警惕!大模型成本倒挂:你正在为模型的多余「思考」买单
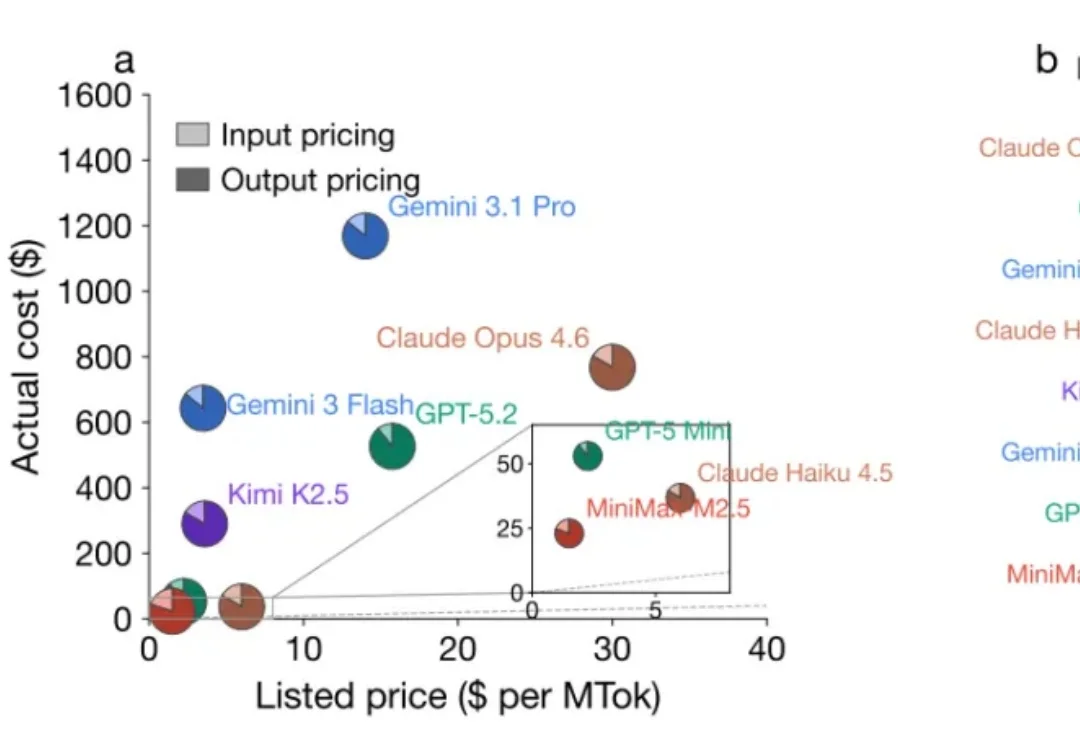
警惕!大模型成本倒挂:你正在为模型的多余「思考」买单在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?
来自主题: AI技术研报
6568 点击 2026-04-15 09:45
 搜索
搜索
在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?

代码大模型会写代码,这件事已经不新鲜了。

小红书AI平台团队刚刚开源了Relax——一个为全模态数据、Agentic工作流和大规模异步训练协同设计的现代RL训练引擎!实测全异步Off-Policy模式相比共卡On-Policy吞吐提升76%,相比veRL的全异步实现提升20%!

试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?

南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。

文本驱动的人体动作生成是游戏NPC、虚拟主播、机器人控制等实时交互系统的核心技术。

2026年再看Agent,一个越来越难回避的事实是:能力正在从模型里流到模型外。真正决定系统上限的,不再只是参数、Prompt和tool calling,而是记忆、技能、协议以及统摄这一切的harness。

随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。

太疯狂了!Meta和METR刚测出的AI进化数据,与中国团队两年前提出的「密度定律」完美重合。硅谷猛然回头,发现中国研究者在这条路上已领先两年!

Google DeepMind调查了一万个人,结果让整个AI安全评估体系汗颜:AI做了三倍多的「坏事」,但造成的实际伤害几乎一样。这意味着,我们现在用来证明AI安全的那套逻辑,可能从一开始就是错的。