# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Representation matters. Representation matters. Representation matters.
是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」
Yann LeCun 也对他们的研究表示了认可:「我们知道,当使用自监督学习训练视觉编码器时,使用具有重构损失的解码器的效果远不如使用具有特征预测损失和崩溃预防机制的联合嵌入架构。这篇来自纽约大学 @sainingxie 的论文表明,即使你只对生成像素感兴趣(例如使用扩散 Transformer 生成漂亮图片),也应该包含特征预测损失,以便解码器的内部表征可以根据预训练的视觉编码器(例如 DINOv2)预测特征。」
我们知道,在生成高维视觉数据方面,基于去噪的生成模型(如扩展模型和基于流的模型)的表现非常好,已经得到了广泛应用。近段时间,也有研究开始探索将扩展模型用作表征学习器,因为这些模型的隐藏状态可以捕获有意义的判别式特征。
而谢赛宁指导的这个团队发现(另一位指导者是 KAIST 的 Jinwoo Shin),训练扩散模型的主要挑战源于需要学习高质量的内部表征。他们的研究表明:「当生成式扩散模型得到来自另一个模型(例如自监督视觉编码器)的外部高质量表征的支持时,其性能可以得到大幅提升。」
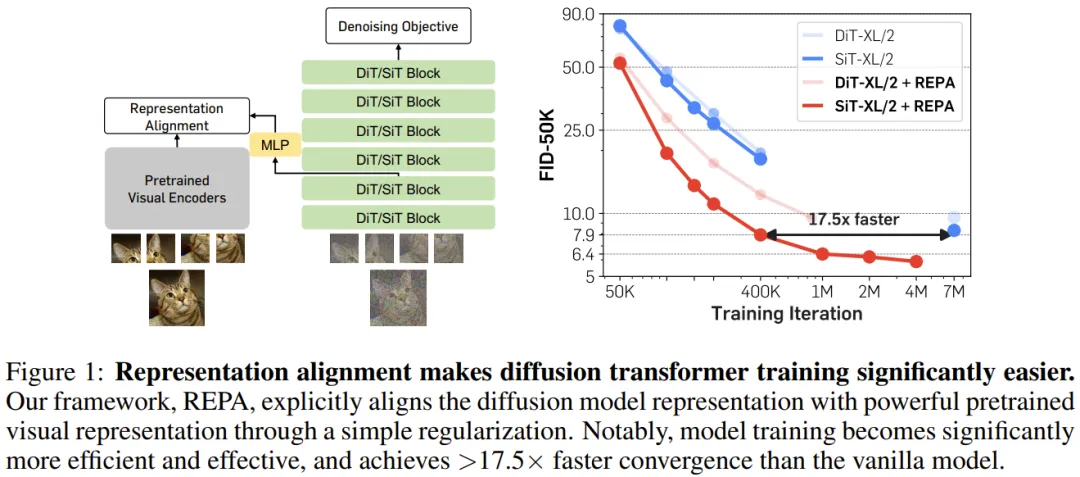
REPresentation Alignment(REPA),即表征对齐技术,便基于此而诞生了。这是一个基于近期的扩散 Transformer(DiT)架构的简单正则化技术。

