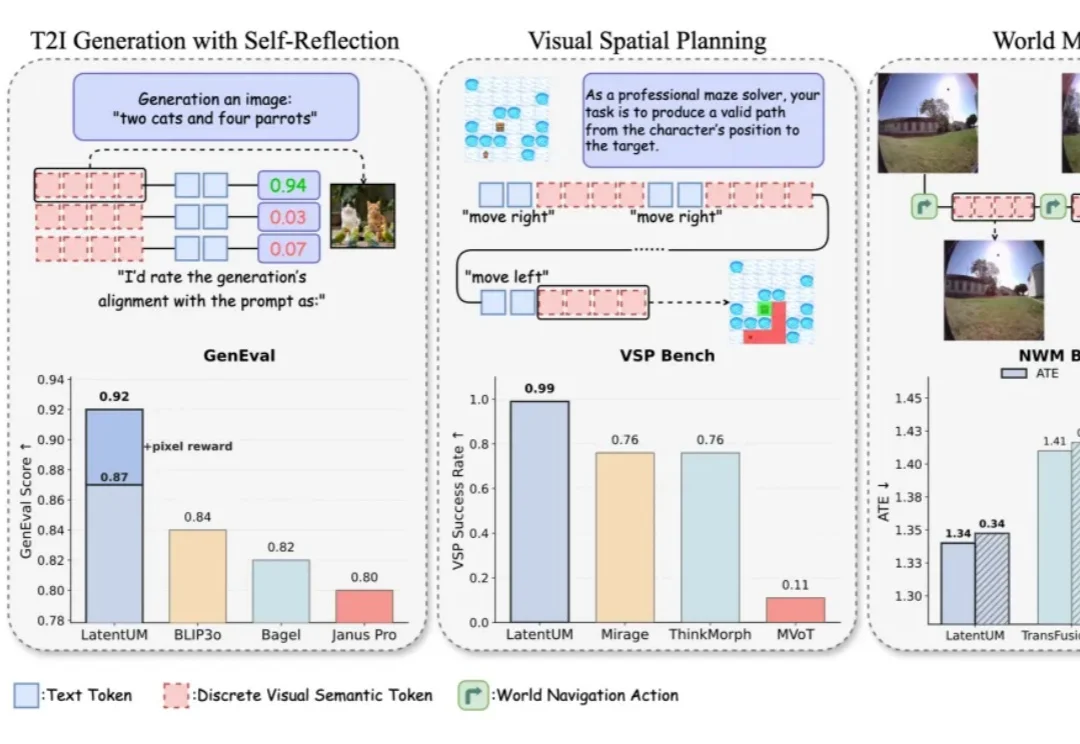
上海交大DENG Lab提出「LatentUM」:Unified Model的真正「战场」在视觉推理与世界模型
上海交大DENG Lab提出「LatentUM」:Unified Model的真正「战场」在视觉推理与世界模型过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。
来自主题: AI技术研报
8882 点击 2026-04-14 08:42
 搜索
搜索
