# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。
近年来,随着 DeepSeek-R1 等推理模型出现,基于可验证奖励的强化学习(RLVR)已成为提升数学、代码能力的重要训练范式。其核心思想在于:对同一道题采样多条推理路径,并根据奖励信号,强化正确路径、抑制错误路径。这就像让模型对同一道题写出多份解题草稿,再从中学习哪些思路更值得保留。
一种直观想法是 :如果采样轨迹(rollout)足够多,模型就总能探索出更多解法,获得更有效的更新信号?然而,在实际训练中,盲目增加采样数量并不一定带来更高效的探索。这背后对应着强化学习中的经典探索 - 利用困境(exploration-exploitation trade-off):模型既要利用可验证奖励,强化当前更容易得到正确答案的推理模式;又要保持探索能力,跳出已有模板,尝试新的解题方向。
当前的 rollout 采样机制天然偏向 “利用”:模型很快收敛到少数高概率推理模板,生成的轨迹虽然措辞不同,底层逻辑却高度同质化。这种同质化推理削弱了轨迹间的奖励差异和优势信号,使额外采样也难以带来有效更新。

表 1: 高熵 Token 类别示例
熵,作为衡量模型在生成下一步时不确定性的指标,天然指向探索的关键节点。通过系统实验,我们发现:策略熵往往与逻辑转折、自我纠错等行为高度相关(如表 1 所示),是引导模型探索的有效信号。
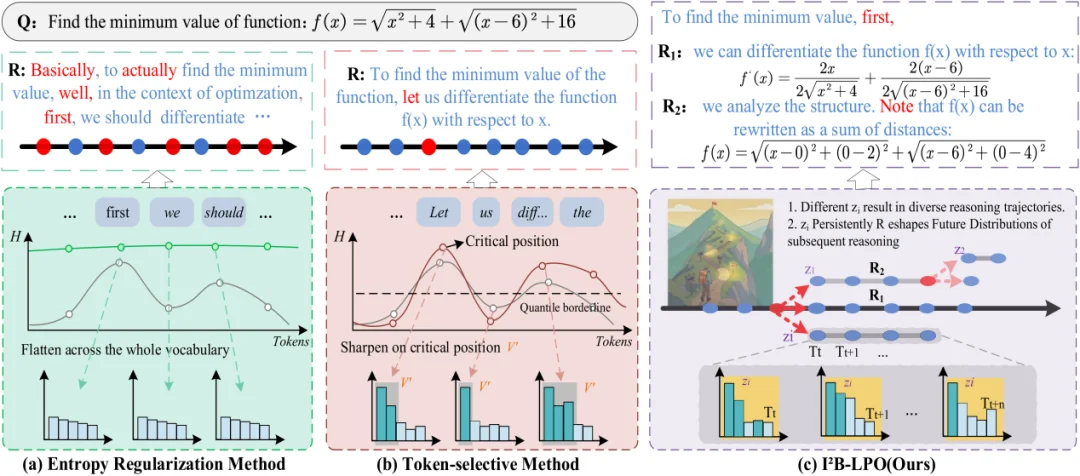
图 1:RLVR 中不同探索范式的对比(a)Sequence-level 的整体正则化方法通过全局平滑 token 分布来提高熵,但容易让模型生成冗长、重复或与解题无关的内容,形成 “高熵但低信息量” 的无效探索。(b)token-level 的概率扰动方法则只在局部高熵 token 上调整概率,往往只能带来连接词、同义词或表层表达的变化,也难以突破预训练模型已有的推理偏好来持续改变后续推理方向。
然而,在实践中我们发现,在高熵节点仅仅依靠 sequence-level 的整体正则化或 token-level 的概率扰动,无法持续影响后续推理轨迹的整体走向。如图 1 所示,基于熵的强化学习方法存在以下关键问题:
