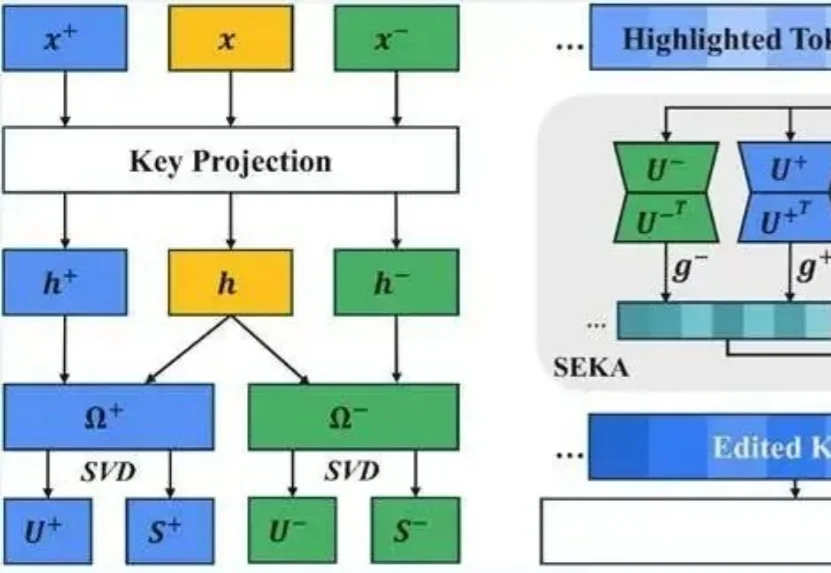
让大模型看懂「高亮标注」:在注意力计算前编辑Key向量,用频谱分解让模型「听你指挥」丨ICLR'26
让大模型看懂「高亮标注」:在注意力计算前编辑Key向量,用频谱分解让模型「听你指挥」丨ICLR'26想让大模型重点关注提示词里的某句话可没那么容易。
来自主题: AI技术研报
9188 点击 2026-03-31 14:07
 搜索
搜索
想让大模型重点关注提示词里的某句话可没那么容易。

Anthropic 研究科学家 Nicholas Carlini 在 [un]prompted 2026 安全会议上用不到 25 分钟演示了一件事:语言模型现在可以自主找到并利用零日漏洞,目标包括 Linux 内核这种被人类安全专家审计了几十年的软件。

