
过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o
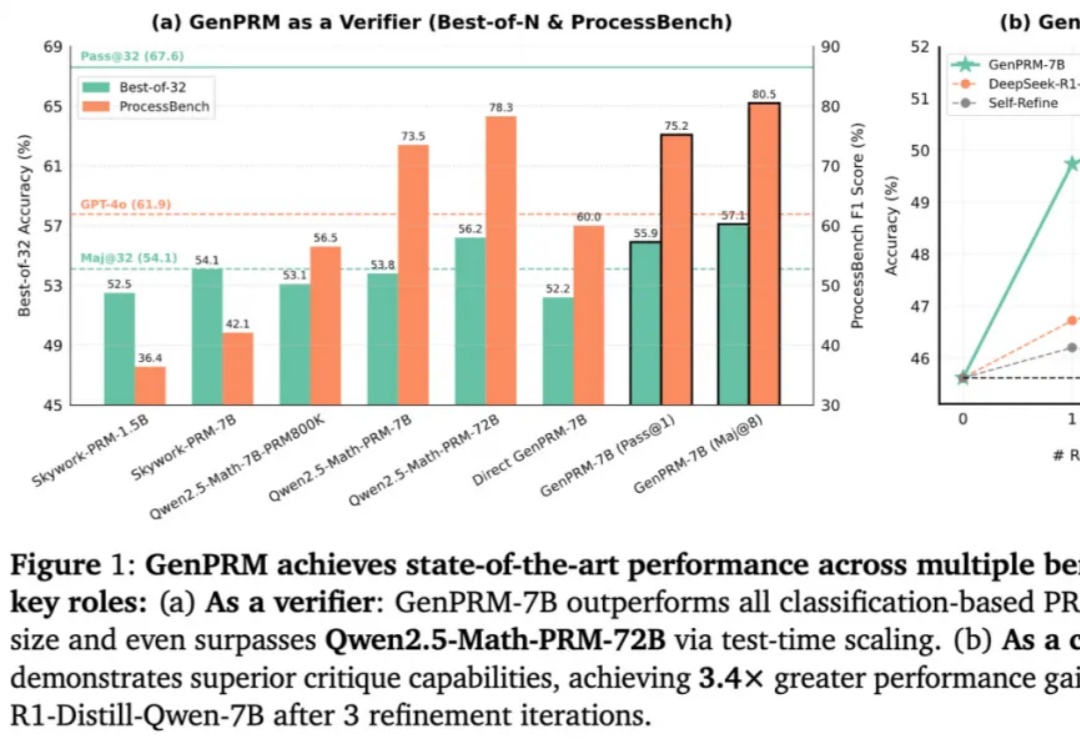
过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。
来自主题: AI技术研报
8973 点击 2025-04-14 14:39