为了解决这些问题,我们提出 I²B-LPO:在高熵节点向模型注入潜变量分支,以确保在模型在关键节点生成更具区分度的推理轨迹,并引入一种反馈机制,滤除冗长和无意义的推理路径。这一方法帮助 RLVR 在有限推理资源下实现更高效的探索,进一步突破大模型的推理性能瓶颈。

本文提出一种面向 RLVR 后训练的探索增强框架,鼓励模型在关键节点生成更具区分度的推理轨迹。具体而言,I²B-LPO 通过改进 rollout 策略,使模型在有限采样预算下获得更有效的探索信号,显著提升了数学推理任务中的准确率与语义多样性。
理论与现象分析:
1. 高熵节点是真正的推理分叉点: 我们按 token-level entropy 对推理过程进行分组实验,发现模型处于高熵区间时,不同解码策略的性能差异明显放大;而在低熵区间,这种差异并不显著。这说明高熵位置往往对应关键决策点,更适合作为推理轨迹的分支位置。
2. 推理长度不等同于有效推理: 在标准 GRPO 训练中,我们观察到:模型准确率较早进入平台期,但响应长度和 4-gram 重复率仍持续上升。这表明模型可能只是在生成更长、更重复的内容,而不是产生更有效的推理。因此,有效探索不仅要生成更多路径,也要识别真正有信息量的路径。
核心创新:
I²B-LPO: 我们提出了一种面向 RLVR 后训练的探索增强框架,结合熵驱动的推理轨迹分支和信息瓶颈自奖励机制,在 Qwen2.5-7B 和 Qwen3-14B 模型上验证了其有效性。
验证与结果:
我们基于 GRPO 框架,在多个数学推理基准上对 I²B-LPO 进行了验证。结果显示,I²B-LPO 同时提升了推理准确率与语义多样性,在保证探索多样性的同时避免了过度冗长。
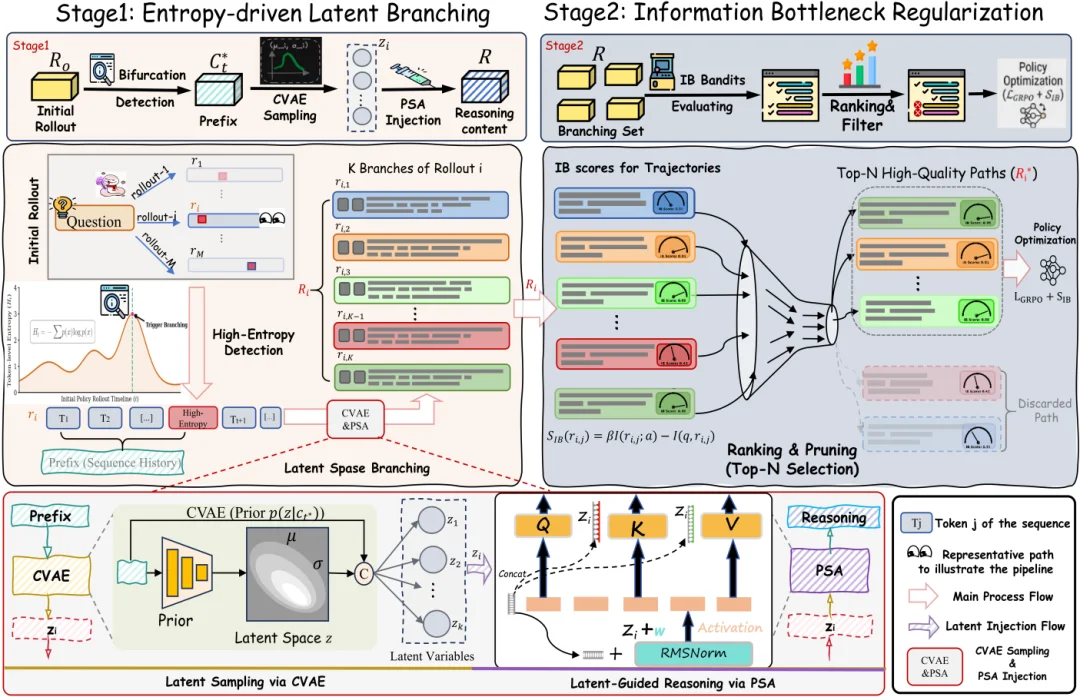
图 2: I²B-LPO 将 rollout 从 “随机多采样” 改造成 “关键节点分支 + 高质量路径筛选” 的结构化探索过程,使模型既能探索不同解题方向,又能避免无效发散。
I²B-LPO 并不替换原有 GRPO 训练框架,而是改进其中的 rollout 生成与策略更新过程:先让推理轨迹在关键位置分叉,再筛选出真正高质量的探索路径参与更新。
