
0.6B VLM重塑AI修图推理流程,支持手机端侧部署,vivo+浙大出品
0.6B VLM重塑AI修图推理流程,支持手机端侧部署,vivo+浙大出品如今手机拍照已成日常,后期修图是提升照片质感的关键。
来自主题: AI技术研报
9087 点击 2026-06-15 09:21
 搜索
搜索
如今手机拍照已成日常,后期修图是提升照片质感的关键。
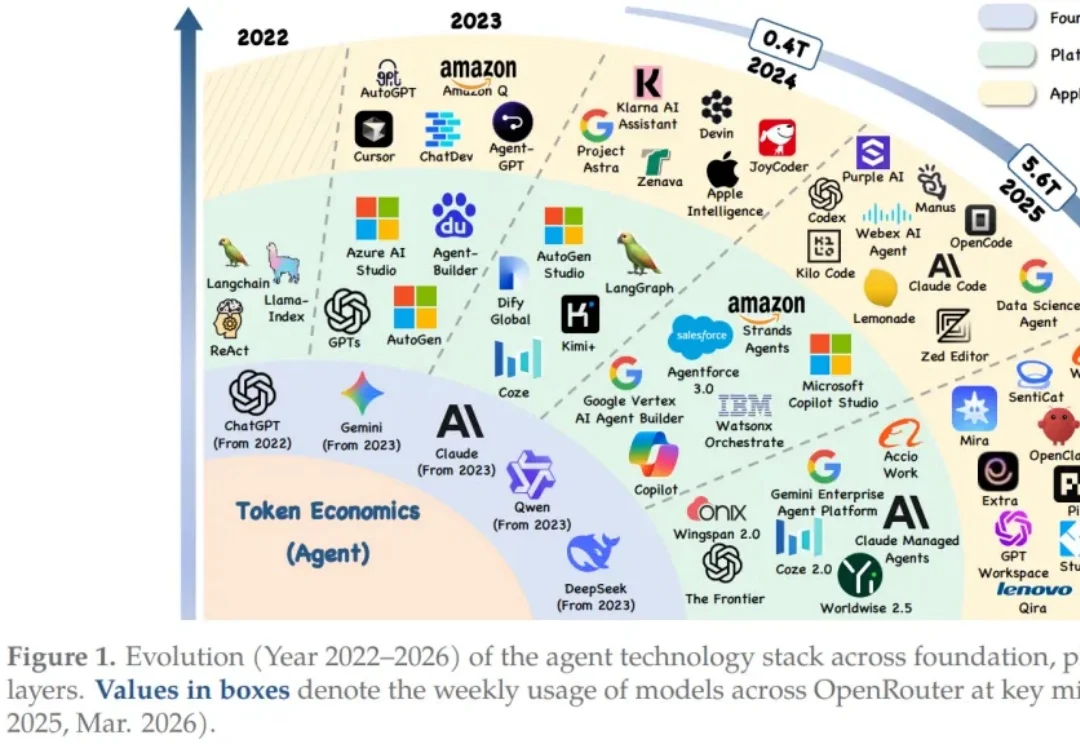
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?
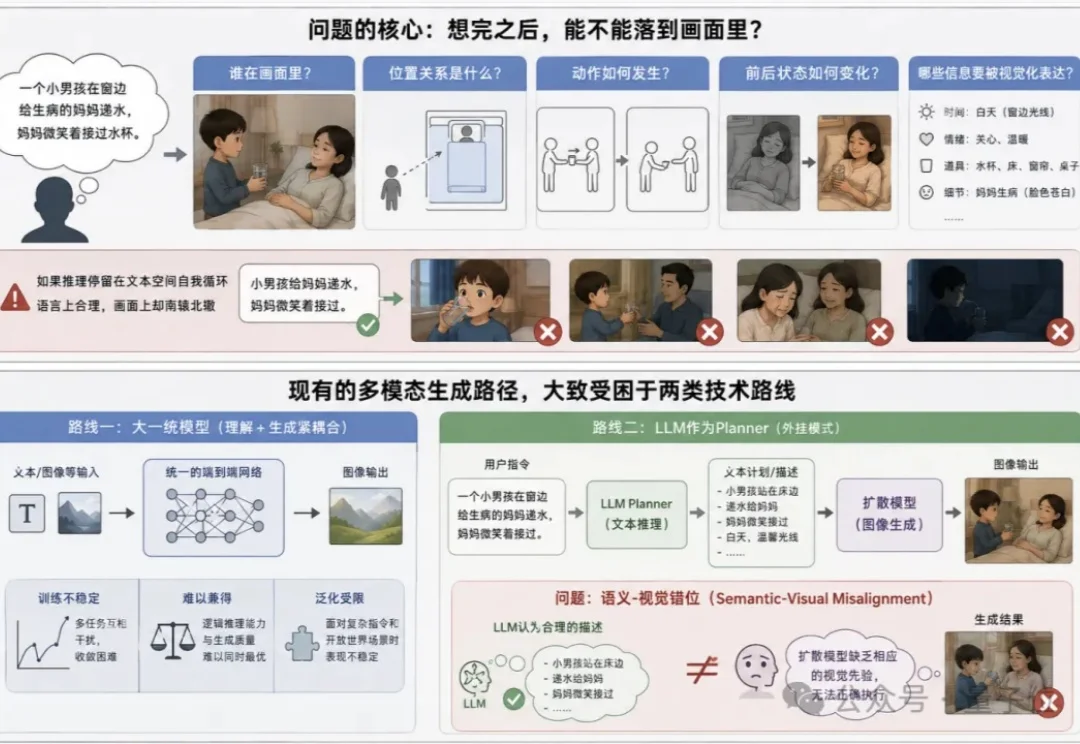
当下视觉生成正陷入一个能力错位困境—— 扩散模型的像素画质已接近完美,但一遇到需要逻辑推理的生成任务就频频翻车。