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。
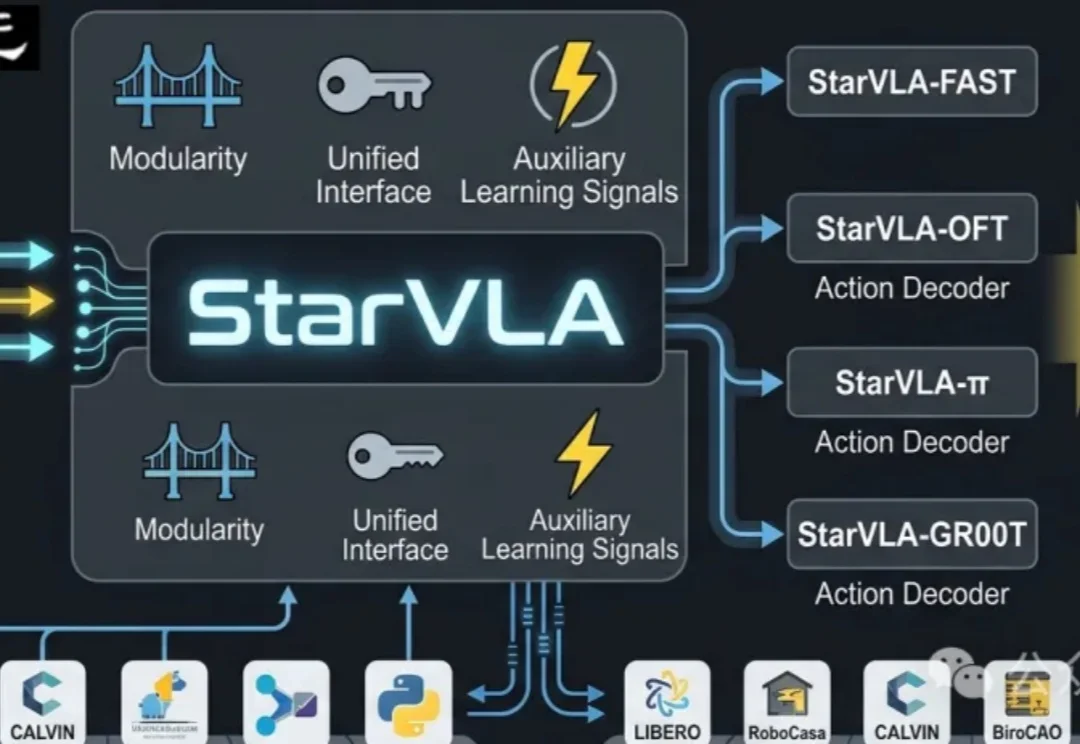
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
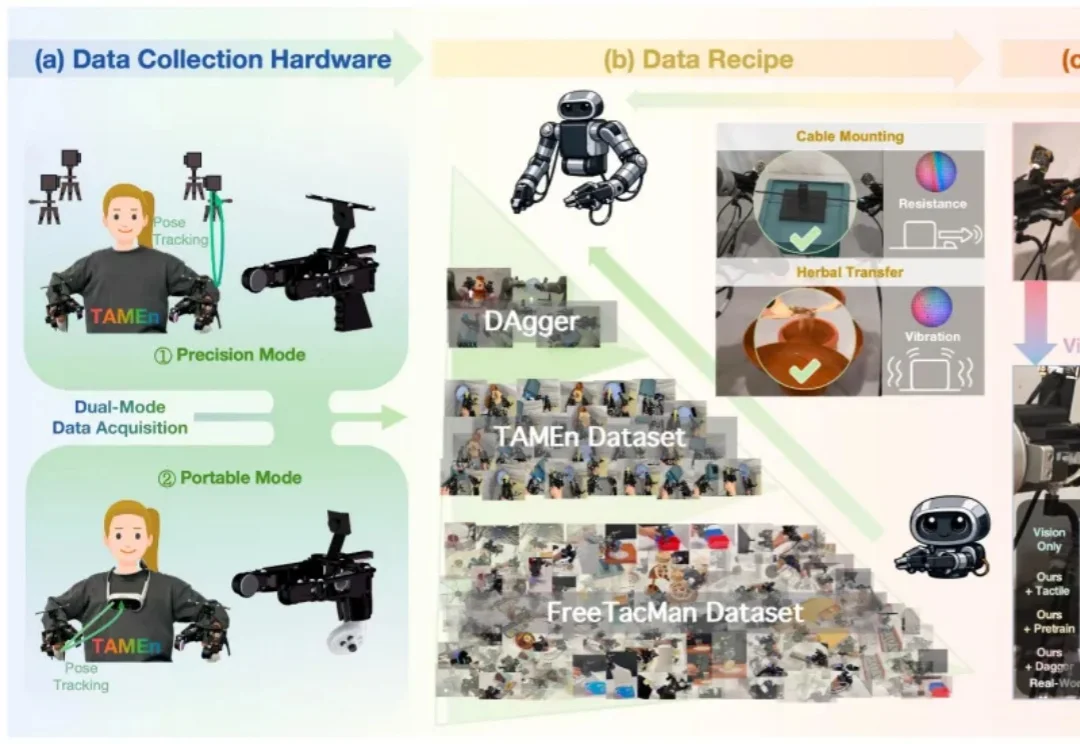
在具身智能快速发展的今天,高质量数据已成为驱动能力提升的关键基础,然而一个核心问题也随之而来: 如何让机器人数据采集更快、更稳、更有效?