1. 熵驱动潜变量分支: 对每条初始 rollout,I²B-LPO 会定位策略熵较高的 “犹豫节点”,并基于当前推理前缀采样潜变量,通过伪自注意力机制(PSA)注入模型内部,持续影响后续生成,从而得到多条结构上更具差异的推理轨迹。
2. 信息瓶颈自奖励: 对生成的分支轨迹,I²B-LPO 使用信息瓶颈指标进行排序和筛选,保留简洁、高信息量、对答案真正有帮助的路径,过滤冗长、重复或逻辑漂移的无效探索,并将高质量轨迹用于 GRPO 策略更新。
具体流程可以概括为:初始 rollout → 高熵节点分支 → 生成候选推理轨迹 → IB 自奖励筛选 → GRPO 策略更新
1. 熵驱动潜变量分支
对于一条初始推理轨迹 r=(o1,…,oT),I²B-LPO 首先计算每个生成位置的策略熵:
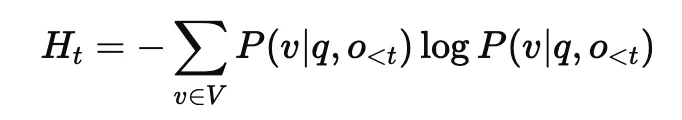
其中,Ht 衡量模型在第 t 步生成下一个 token 时的不确定性。熵越高,说明模型在当前位置越 “犹豫”,也更可能存在不同推理方向。
因此,我们选择高熵位置作为推理分叉点:
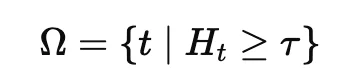
其中,τ 表示熵的高分位阈值。随后,I²B-LPO 基于当前推理前缀 ct∗ 采样潜变量:
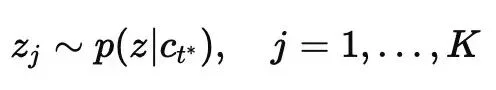
这些潜变量代表不同的潜在推理方向。为了让它们持续影响后续生成,而不是只改变某个 token 的概率,I²B-LPO 设计了伪自注意力机制(Pseudo Self-Attention, PSA)。
具体来说,PSA 首先用潜变量调制 RMSNorm 的缩放参数:
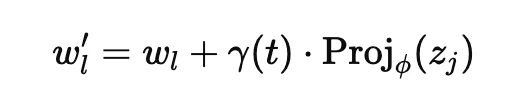
其中,γ(t) 是随生成过程逐渐衰减的注入强度。这样可以让潜变量在推理早期提供方向引导,同时避免后期过度干扰。接着,PSA 将潜变量映射为额外的 Key 和 Value,并拼接到原始注意力中:
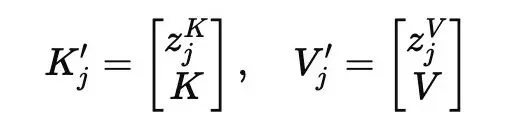
最终注意力计算变为:
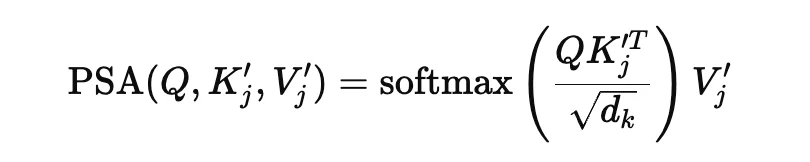
直观来说,PSA 相当于给模型加入一个 “隐含思路提示”:它持续影响后续推理轨迹,使同一条 rollout 在关键节点分化出多条更具区分度的路径。
2. 信息瓶颈自奖励
生成多条候选轨迹后,I²B-LPO 不会直接全部用于训练,而是利用信息瓶颈指标进行筛选。核心思想是:好的推理路径应该既简洁,又对最终答案有帮助。
我们用如下分数衡量一条轨迹的质量:
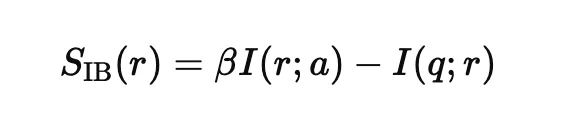
其中,I (r;a) 表示推理轨迹对最终答案的信息贡献,I (q;r) 用于约束轨迹不要过度冗长或重复。分数越高,说明该轨迹越简洁、有效、直击答案。
最终,I²B-LPO 保留 IB 分数最高的 Top-N 条轨迹:
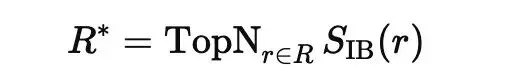
并将其用于 GRPO 策略更新:
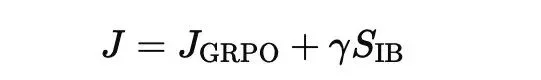
为了验证我们的模型在数学推理任务中的表现,我们进行了广泛的实验,并在多个基准数据集上进行了测试。以下是实验部分的详细介绍:
训练数据:
训练数据主要来自 DAPO 和 MATH。为提升训练效率,我们过滤了过于简单、过于困难以及容易导致超长输出的样本,最终保留 6,486 条 MATH 样本和 13,583 条 DAPO 样本用于训练。
Benchmarks:
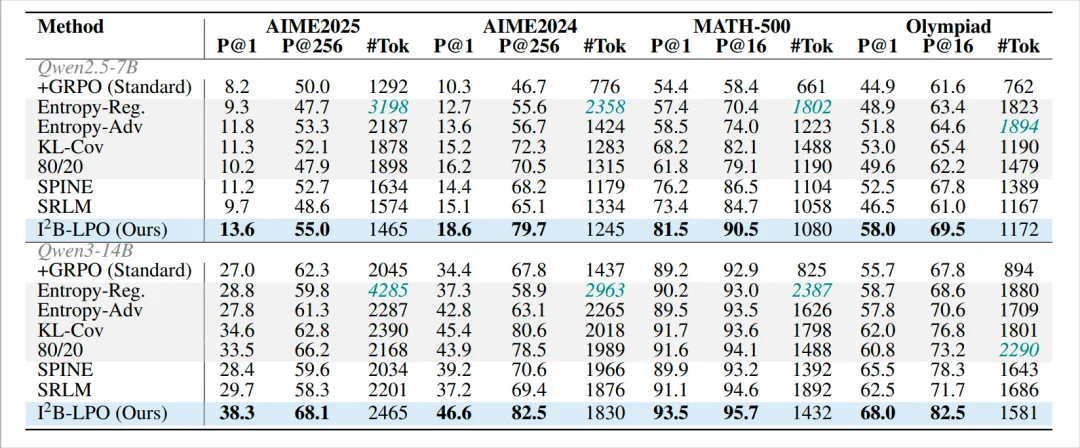
表 2: 不同方法的推理准确率对比
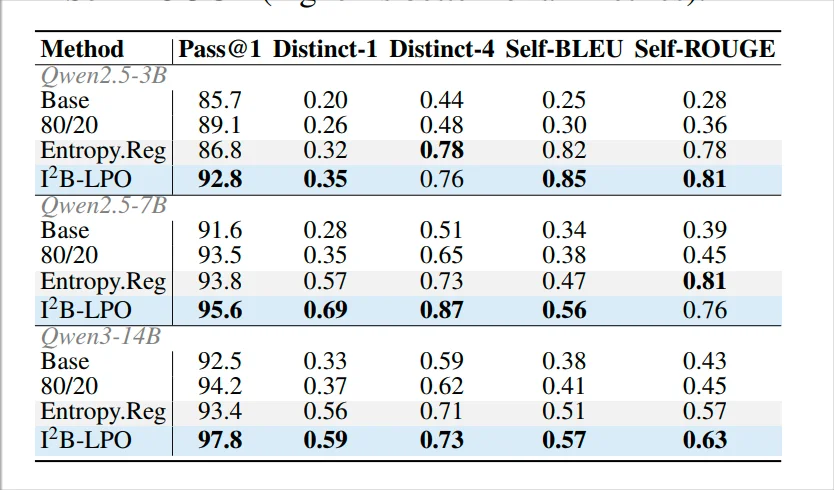
表 3: 不同方法的推理多样性指标对比
表 2 和表 3 分别验证了 I²B-LPO 在推理准确率与生成多样性上的优势。结果显示,I²B-LPO 在不同模型规模和多个数学基准上均稳定提升性能,不仅答得更准,也能生成更多样的推理路径。
图 3: 不同方法下的熵分布与训练动态对比。(a)展示不同方法下 token 概率与熵的分布关系;(b)展示训练过程中平均熵的变化趋势。相比 其他方法,I²B-LPO 能在训练后期维持更稳定的熵水平。