本质上讲,REPA 就是将一张清晰图像的预训练自监督视觉表征蒸馏成一个有噪声输入的扩展 Transformer 表征。这种正则化可以更好地将扩展模型表征与目标自监督表征对齐。
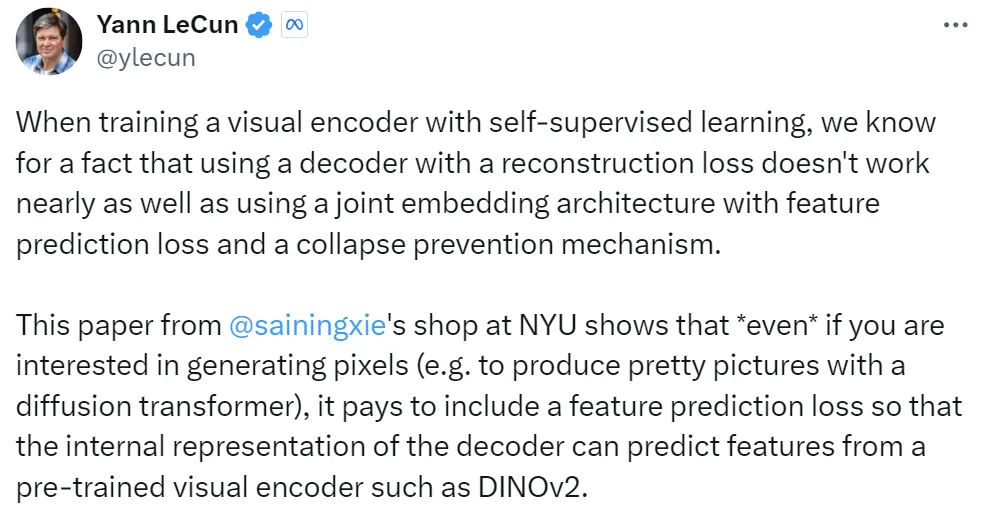
方法看起来很简单,但 REPA 的效果却很好!据介绍,REPA 能大幅提升模型训练的效率和效果。相比于原生模型,REPA 能将收敛速度提升 17.5 倍以上。在生成质量方面,在使用带引导间隔(guidance interval)的无分类器引导时,新方法取得了 FID=1.42 的当前最佳结果。
REPresentation Alignment(REPA)是一种简单的正则化方法,其使用了近期的扩展 Transformer 架构。简单来说,该技术就是一种将预训练的自监督视觉表征蒸馏到扩展 Transformer 的简单又有效的方法。这让扩散模型可以利用这些语义丰富的外部表征进行生成,从而大幅提高性能。
REPA 的诞生基于该团队得到的几项重要观察。
他们研究了在 ImageNet 上预训练得到的 SiT(可扩展插值 Transformer)模型的逐层行为,该模型使用了线性插值和速度预测(velocity prediction)进行训练。他们研究的重点是扩散 Transformer 和当前领先的监督式 DINOv2 模型之间的表征差距。他们从三个角度进行了研究:语义差距、特征对齐进展以及最终的特征对齐。