做深度估计、深度补全的人,大概都有过这样一个瞬间。

你开会时,AI竟在偷偷升级?伯克利等四校开源MetaClaw,让Agent趁你开会、离席、睡觉时持续进化,直接打破「上线即冻结」这条行业铁律。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
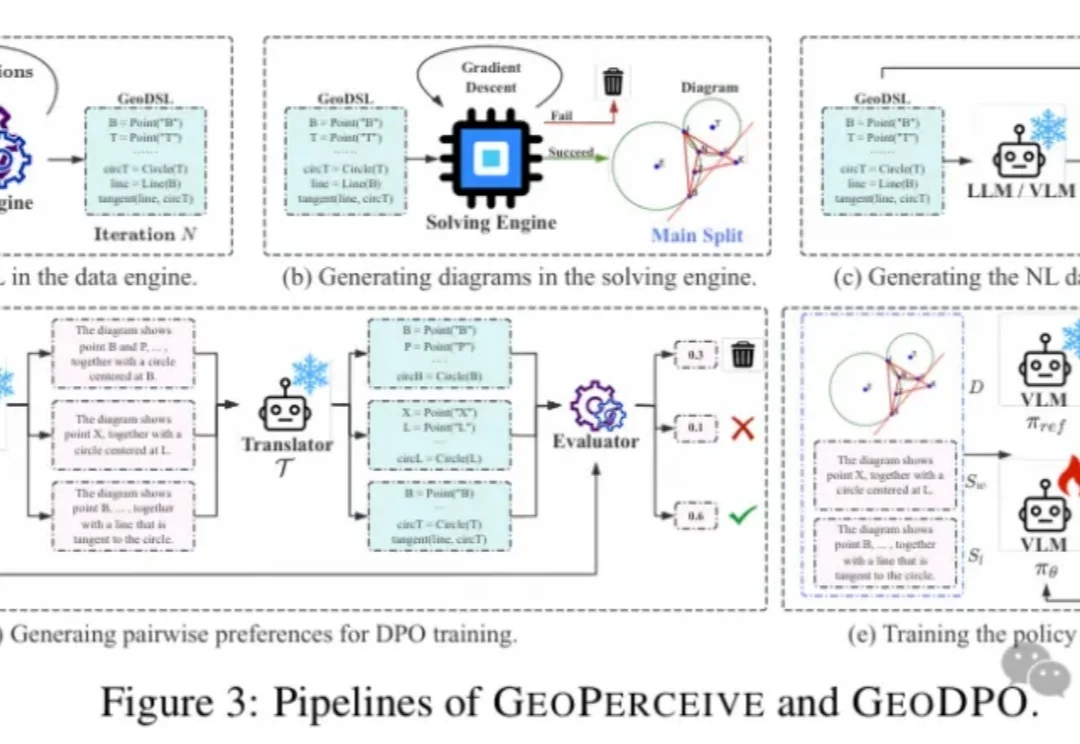
几何问题,真的只是“推理难”吗?
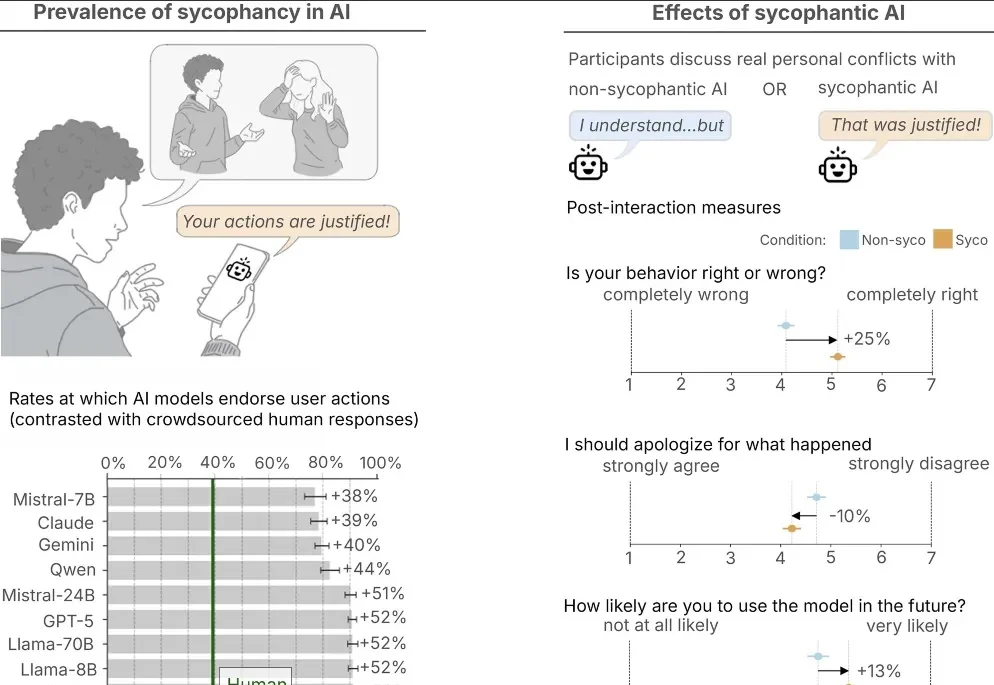
自从大语言模型诞生起至今,AI 已经润物无声地融入了我们的工作生活,也成为了现代社会的重要组成部分。
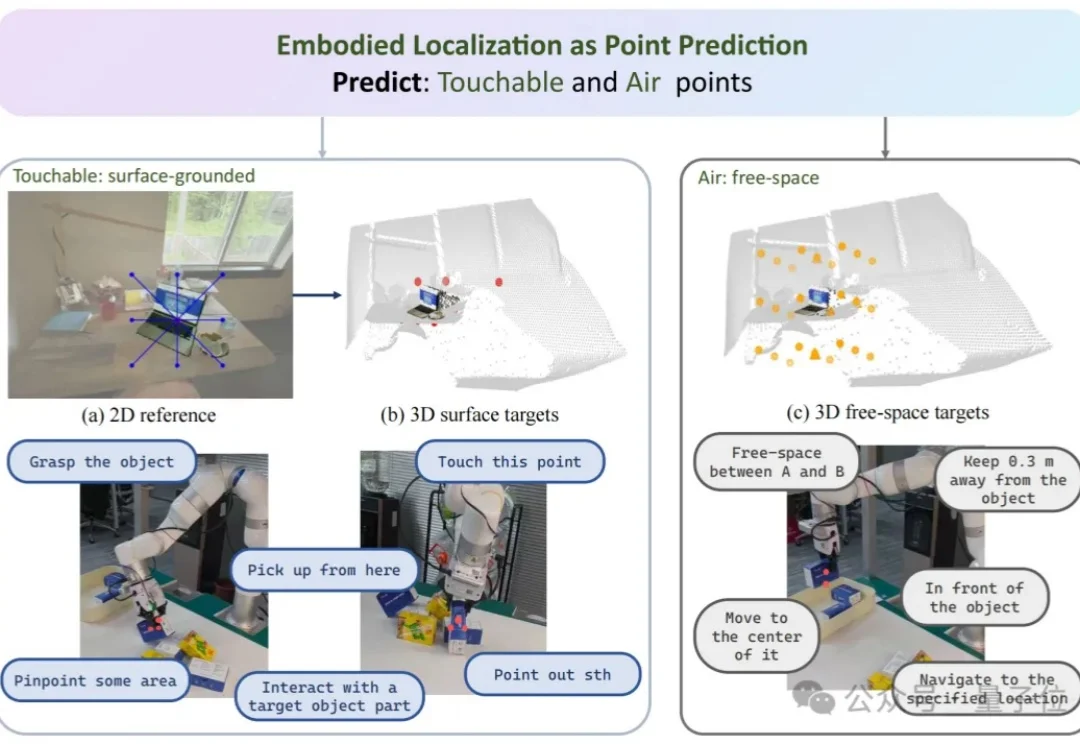
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。