图 3 用于分析 I²B-LPO 是否真正改善了模型的探索行为。如图 3 所示,(a)散点图中标准 GRPO 的 token 更容易集中到低熵区域,说明模型逐渐变得 “确定”,探索空间被压缩;Entropy Regularization 虽然提高了熵,但容易出现异常高熵点,带来无效发散。I²B-LPO 则保持了更均衡的概率 - 熵分布。(b)曲线进一步表明,I²B-LPO 能在训练后期维持相对较高且稳定的熵水平,避免模型过早陷入单一推理模板,从而保留有效探索能力。
图 4. 不同难度题目下的注意力头激活模式对比。红色表示在高难度题目中更活跃的注意力头,蓝色表示在低难度题目中更活跃的注意力头。
为验证潜变量分支是否带来结构化推理引导 还是 随机噪声注入,我们可视化了注意力激活模式。如图 4 所示,输入层注入机制容易被深层稀释,softmax 层注入机制则会造成分散激活;而 I²B-LPO 使用的 PSA 伪自注意力注入能够在深层激活与难题相关的注意力头,形成更有结构的推理激活模式。
我们进一步分析了自奖励机制筛除的低质量轨迹,发现低 IB 分数的轨迹主要有三类典型问题:
相比之下,高 IB 分数的轨迹往往更短、更直接,并且每一步都服务于最终答案。这说明信息瓶颈自奖励不仅是在惩罚 “话多”,而是在筛选真正简洁、有效、有预测力的推理路径。案例分析如图 5 所示。

图 5. 高 IB 分数与低 IB 分数推理轨迹对比
本研究聚焦于提升 RLVR 后训练中的探索效率与推理质量。通过系统分析,我们发现,标准随机 rollout 容易让模型收敛到少数高概率推理模板,导致多条推理轨迹表面不同、底层同质,进而削弱轨迹间的奖励差异和有效学习信号。
基于这一发现,我们提出了探索增强框架 I²B-LPO。该方法将 RLVR 中的探索从 “重复采样更多答案” 推进到 “在关键节点生成更具区分度的推理轨迹”。I²B-LPO 主要通过两个关键机制实现高效探索:
实验结果表明,I²B-LPO 能够在多个数学推理基准上同时提升推理准确率与语义多样性,在有限采样预算下实现更高效、更可靠的 RLVR 探索。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
