32B逆袭GPT-5.2:首个端到端GPU编程智能体框架StitchCUDA问世
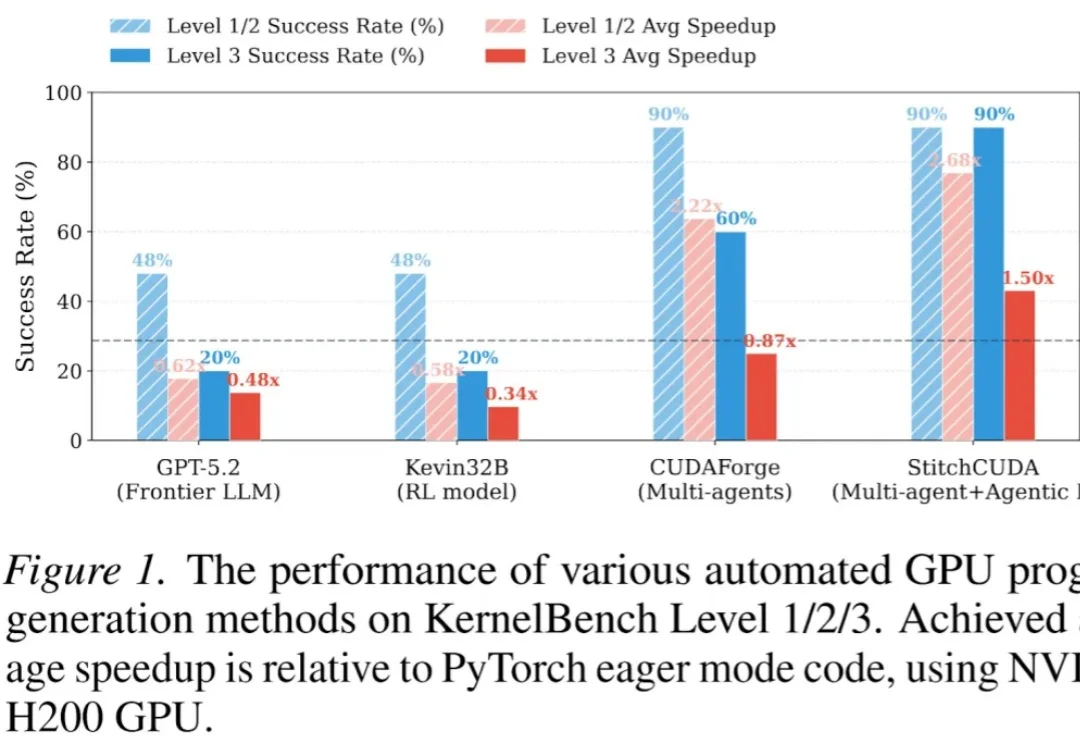
32B逆袭GPT-5.2:首个端到端GPU编程智能体框架StitchCUDA问世现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
来自主题: AI技术研报
8479 点击 2026-03-05 14:28
 搜索
搜索
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
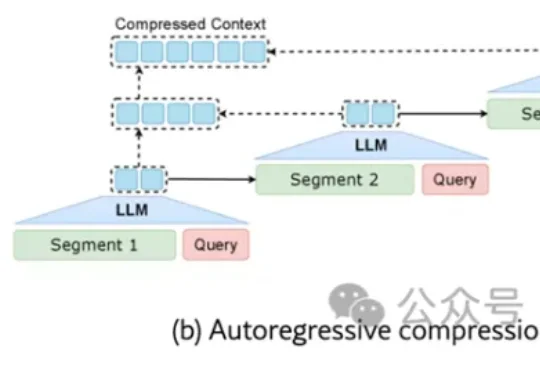
