
独家|面壁智能端侧大模型将搭载三星手机上市
独家|面壁智能端侧大模型将搭载三星手机上市端侧AI持证上岗了。
来自主题: AI资讯
10543 点击 2026-07-16 10:32
 搜索
搜索
端侧AI持证上岗了。
刚刚,网信中国发布公告,「Apple 智能」正式通过生成式人工智能服务备案。 和苹果一起「持证上岗」的还有华为小艺 AI 大模型、OPPO AndesGPT、vivo 蓝心端侧大模型、小米澎湃 AI、三星盖乐世 AI 和努比亚豆包手机大模型,一共 7 款手机端侧大模型在 7 月 8 日集体过审。
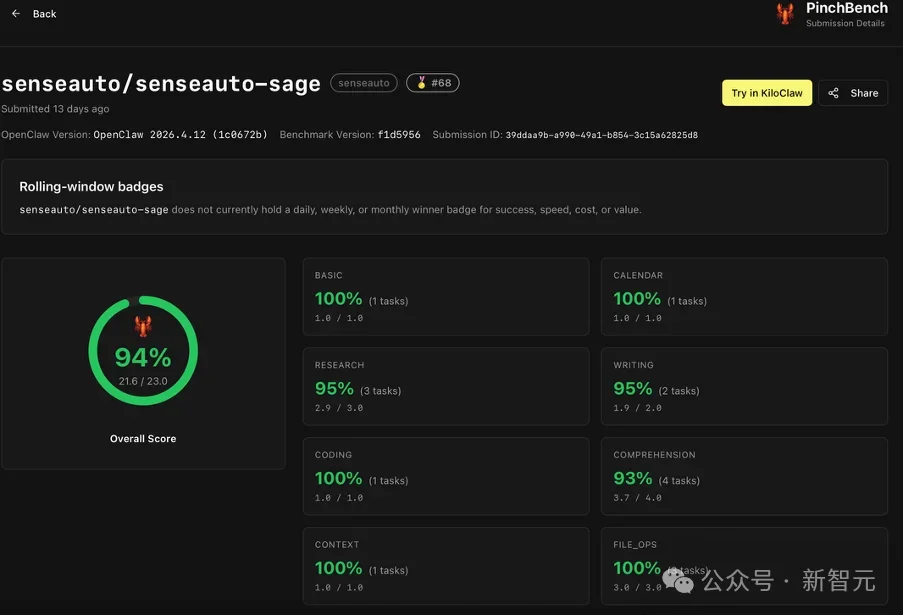
一个3B激活参数的端侧模型,在全球Agent权威评测中,以94%任务完成率,超越了Claude、GPT-5.4、Gemini等国际主流云侧和端侧大模型。商汤绝影Sage来了,它不是「更聪明的语音助手「,而是第一个真正能在车里「办成复杂事「的智能体基座。

从手机、PC、汽车到机器人,我们需要怎样的端侧AI "芯" 思路? 作者 | 云鹏 编辑 | 漠影 机器人走猫步引爆行业、舞蹈功夫如人类般丝滑;AI手机一句话订外卖做报告、懂你所想知你所言;AI PC

面壁智能近期已完成新一轮融资。本轮融资由北京市属国有投资平台“京国瑞”(北京京国瑞股权投资基金管理有限公司)及市场化创投基金“米聚和基”等共同参与,数亿元资金将主要用于加大端侧大模型研发力度及推动商业化进程。
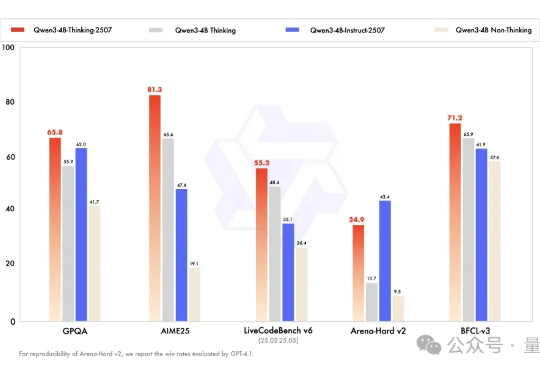
三天不开源,Qwen团队手就痒。 昨天深夜再次放出两个端侧模型: Qwen3-4B-Instruct-2507:非推理模型,大幅提升通用能力 Qwen3-4B-Thinking-2507:高级推理模型,专为专家级任务设计
移动端侧模型迎来“新王”。

专注于端侧大模型研发的中国AI初创企业面壁智能完成新一轮数亿元融资,本轮融资由洪泰基金、国中资本、清控金信和茅台基金联合投资。本轮融资的完成,将进一步为面壁智能构筑高效大模型技术、产品壁垒、加速行业赋能与生态拓展奠定坚实基础,协同产业上下游推动「端侧大脑」在千行百业规模化应用。
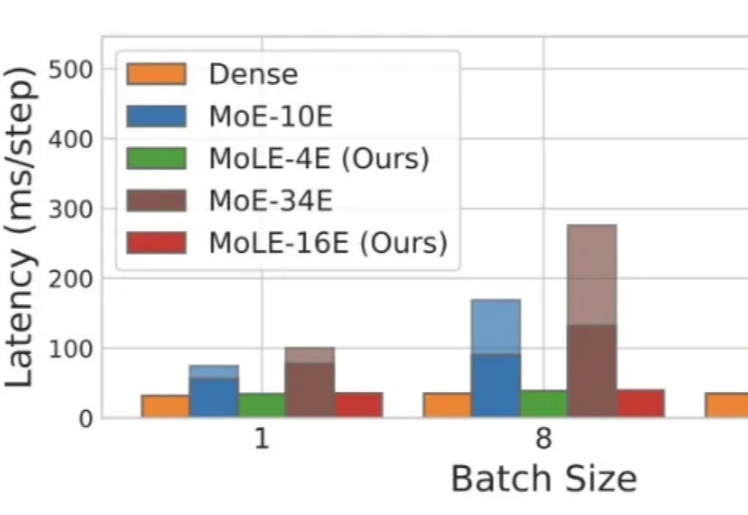
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
他们打造的端侧大模型已经可以在树莓派这样的微型设备上流畅运行,首批搭载Yan架构大模型的具身智能机器人也已经面世。当下AI算力竞赛愈演愈烈之际,他们的“低算力”“群体智能”之路正在获得更多关注。本期「大模型创新架构」主题访谈,量子位邀请到RockAI CEO刘凡平,聊聊他们选择非Transformer架构路线背后的故事,以及通过架构及算法创新实现AGI的技术愿景。