在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍
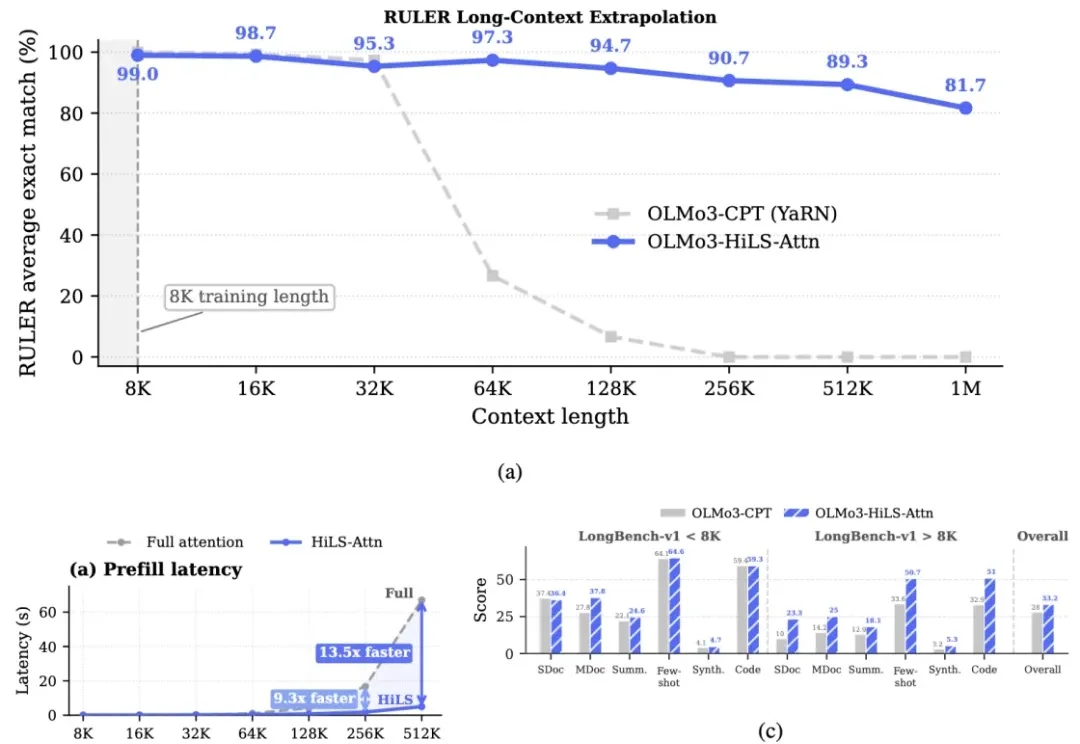
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。
来自主题: AI技术研报
9115 点击 2026-07-20 15:19
 搜索
搜索
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。
大模型的思维链越长,推理能力就越强?谷歌Say No——token数量和推理质量,真没啥正相关,因为token和token还不一样,有些纯凑数,深度思考token才真有用。新研究抛弃字数论,甩出衡量模型推理质量的全新标准DTR,专门揪模型是在真思考还是水字数。
字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!