来自清华大学、鹏城实验室与阿里巴巴未来生活实验室的联合研究团队发现:现有任务相关的压缩方法不仅陷入效率瓶颈——要么一次性加载全文(效率低),要么自回归逐步压缩(速度慢),更难以兼顾“保留关键信息”与“保持自然语言可解释性”。
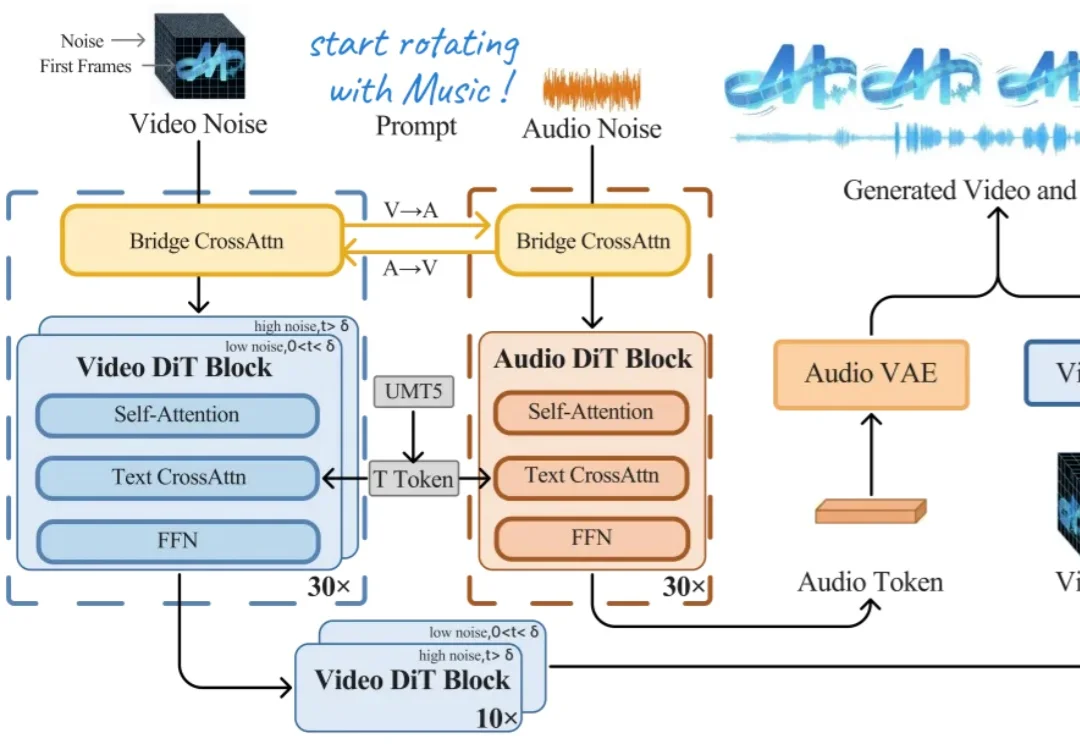
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
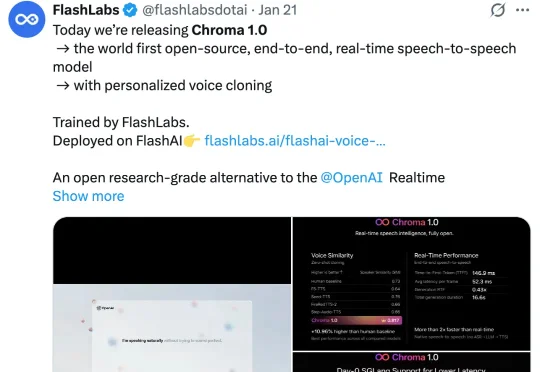
近期,FlashLabs 发布并开源了其实时语音模型 Chroma 1.0,其定位为全球首个开源的端到端语音到语音模型。Chroma 1.0 发布之后,便在社媒爆火,吸引了大量的关注。X 上的官推帖子已经突破了百万浏览量。
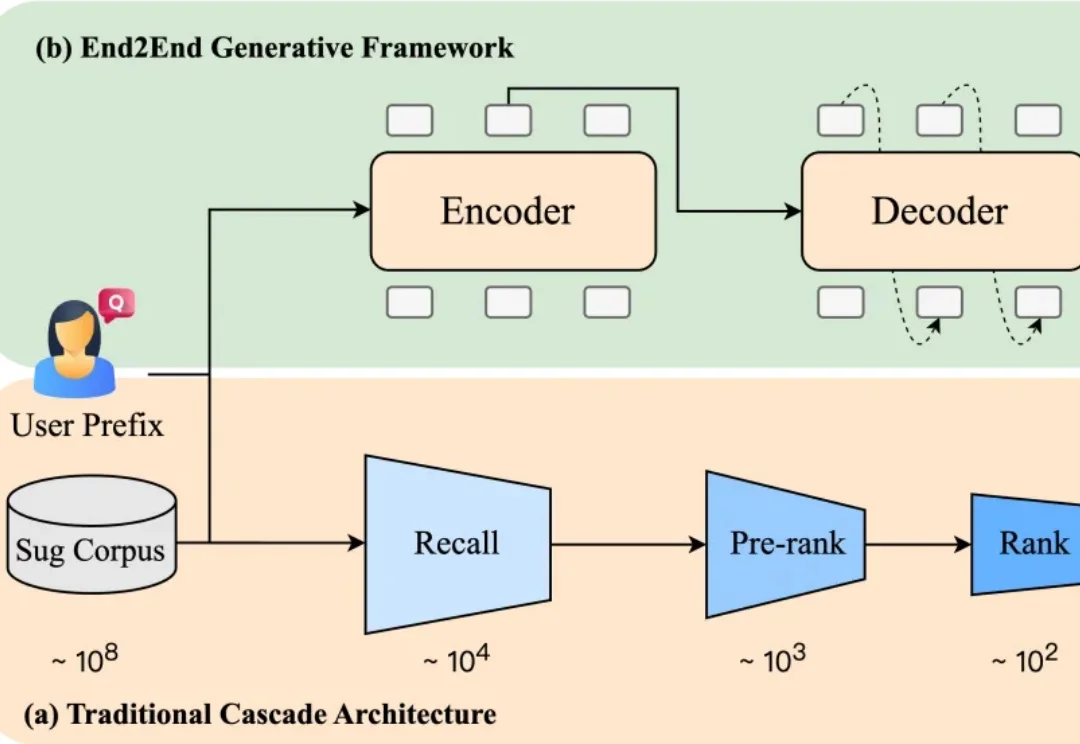
