
何恺明带大二本科生颠覆扩散图像生成:扔掉多步采样和潜空间,一步像素直出
何恺明带大二本科生颠覆扩散图像生成:扔掉多步采样和潜空间,一步像素直出何恺明,再次出手精简架构。
来自主题: AI技术研报
7581 点击 2026-02-03 08:44
 搜索
搜索
何恺明,再次出手精简架构。

OpenClaw、Moltbook彻底火了。
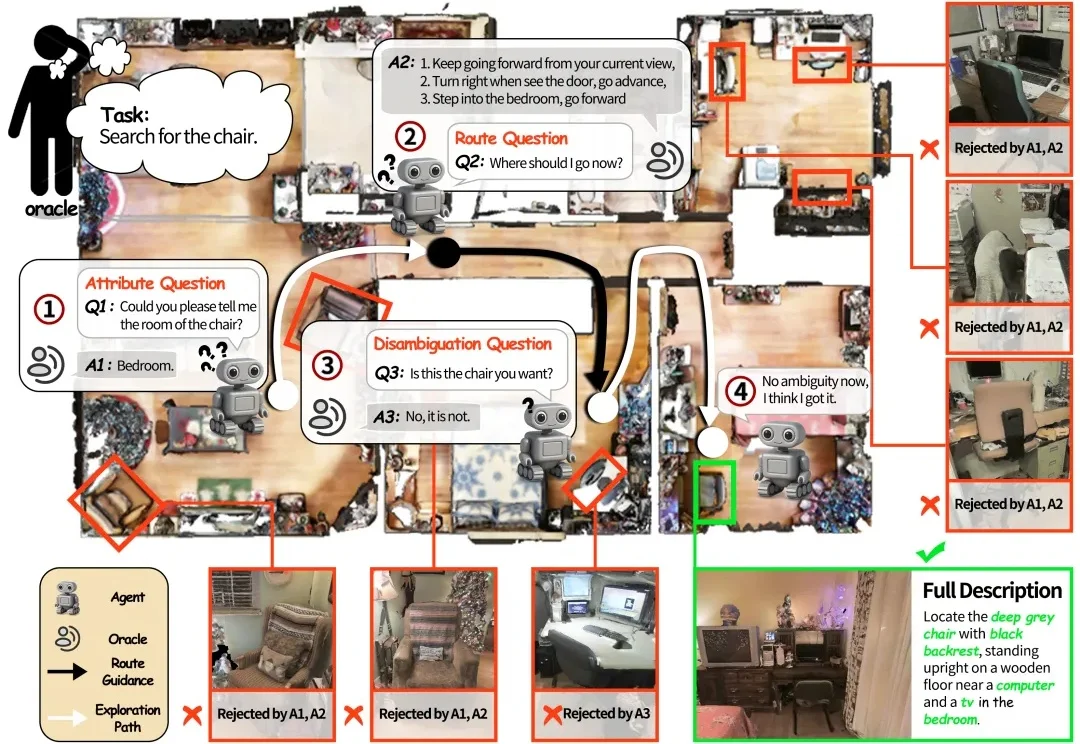
如果将一台在视觉语言导航(VLN)任务中表现优异的机器人直接搬进家庭场景,往往会遇到不少实际问题。
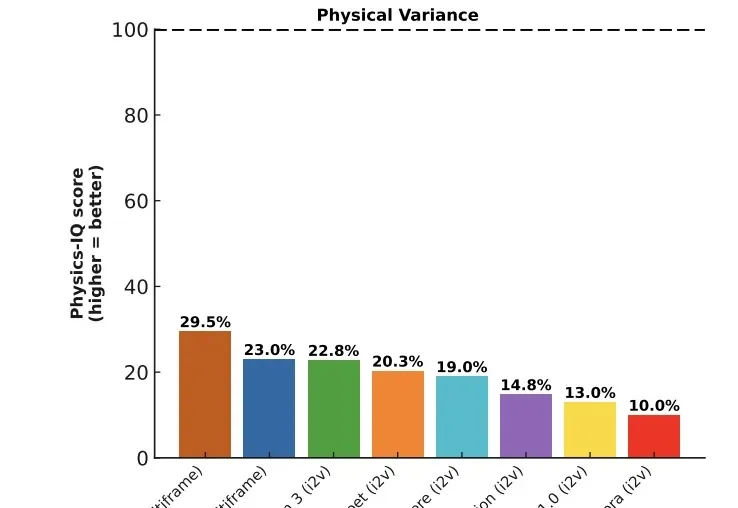
去年下半年,模型界最大的惊喜莫过于Sora 2和Veo 3,他们已经把视频生成推到了新高度:光影完美,纹理细腻,甚至有着很高的时空一致性。
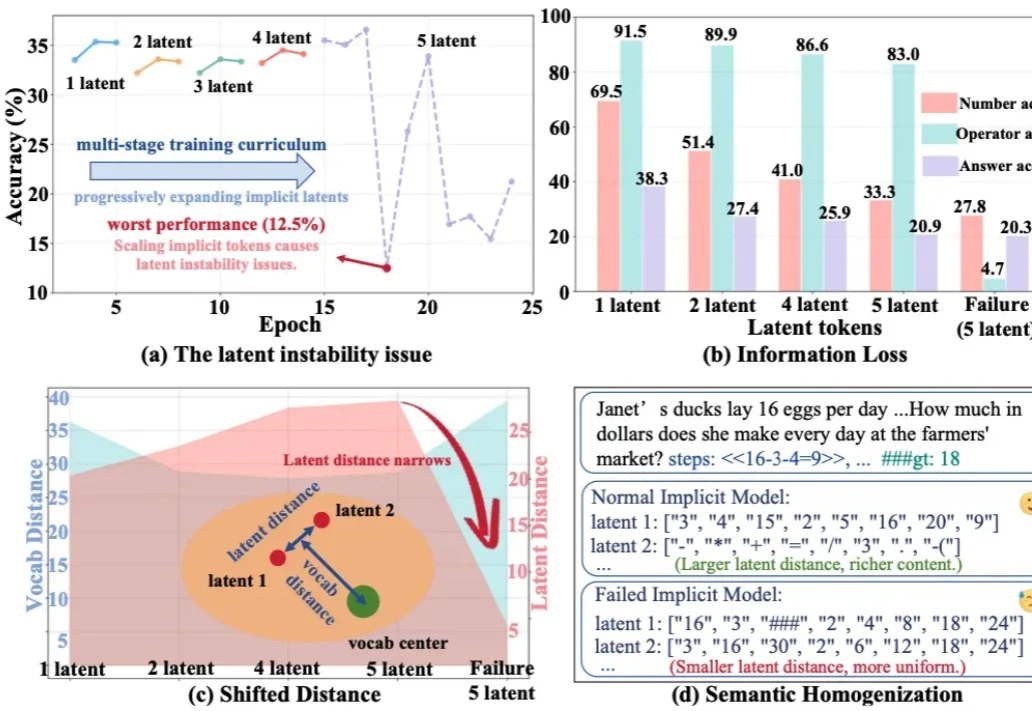
今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。
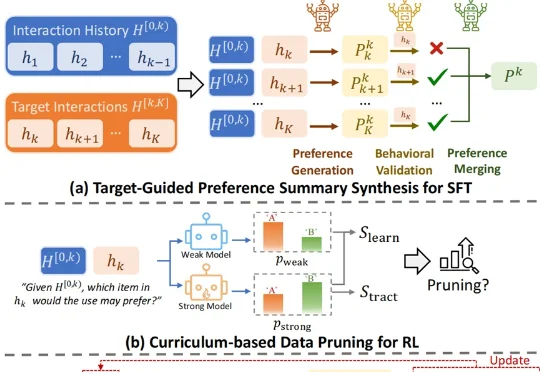
怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。

