
告别「面瘫」配音,InfiniteTalk开启从口型同步到全身表达新范式
告别「面瘫」配音,InfiniteTalk开启从口型同步到全身表达新范式传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。
来自主题: AI技术研报
9901 点击 2025-08-28 14:32
 搜索
搜索
传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。

最近3D内容生成模型好生热闹,像谷歌Genie 3、World Labs、混元、昆仑争相发布并开测世界模型。

百度最新视频生成模型蒸汽机2.0(MuseSteamer 2.0),好像真的有点东西。

最初说不做视频生成模型的百度,现在在视频生成的路上一路狂奔! 就在刚刚,百度蒸汽机(MuseSteamer)视频生成大模型升级至2.0版本,主打多人有声音视频一体化生成。

多模态的生成,是 AI 未来的方向。 最近,AI 领域的气氛正在发生微妙的变化。比如,刚刚推出了 Grok 4 的 xAI 却在重点宣传他们的视频生成模型 Grok Image。

要让视频生成模型真正成为模拟真实物理世界的「世界模型」,必须具备长时间生成并保留场景记忆的能力。然而,交互式长视频生成一直面临一个致命短板:缺乏稳定的场景记忆。镜头稍作移动再转回,眼前景物就可能「换了个世界」。
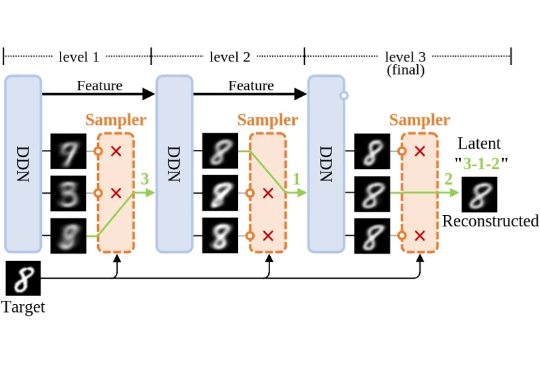
本项工作提出了一种全新的生成模型:离散分布网络(Discrete Distribution Networks),简称 DDN。相关论文已发表于 ICLR 2025。
制作一个视频需要几步?可以简单概括为:拍摄 + 配音 + 剪辑。 还记得 veo3 发布时引起的轰动吗?「音画同步」功能的革命性直接把其他视频生成模型按在地上摩擦,拍摄 + 配音 + 粗剪一键搞定。
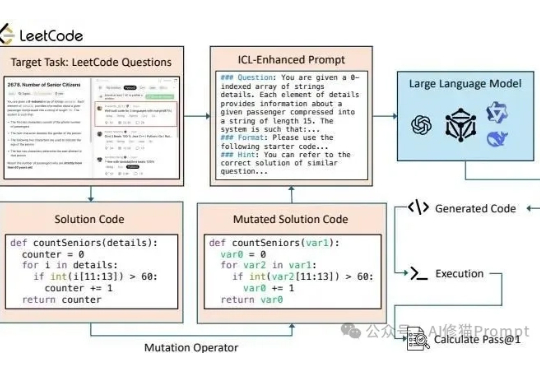
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。