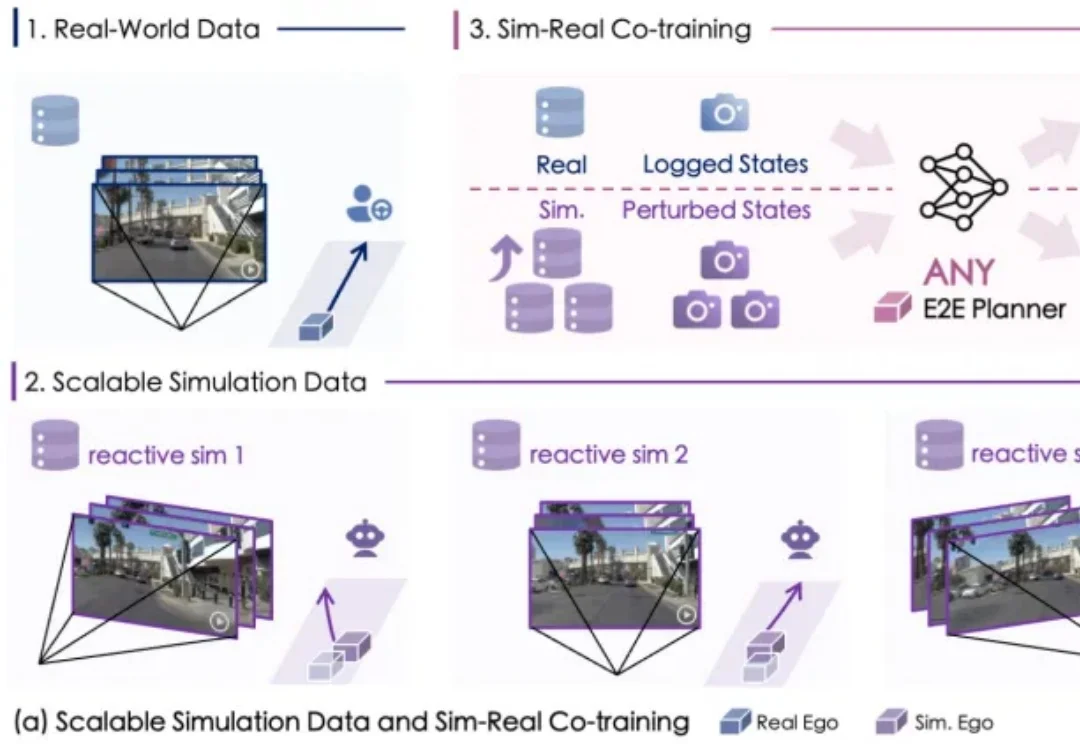
仿真数据也能Scaling!虚实结合训练,端到端性能全面提升|中科院x港大x小米汽车
仿真数据也能Scaling!虚实结合训练,端到端性能全面提升|中科院x港大x小米汽车自动驾驶数据荒怎么破?
来自主题: AI技术研报
7769 点击 2025-12-11 10:10
 搜索
搜索
自动驾驶数据荒怎么破?

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。

当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。

中科大 LDS 实验室何向南、王翔团队与 Alpha Lab 张岸团队联合开源 MiniOneRec,推出生成式推荐首个完整的端到端开源框架,不仅在开源场景验证了生成式推荐 Scaling Law,还可轻量复现「OneRec」,为社区提供一站式的生成式推荐训练与研究平台。
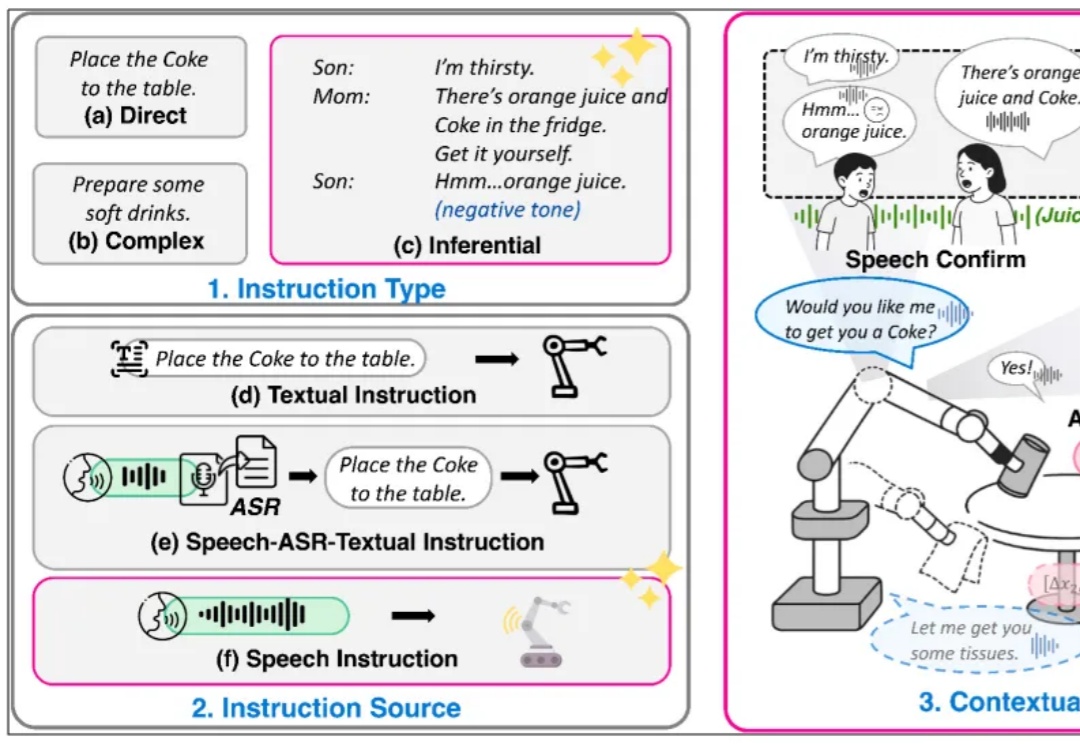
复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。

近期,Google DeepMind 发布新一代具身大模型 Gemini Robotics 1.5,其核心亮点之一便是被称为 Motion Transfer Mechanism(MT)的端到端动作迁移算法 —— 无需重新训练,即可把不同形态机器人的技能「搬」到自己身上。不过,官方技术报告对此仅一笔带过,细节成谜。
大语言模型(LLM)的「炼丹师」们,或许都曾面临一个共同的困扰:为不同任务、不同模型手动调整解码超参数(如 temperature 和 top-p)。这个过程不仅耗时耗力,而且一旦模型或任务发生变化,历史经验便瞬间失效,一切又得从头再来。
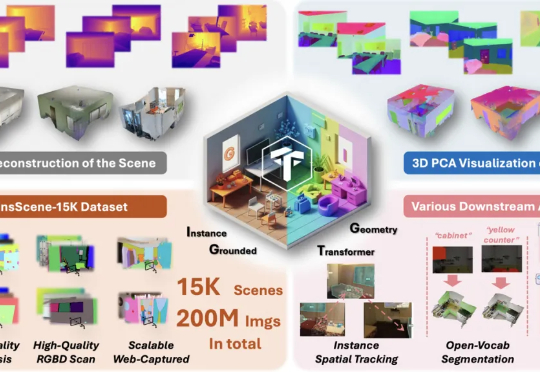
现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。