让机器人学会手往哪儿伸、怎么操作,东大团队给了新解法
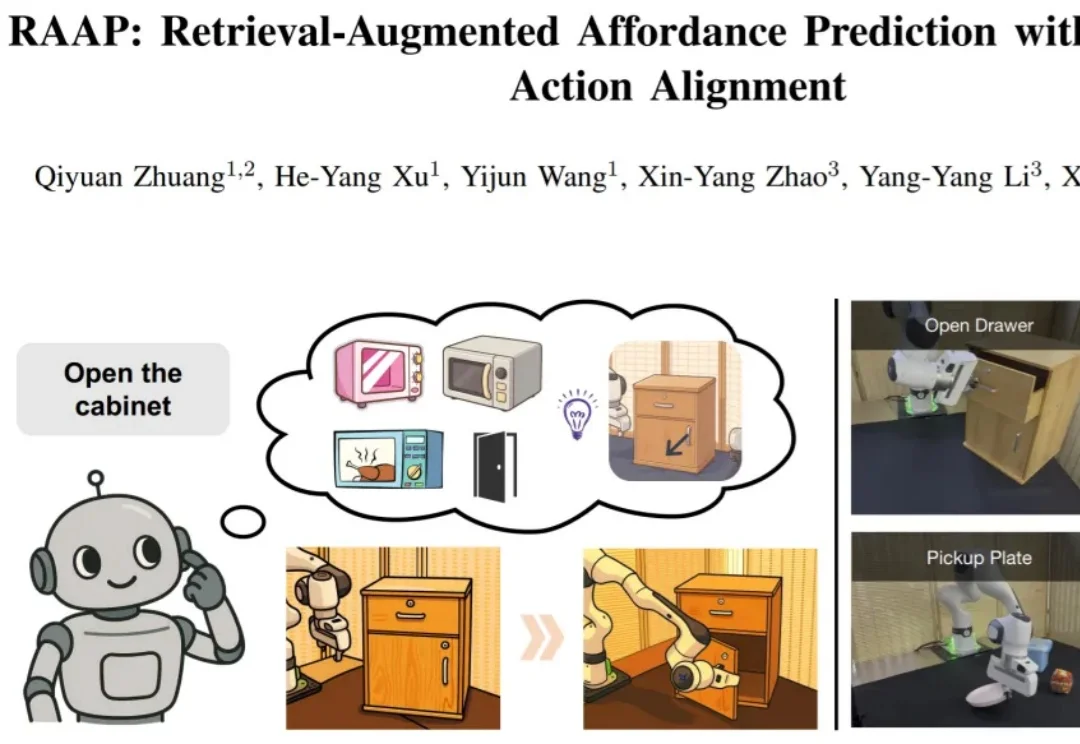
让机器人学会手往哪儿伸、怎么操作,东大团队给了新解法在具身智能领域,可供性(affordance)预测 —— 即让机器人从视觉观测中理解 "在哪里操作"(接触点)与 "如何操作"(动作方向)—— 是实现精细化机器人操作的基础之一。精细操作要求机器人不仅能定位到物体的可交互区域,更要掌握接触后的准确运动方向,例如判断抽屉把手的精确拉动方向完成开合。
来自主题: AI技术研报
9319 点击 2026-04-09 09:47
 搜索
搜索
在具身智能领域,可供性(affordance)预测 —— 即让机器人从视觉观测中理解 "在哪里操作"(接触点)与 "如何操作"(动作方向)—— 是实现精细化机器人操作的基础之一。精细操作要求机器人不仅能定位到物体的可交互区域,更要掌握接触后的准确运动方向,例如判断抽屉把手的精确拉动方向完成开合。
大模型(LLM)的世界知识和推理能力是实现下一代推荐系统,即基于大模型的推荐系统(LLM4Recsys)的重要基石。来自meta ai的研究者们尝试将推理模型引入再排序阶段,推荐系统的最后一环。

Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?