对于语义差距,他们比较了使用 DINOv2 特征的线性探测结果与来自 SiT 模型(训练了 700 万次迭代)的线性探测结果,采用的协议涉及到对扩散 Transformer 的全局池化的隐藏状态进行线性探测。
接下来,为了测量特征对齐,他们使用了 CKNNA;这是一种与 CKA 相关的核对齐(kernel alignment)指标,但却是基于相互最近邻。这样一来,便能以量化方式评估对齐效果了。图 2 总结了其结果。
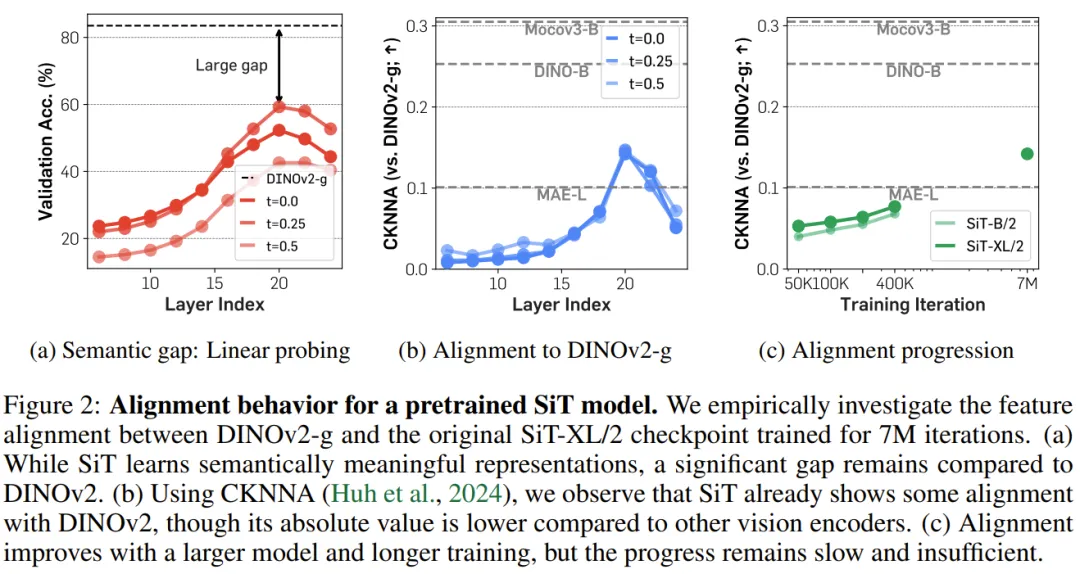
扩散 Transformer 与先进视觉编码器之间的语义差距明显。如图 2a 所示,可以观察到,预训练扩散 Transformer 的隐藏状态表征在第 20 层能得到相当高的线性探测峰值。但是,其性能仍远低于 DINOv2,表明这两种表征之间存在相当大的语义差距。此外,他们还发现,在此峰值之后,线性探测性能会迅速下降,这表明扩散 Transformer 必定从重点学习语义丰富的表征转向了生成具有高频细节的图像。
扩散表征已经与其它视觉表征(细微地)对齐了。图 2b 使用 CKNNA 展示了 SiT 与 DINOv2 之间的表征对齐情况。可以看到,SiT 模型表征的对齐已经优于 MAE,而后者也是一种基于掩码图块重建的自监督学习方法。但是,相比于其它自监督学习方法之间的对齐分数,其绝对对齐分数依然较低。这些结果表明,尽管扩散 Transformer 表征与自监督视觉表征存在一定的对齐,但对齐程度不高。
当模型增大、训练变多时,对齐效果会更好。该团队还测量了不同模型大小和训练迭代次数的 CKNNA 值。图 2c 表明更大模型和更多训练有助于对齐。同样地,相比于其它自监督视觉编码器之间的对齐,扩散表征的绝对对齐分数依然较低。