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。

随着任务的复杂度提升,Agent(智能体)的上下文在无限膨胀。在无穷的历史对话、工具调用输出、中间步骤以及报错信息中,模型迷糊了,于是开始跳步、忽视、绕道。
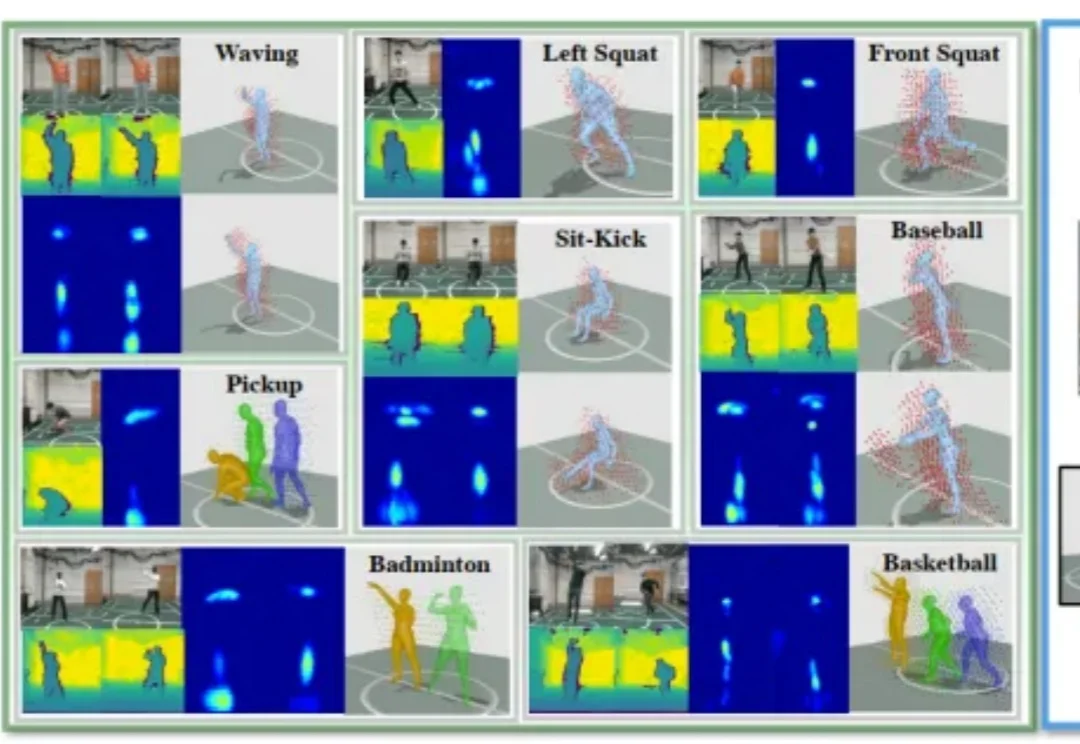
想象几个并不遥远的场景: 医院的病房里,刚做完手术的患者正在练习下床、走动,智能系统通过摄像头捕捉他的动作,判断步态是否稳定、有没有跌倒风险;回到家,在卧室或浴室这样私密的空间里,老人起身、转身、洗漱,甚至意外滑倒的瞬间,也可能被视觉传感器记录,只为了让 AI 能更早发现异常;

在本文中,我将探讨编码智能体(coding agents)及其智能体编排(agent harnesses)的整体设计:它们究竟是什么、工作原理如何,以及在实际应用中各组件是如何协同运作的。