大模型正在批量生成「看起来很像真的」学术论述,但这些论述背后的引用,真的成立吗?更关键的是:当被引论文被付费墙锁住、原文根本读不到时,自动化核验是否就注定失效?
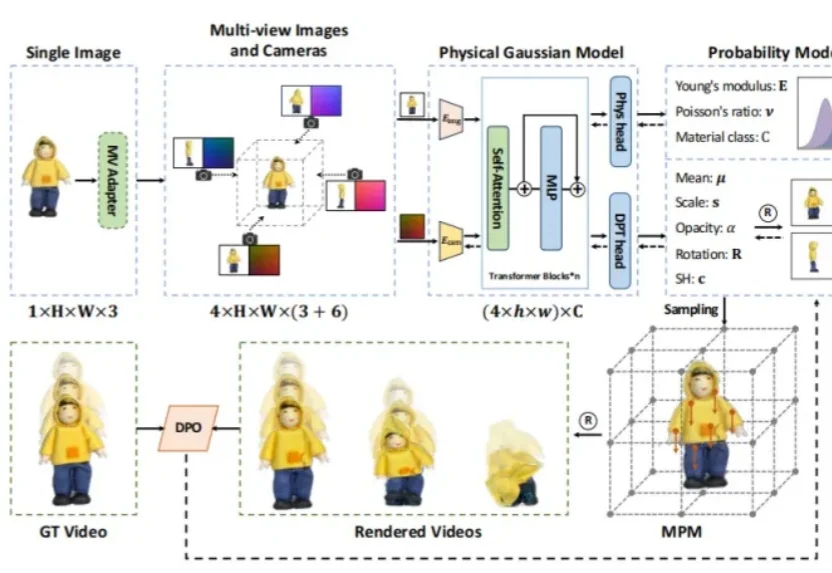
让静态的图片变成三维物体并动起来已经不算新鲜,但如果让图片不仅动起来,还能完美遵循现实世界的物理规律(比如蛋糕的Q弹、沙堆的散落、石雕的坚硬)呢?

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