当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?或者直接跳到某个品牌旗舰店?短短一个词,背后承载了完全不同的购买意图。而推荐是否精准,直接影响用户的搜索体验,也影响平台的转化效率。
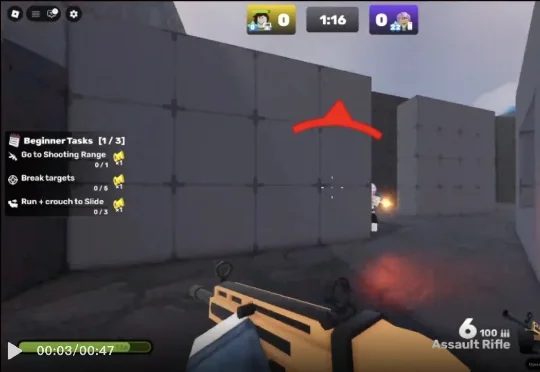
来自 Player2 的研究员们提出了 Pixel2Play(P2P)模型,该模型以游戏画面和文本指令作为输入,直接输出对应的键盘与鼠标操作信号。在消费级显卡 RTX 5090 上,P2P 可以实现超过 20Hz 的端到端推理速度,从而能够真正像人类一样和游戏进行实时交互。P2P 作为通用游戏基座模型,在超过 40 款游戏、总计 8300 + 小时的游戏数据上进行了训练,