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
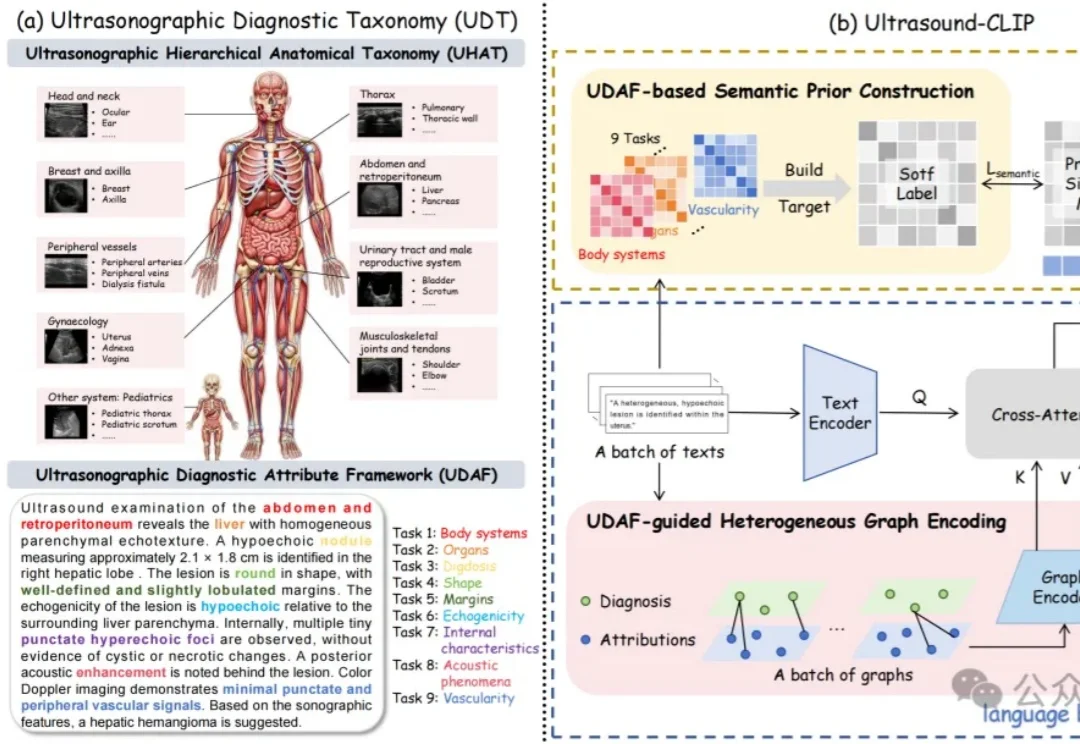
超声领域也有大模型了!
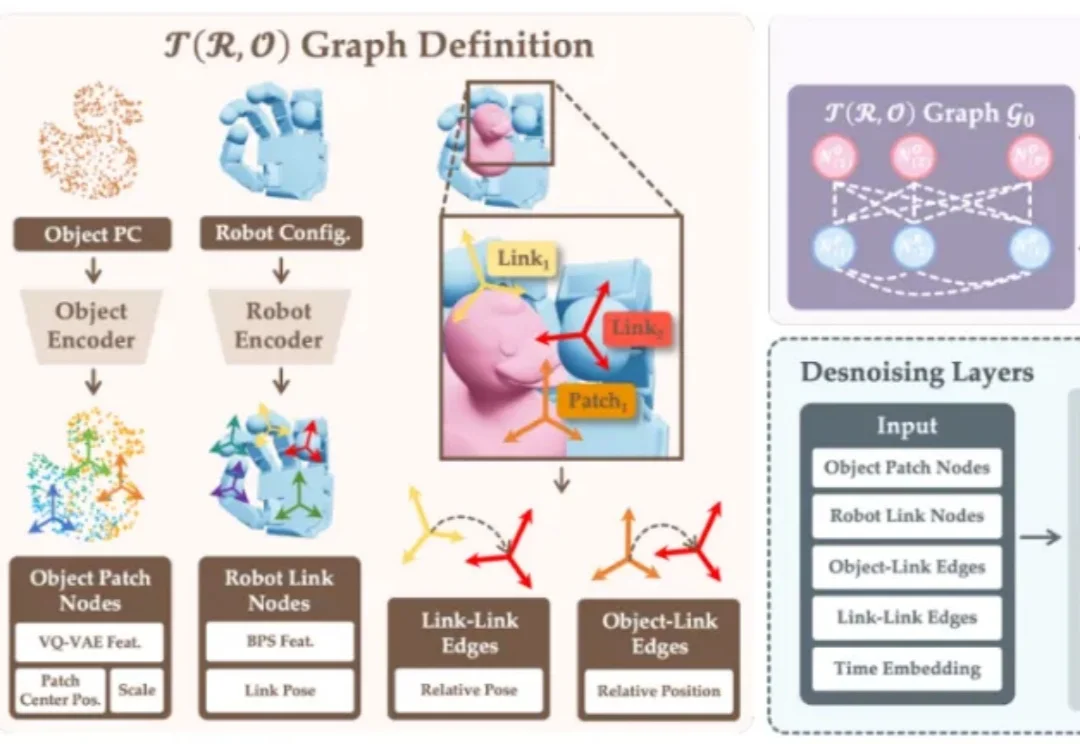
T (R,O) Grasp 是一种基于物体 — 机器手空间关系建模的图扩散架构,具备跨智能体的统一表征能力。在 NVIDIA 40GB A100 GPU 上,该方法可实现 5 FPS 的推理速度和 50 grasp/s 的吞吐量,并在多种智能体上取得 94.83% 的平均抓取成功率,刷新了跨智能体灵巧抓取的 SOTA,具备与动态场景实时交互的能力。