MiniCPM-o 4.5 技术报告发布:全双工全模态 API 开放,RTX5070即可实时运行
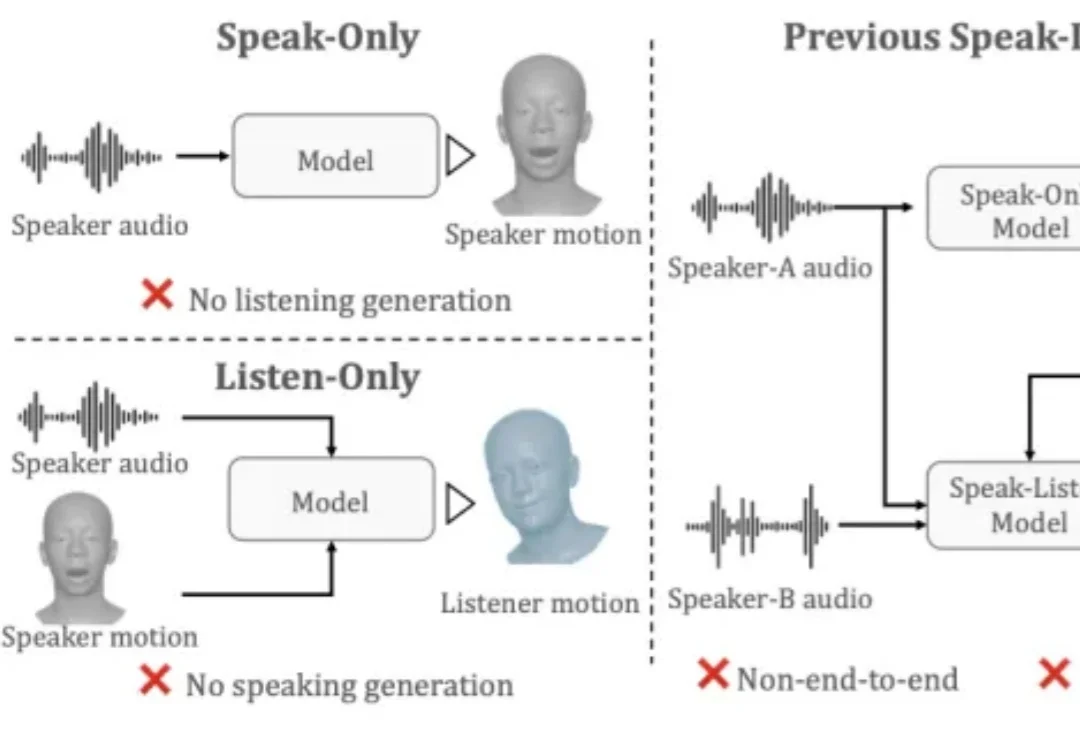
MiniCPM-o 4.5 技术报告发布:全双工全模态 API 开放,RTX5070即可实时运行你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。其自 2026 年 2 月模型发布以来,在 Hugging Face 上的下载量已突破 25 万+。
来自主题: AI技术研报
7203 点击 2026-04-28 13:15