全球第一再升级!MiniMax Speech 2.5上线:多语种表现力更强,音色复刻更“像”
全球第一再升级!MiniMax Speech 2.5上线:多语种表现力更强,音色复刻更“像”今天,MiniMax发布新一代语音生成模型Speech 2.5,再次刷新全球最强语音模型的上限。
来自主题: AI资讯
8276 点击 2025-08-08 14:17
 搜索
搜索
今天,MiniMax发布新一代语音生成模型Speech 2.5,再次刷新全球最强语音模型的上限。

7月底 Black Forest Labs 和 Krea 合作开发的高级文本到图像生成模型 Flux.1 Krea Dev,最近终于有时间进行测评了。Flux.1 Krea Dev 是基于FLUX.1 dev 模型进行蒸馏的,参数规模12B,专注于提升图像的美学和真实感,避免了常见的 AI 生成痕迹(过度饱和或不自然高光等等),更倾向于追求自然细节、照片级真实感和多样性。

通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。

电影级视频生成模型来了。
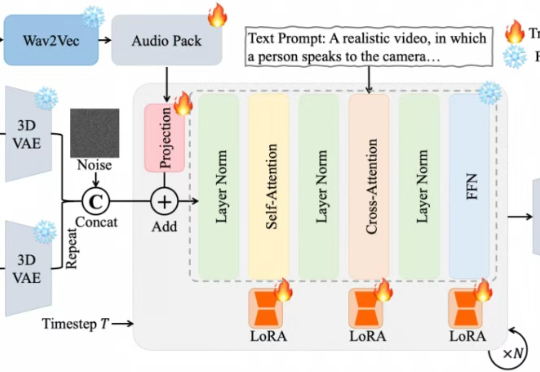
近期,夸克技术团队和浙江大学联合开源了OmniAvatar,这是一个创新的音频驱动全身视频生成模型,只需要输入一张图片和一段音频,OmniAvatar即可生成相应视频,且显著提升了画面中人物的唇形同步细节和全身动作的流畅性。此外,还可通过提示词进一步精准控制人物姿势、情绪、场景等要素。

6月30日,OpenAI支持的Chai Discovery推出Chai-2,这款多模态生成模型展现出强大的抗体设计能力,一经发布便引起巨大轰动。

怎么快速判断一个生成模型好不好? 最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。

97年创始人宋亚宸创立3D大模型公司VAST,已完成三轮数亿元融资,估值业界最高。公司50人团队年收入700万美元,Tripo产品生成模型量达3000万个,用户超300万。未用OKR/KPI管理,靠独特文化(如季度调薪、淡化优先级、兴趣包容)激发效率。战略从C端转向服务PGC用户推出Tripo Studio,月收60万美元。
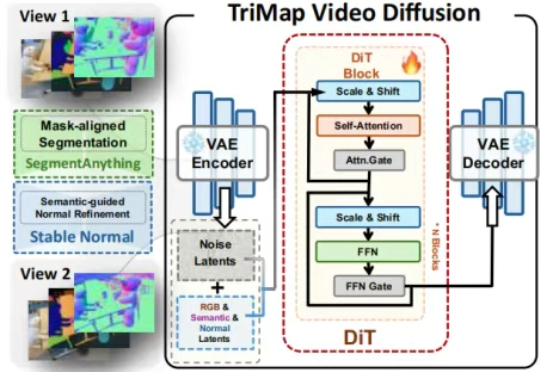
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。

智源统一图像生成模型OmniGen2发布后,立刻在AI图像生成领域掀起巨响,多模态技术生态进一步打通。才一周,GitHub星标就已经破了2000,X上的话题浏览数直接破数十万。