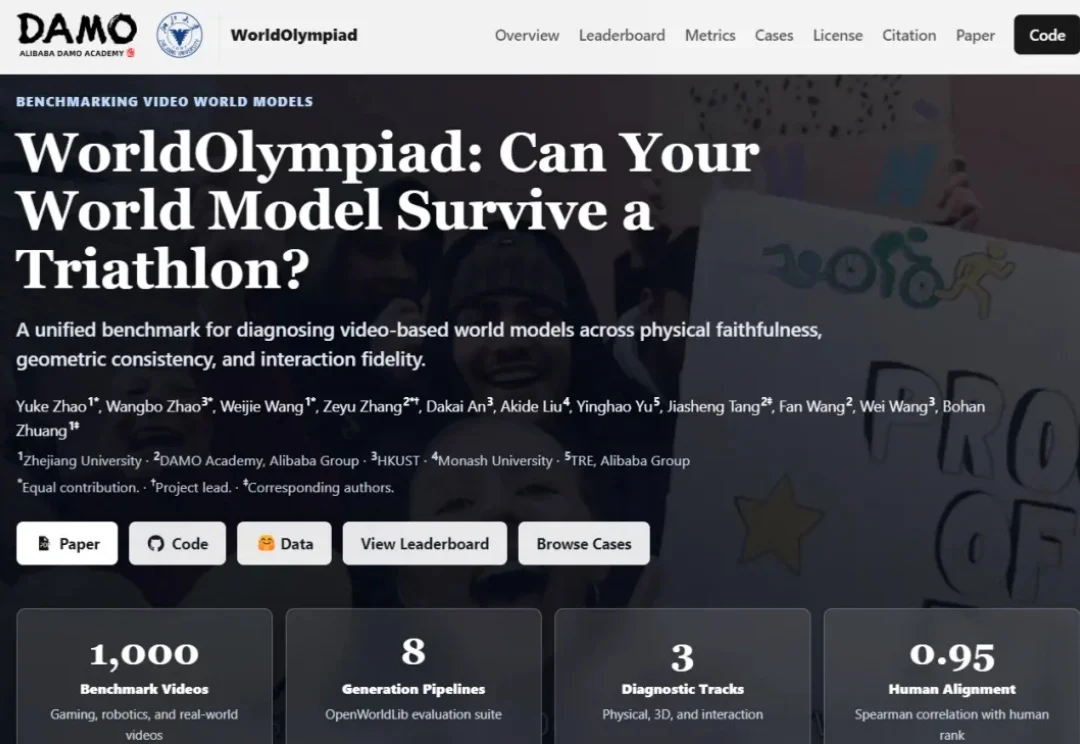
世界模型迎来「真考场」:WorldArena 2.0 Challenge正式启动
世界模型迎来「真考场」:WorldArena 2.0 Challenge正式启动WorldArena 1.0 的核心意义,在于将世界模型评测从 “好不好看” 推进到 “是否真的有用”。它不再只关注视频观感,而是把物理一致性、可控性、3D 准确性和具身任务功能性纳入统一评测框架,使许多看似流畅的生成结果第一次在机器人具身任务中接受检验。
来自主题: AI技术研报
9164 点击 2026-07-16 10:10