

谷歌 Imagen 4 / Ultra 上线 AI Studio!将集成 Jules 和 MCP,我用它切了个黑洞。
谷歌 Imagen 4 / Ultra 上线 AI Studio!将集成 Jules 和 MCP,我用它切了个黑洞。谷歌把最新的文生图模型 Imagen 4,以及它的 Pro Max 版 Imagen 4 Ultra,放到了 AI Studio 和 API 里。
来自主题: AI资讯
8115 点击 2025-06-26 11:21
谷歌把最新的文生图模型 Imagen 4,以及它的 Pro Max 版 Imagen 4 Ultra,放到了 AI Studio 和 API 里。
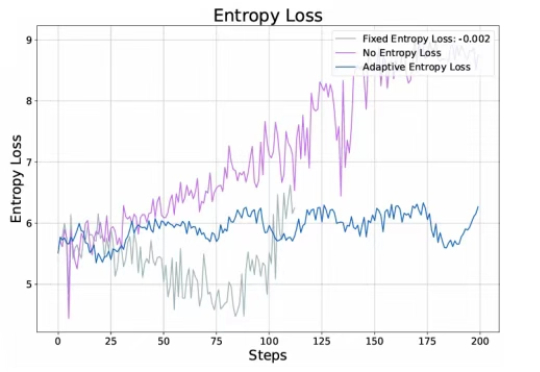
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。

即梦AI的图片3.0生图功能更新之后基本是国内图像模型的天花板了,尤其是在日常的设计任务上,基本上人人都能做海报。

图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。 有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?
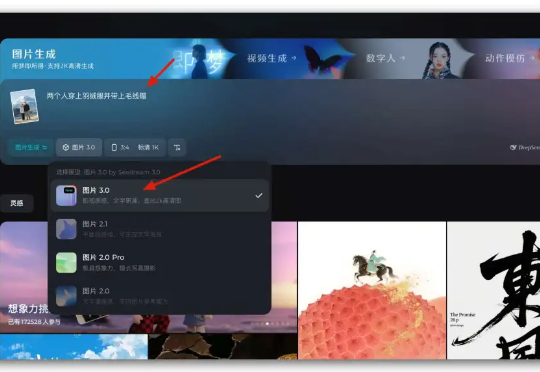
前段时间,我们横向对比了即梦3.0、2.1、GPT4o的海报生成能力, 当时即梦3.0的文生图中文能力就已经超过了 GPT4o,我们通过提示语就可以控制字体的样式、位置、大小、排版等等。

FLUX.1 Kontext是一款融合即时文本图像编辑与文本到图像生成的新一代模型,支持文本与图像提示,角色一致性强,速度快达GPT-Image-1的8倍。

AI生图新突破!一个模型同时接受文本和图像输入。

3月时候GPT迎来了一波更新,在文生图、图生图领域带来了巨大更新,而紧接而至的却是一些创业公司的哀嚎:
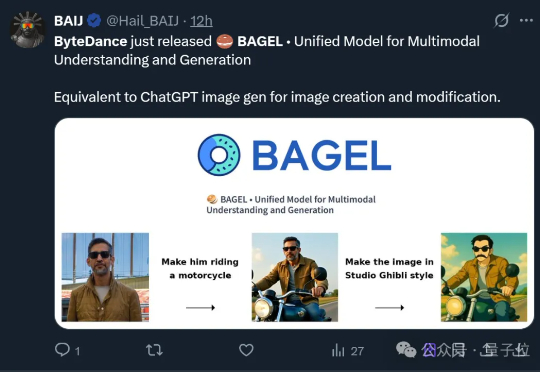
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。

Recraft,利用AI生成和编辑高质量矢量插图和图标,服务于设计和市场团队。完成3000万美元B轮融资,投资方为Accel、Khosla Ventures、Madrona。本轮估值未知,累计融资4200万美元。