这些发现并非 SiT 模型所独有,其它基于去噪的生成式 Transformer 也能观察到。该团队也在 DiT 模型上观察到了类似的结果 —— 其使用 DDPM 目标在 ImageNet 上完成了预训练。

该研究首先比较两个 SiT-XL/2 模型在前 400K 次迭代期间生成的图像,其中一个模型应用 REPA。两种模型共享相同的噪声、采样器和采样步骤数,并且都不使用无分类器引导。使用 REPA 训练的模型表现更好。

该研究通过改变预训练编码器和扩散 transformer 模型大小来检查 REPA 的可扩展性,结果表明:与更好的视觉表征相结合可以改善生成和线性探测结果。
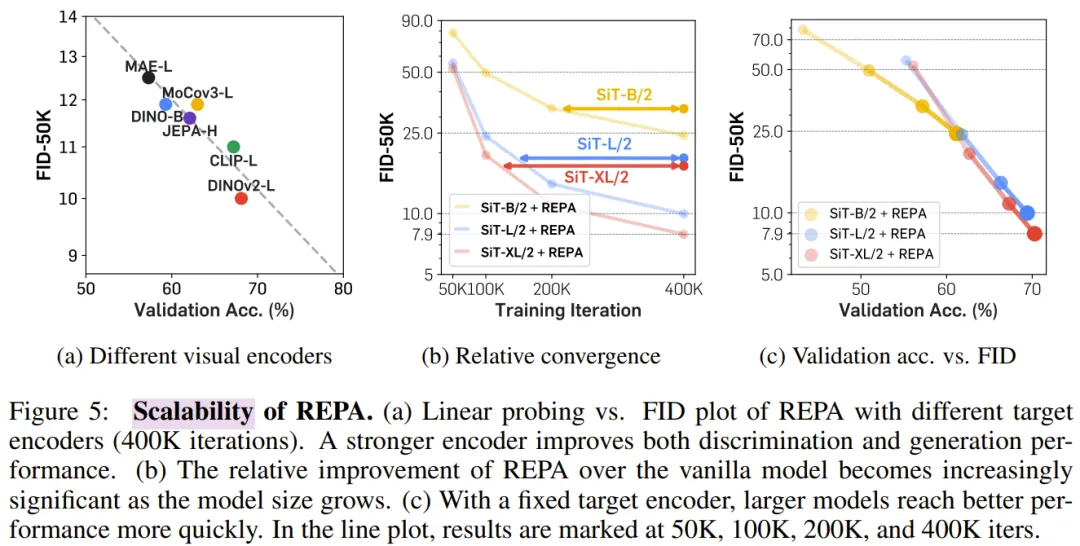
REPA 还在大型模型中提供了更显著的加速,与普通模型相比,实现了更快的 FID-50K 改进。此外,增加模型大小可以在生成和线性评估方面带来更快的增益。
最后,该研究比较了普通 DiT 或 SiT 模型与使用 REPA 训练的模型的 FID 值。
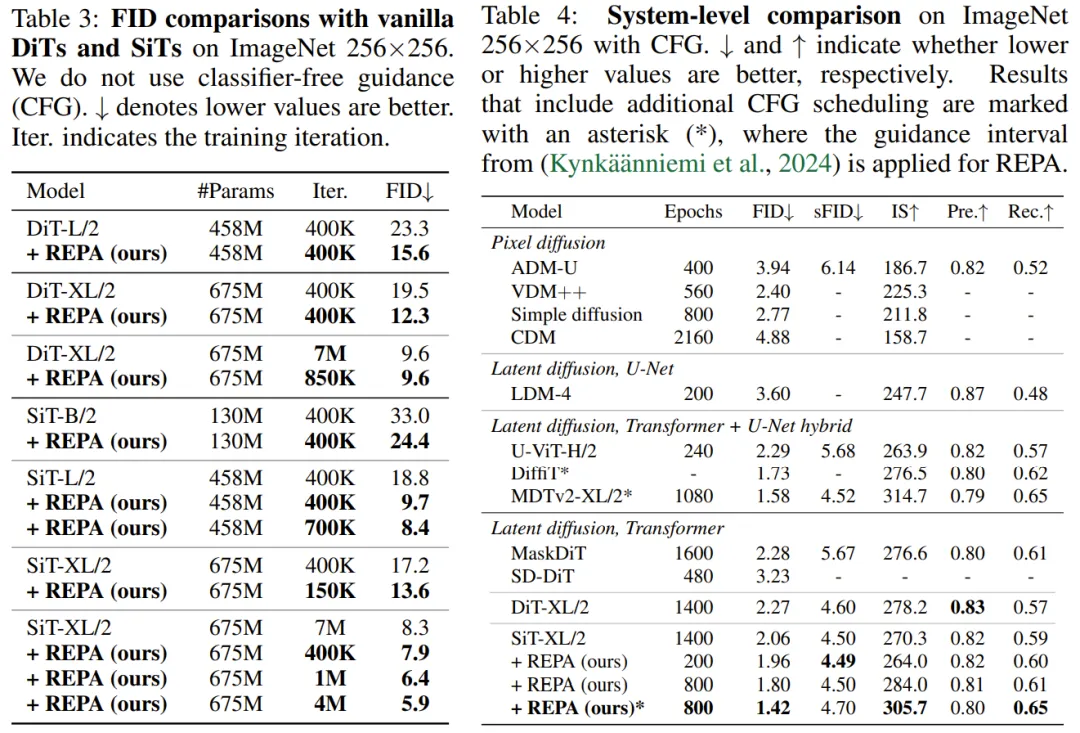
在没有无分类器引导的情况下,REPA 在 400K 次迭代时实现了 FID=7.9,优于普通模型在 700 万次迭代时的性能。
使用无分类器引导,带有 REPA 的 SiT-XL/2 的性能优于最新的扩散模型,迭代次数减少为 1/7,并通过额外的引导调度实现了 SOTA FID=1.42。
该团队也执行了消融研究,探索了不同时间步数、不同视觉编码器和不同 λ 值(正则化系数)的影响。详见原论文。
文章来自于 微信公众号“机器之心”