AI生成一张图片,你愿意等多久?在主流扩散模型还在迭代中反复“磨叽”、让用户盯着进度条发呆时,阿里智能引擎团队直接把进度条“拉爆”了——5秒钟,到手4张2K级高清大图。
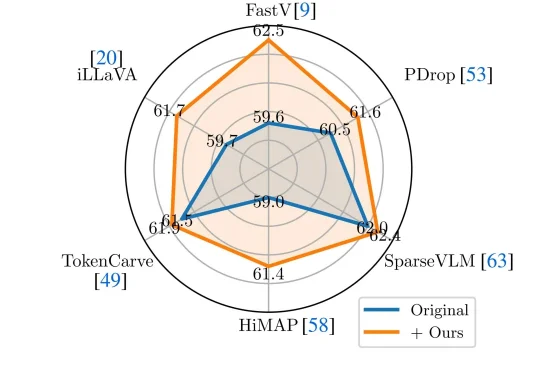
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。
国产算力基建跑了这么多年,大家最关心的逻辑一直没变:芯片够不够多?但对开发者来说,真正扎心的问题其实是:好不好使?

周伯文还详细介绍了上海 AI 实验室近年来开展的前沿探索与实践,包括驱动 “通专融合” 发展的技术架构 ——“智者”SAGE(Synergistic Architecture for Generalizable Experts),其包含基础、融合与进化三个层次,并可双向循环实现全栈进化;支撑 AGI4S 探索的两大基础设施“书生”科学多模态大模型 Intern-S1、“