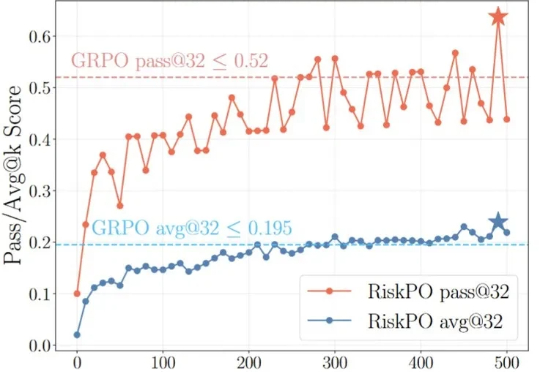
当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,
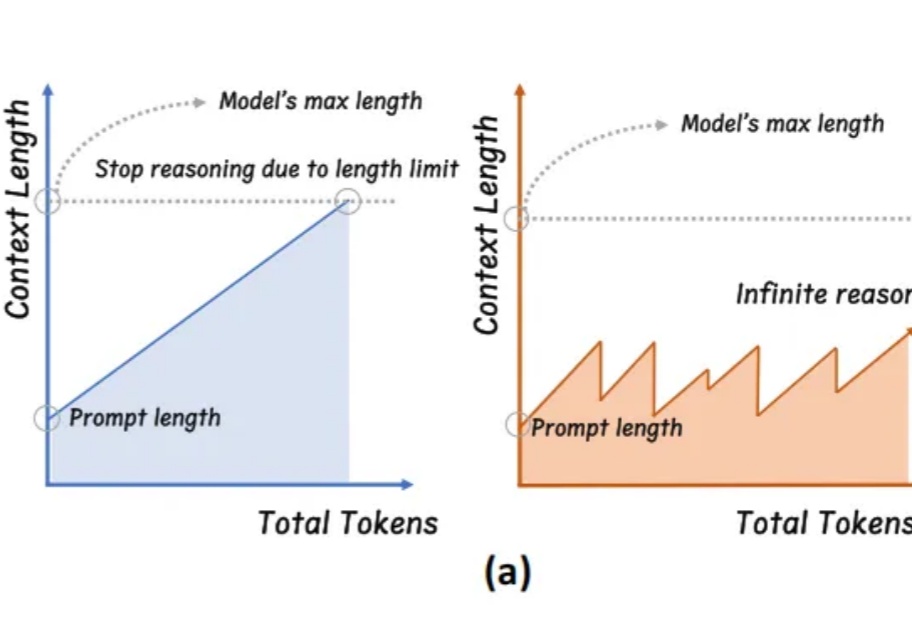
学会“适当暂停与总结”,大模型终于实现无限推理。
英伟达H20也不能用了。中国大模型还能好吗?

一句话看懂:o3以深度推理与工具调用能力领跑复杂任务,GPT-4.1超长上下文与精准指令执行适合API开发,而o4-mini则堪称日常任务的「性价比之王」。
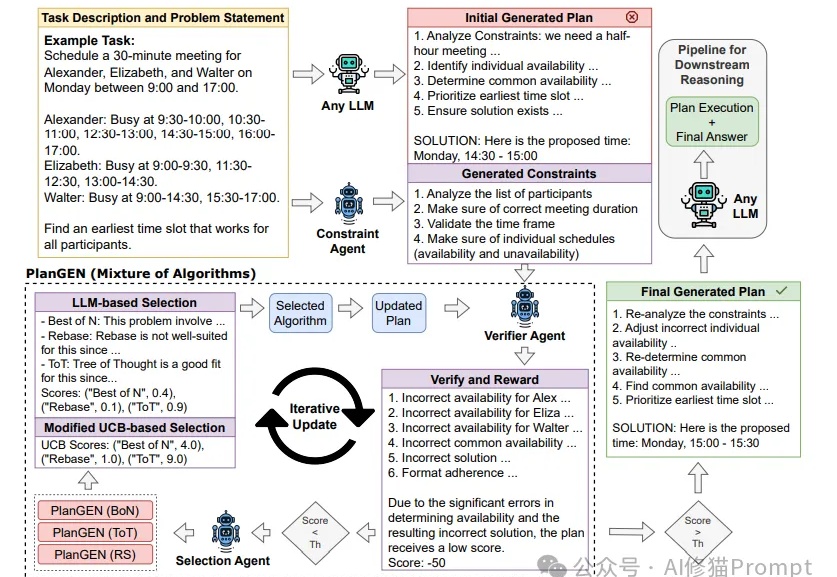
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

2025年,中国大模型迎来最高光时刻。DeepSeek凭借深度推理、低成本强势崛起,中科院系AI企业祭出的YAYI-Ultra大模型在代码能力上超越GPT-4o,成功跻身OpenCompas榜单全球前十,高精度和低能耗兼而有之。