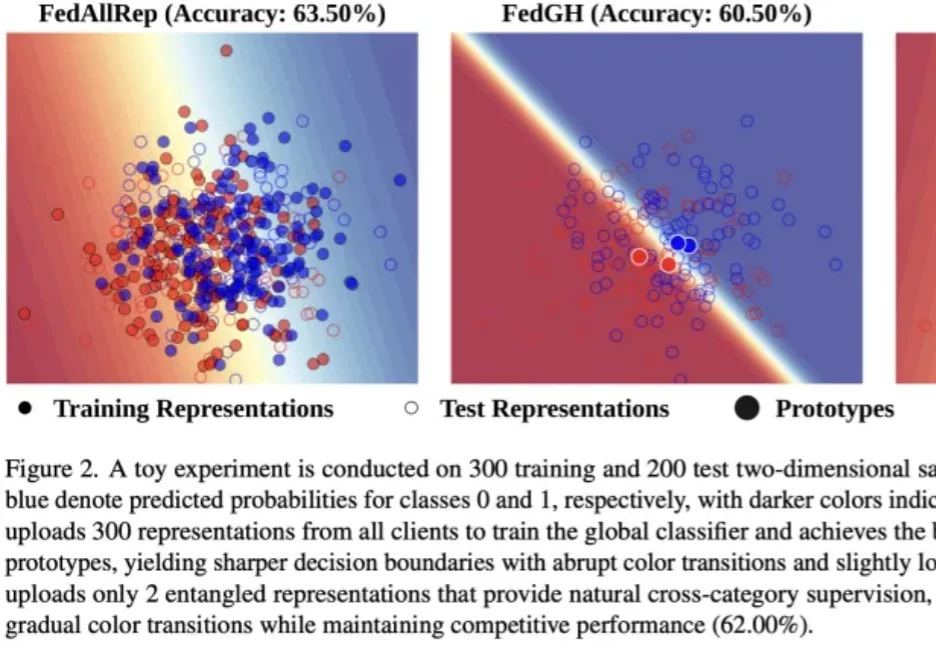
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
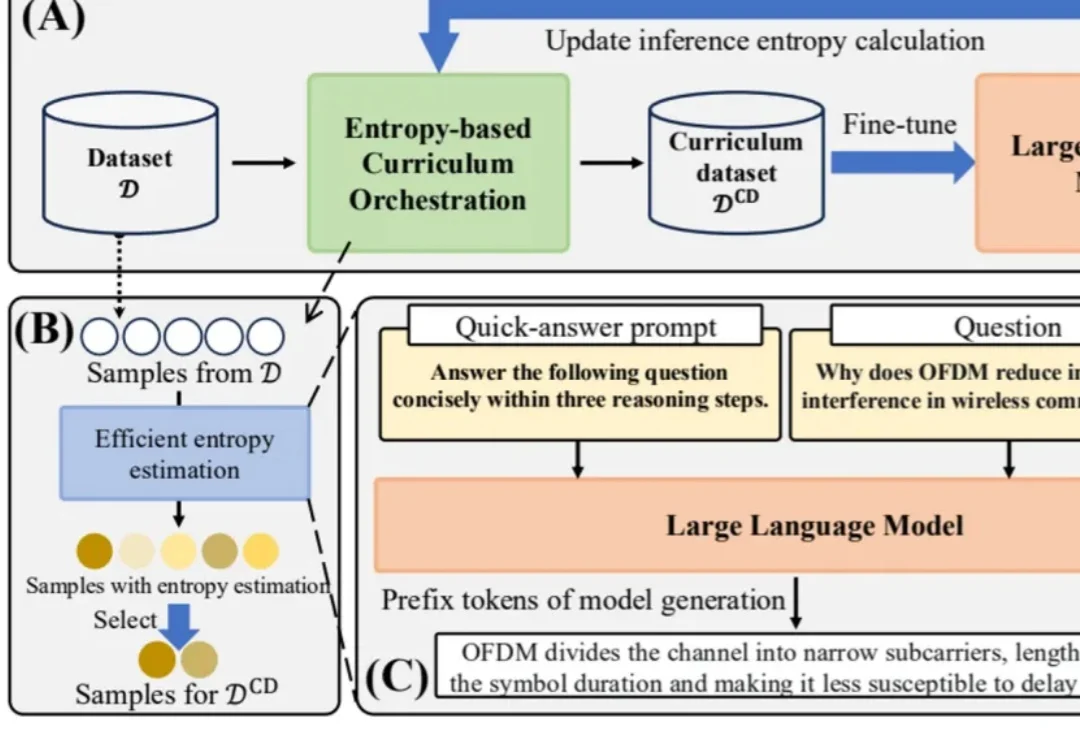
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
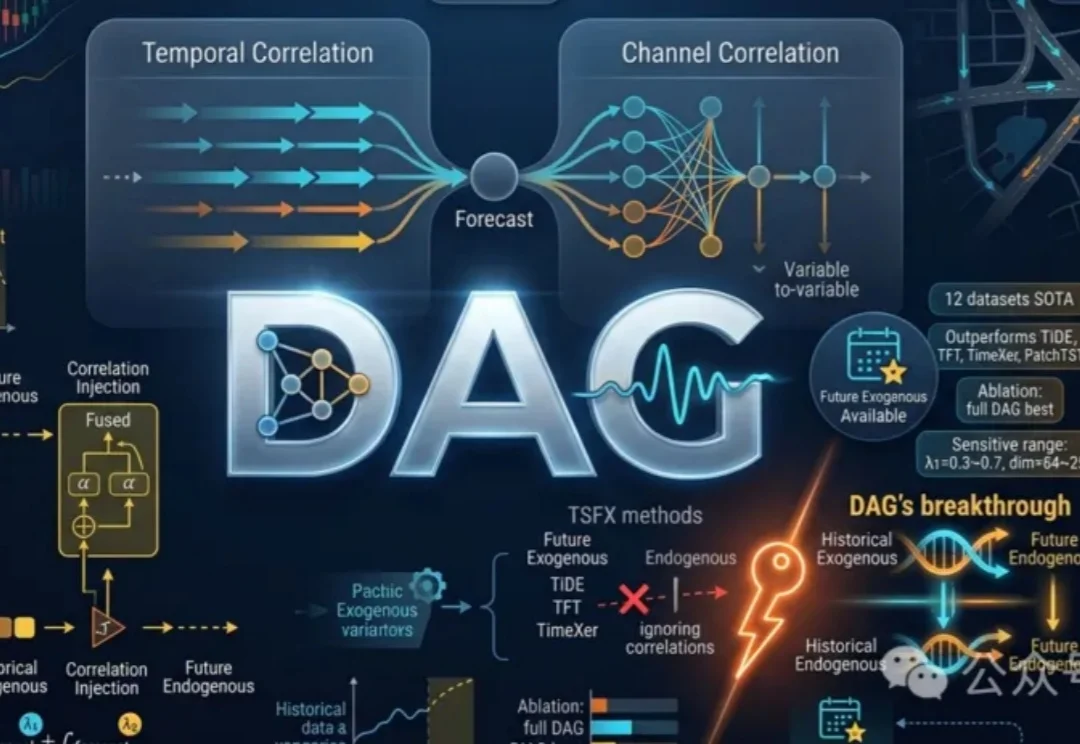
DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
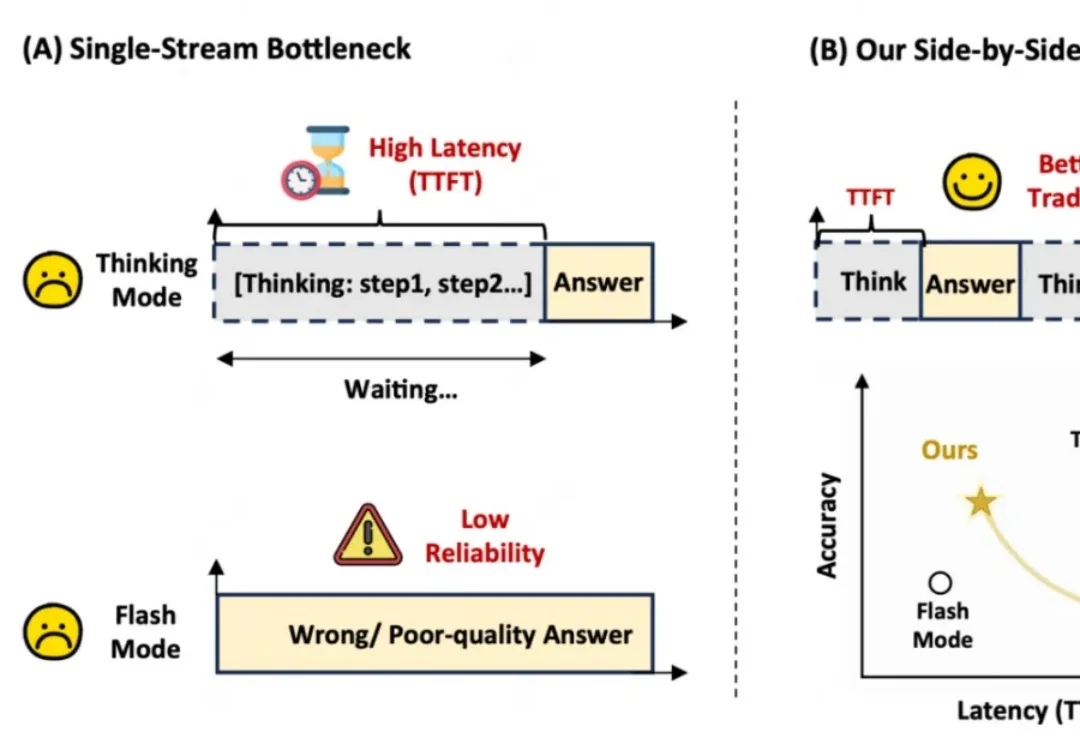
用过推理型大模型的人,大概率都熟悉这种体验:模型似乎在认真思考,但屏幕上长时间没有真正有用的内容;如果让它一开始就输出,又很容易出现仓促判断,后面的推理还要被早期错误牵着走。