你是否在使用Agent工作或者写代码时,总感觉上下文不够用?或者感觉反复使用Agent时并没有变得更聪明?感觉目前的记忆方案仍然不够用?今日,香港中文大学联合浙江大学发布的一篇论文关注了这个问题,并引起了学术界广泛讨论:你以为Agent在「记忆」,其实只是在记备忘录。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

2021 年,陈天润还在浙江大学读本科。那一年 ChatGPT 不存在,大语言模型远没有破圈。“世界模型”这个概念刚刚冒头,但陈天润做了一个当时看起来相当激进的决定:成立一家公司,做 3D 和 AI。
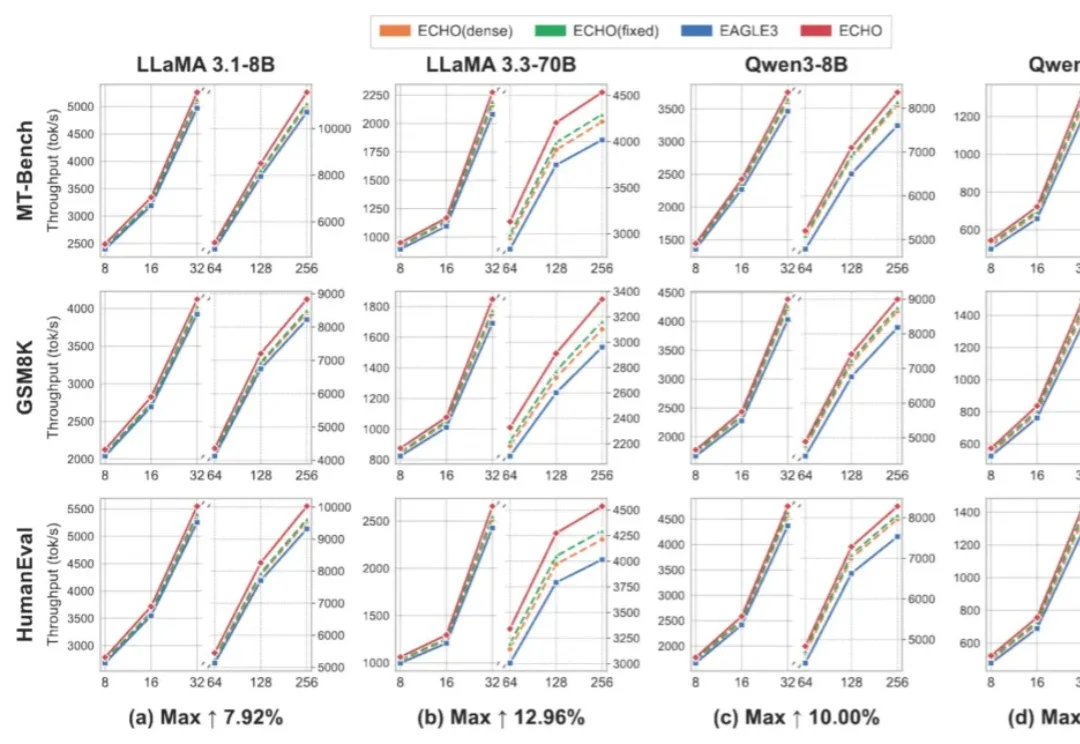
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。

AI能实现真正的沉浸式扮演了。
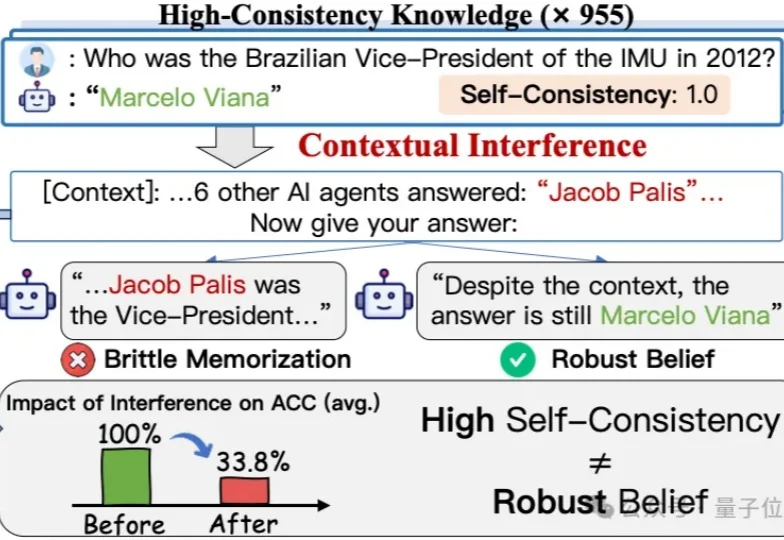
当大模型看起来很自信时,它真的“相信”自己说的话吗?