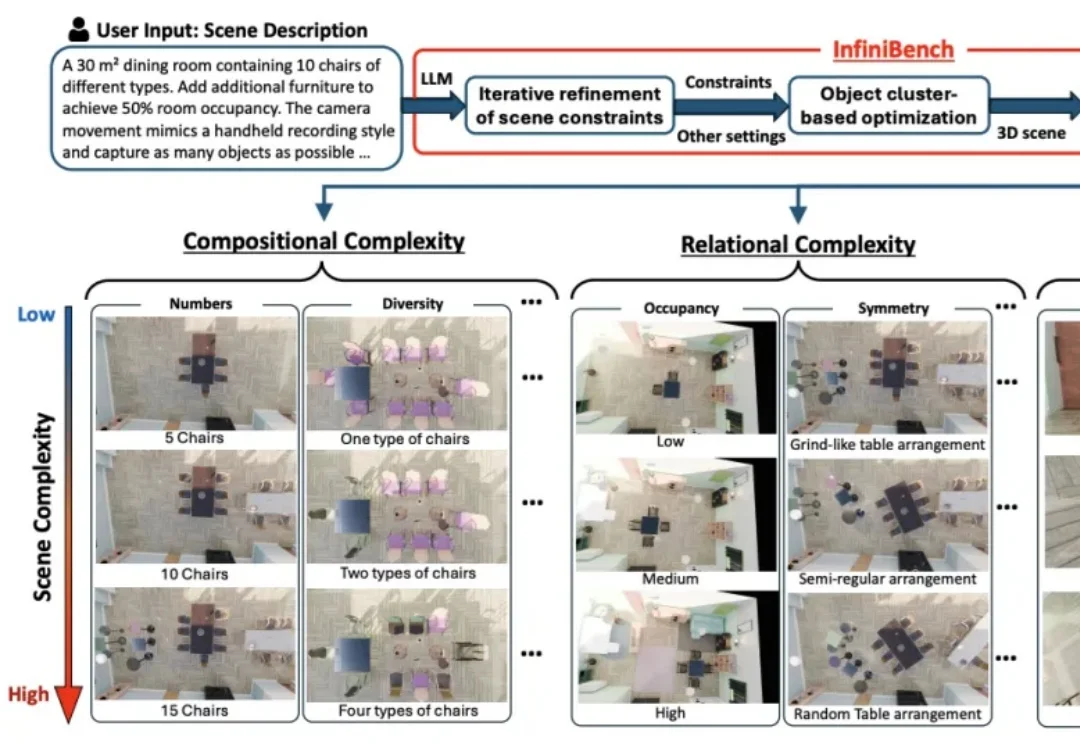
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。
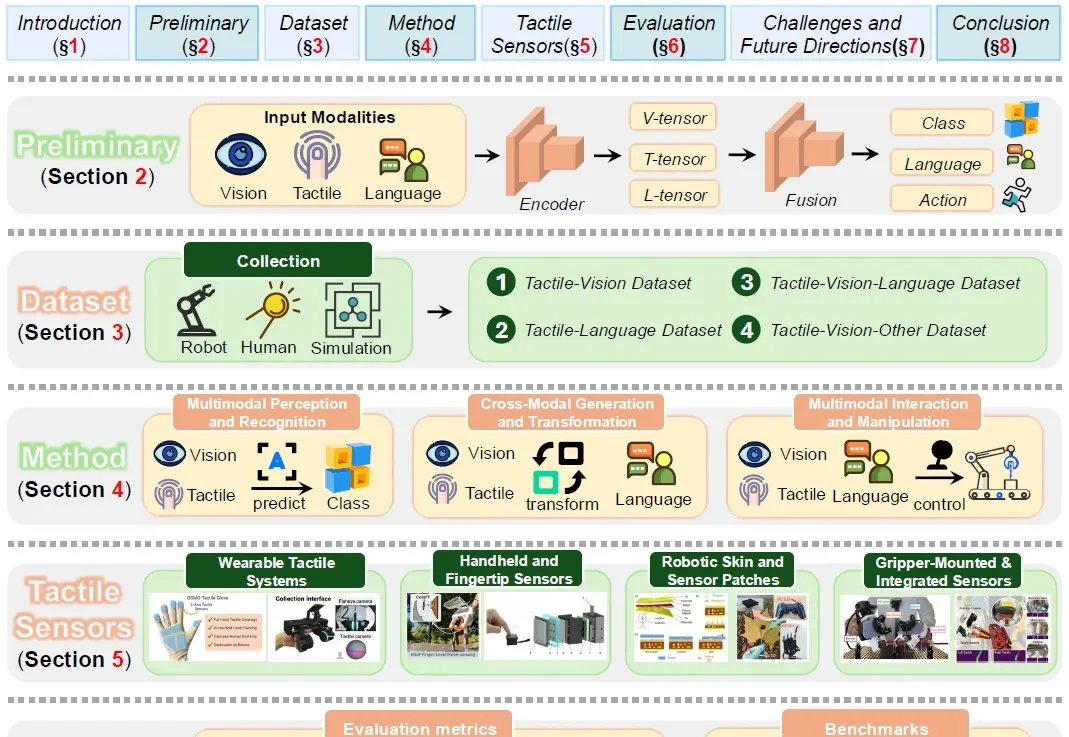
在具身智能的感知拼图中,触觉一直扮演着不可或缺却难以被完美量化的角色。它提供了视觉等远程传感器无法替代的关于接触几何、材料特性和交互动态的直接反馈。

Anthropic杀疯了!开年第一篇论文直接化身自爆卡车,实锤AI正在让程序员变傻。你以为效率提高了?其实只快了2分钟。