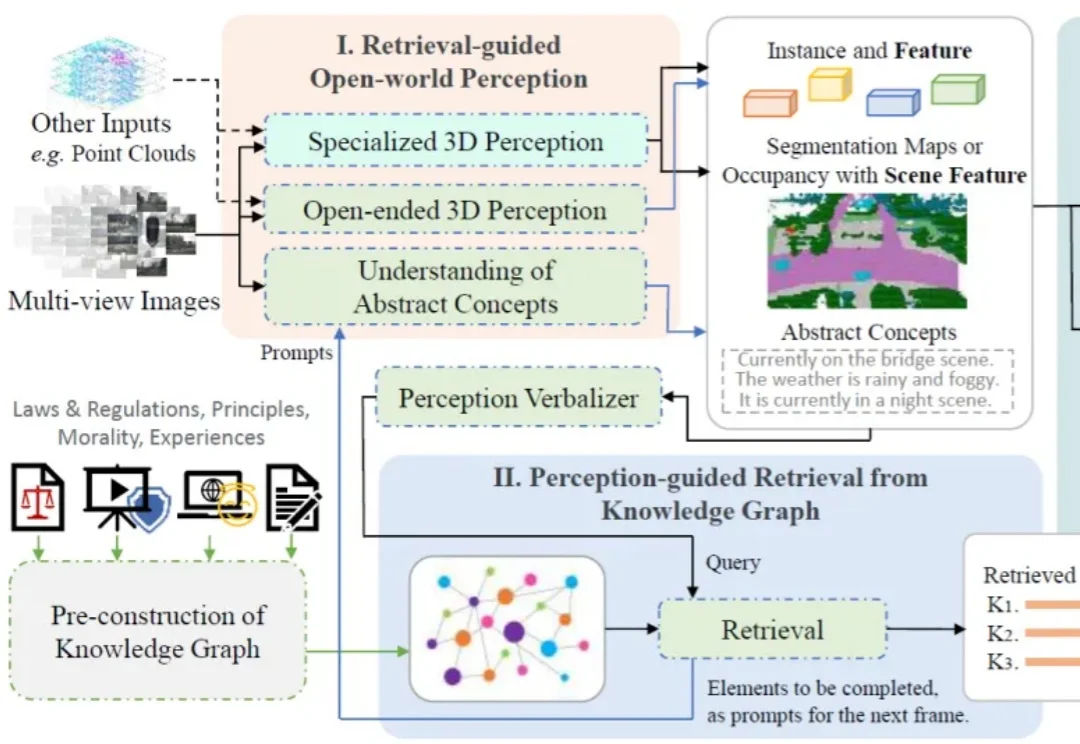
一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?

未来不远(Futuring Robot)正式宣布完成 2 亿元的天使轮融资,目前已经完成家庭通用机器人领域端到端模型落地,真实家庭实测,C 端商业化等重大阶段。

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
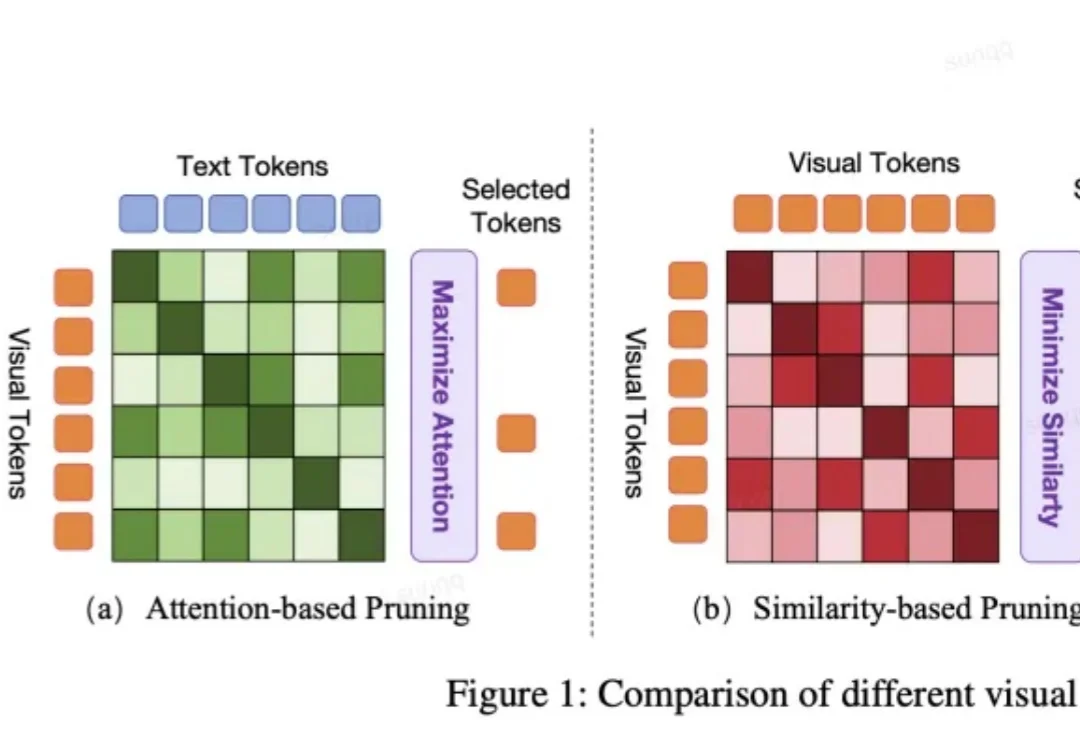
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。