早在2024年,人们还倾向于给Agent提供海量的工具(例如通过MCP协议连接的API、搜索引擎、代码解释器等)。但是,“拥有工具”并不等于“知道如何使用工具”。当任务变得复杂且长周期时,要求Agent每次都从头开始推理“该用哪个工具、何时用、怎么组合、出错怎么办”,会导致系统极度脆弱、延迟极高且不可靠。
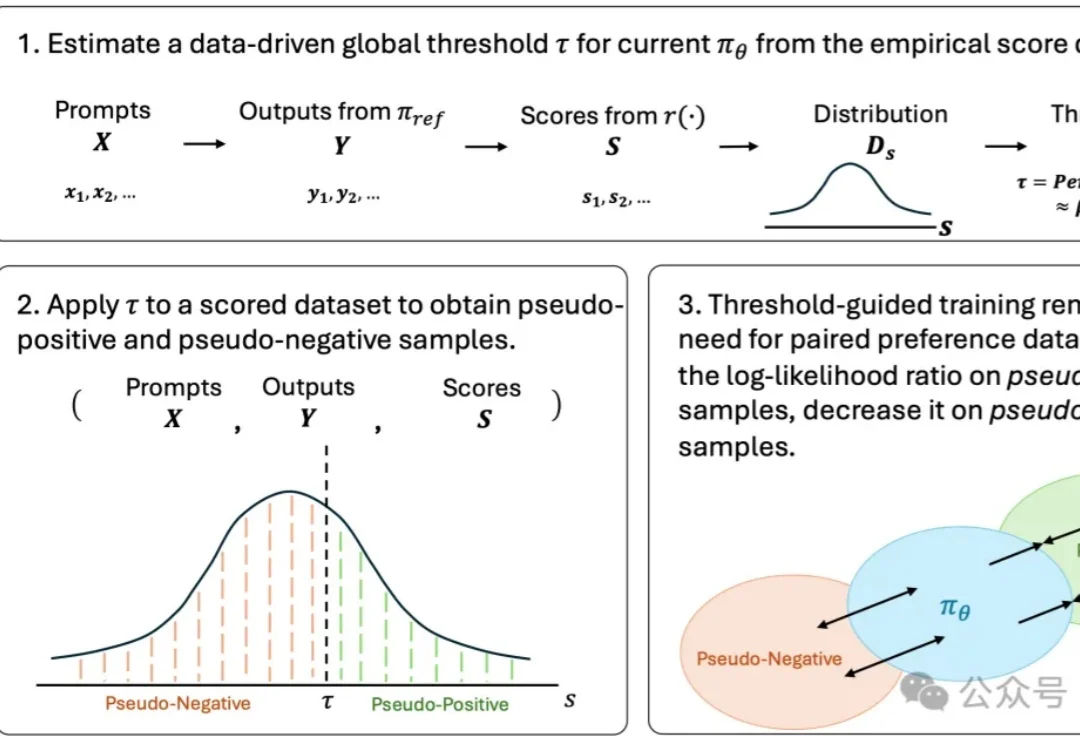
生成模型的偏好对齐,可能正在进入一个新的阶段。