# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文的共同第一作者为新加坡国立大学博士生陈浩楠,新加坡国立大学硕士生郭京翔。合作者为汪邦骏、张添睿、黄叙川、郑博仁、侯懿文、铁宸睿、邓家俊。通讯作者为新加坡国立大学计算机学院助理教授邵林,研究方向为机器人和人工智能。
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
另一方面,分层 VLA 模型试图通过引入视觉语言模型(VLM)作为高层规划器来缓解数据依赖,但其生成的中间表示(如语言描述 [3]、关键点 [4] 或价值图 [5])往往缺乏复杂操作所需的精确几何细节,或者需要底层策略进行额外的动作数据训练。
为了突破这一瓶颈,来自新加坡国立大学(NUS)的邵林团队提出了一种全新的解耦式分层框架 —— Goal-VLA。该研究创新性地将图像生成式 VLM 作为 “以物体为中心的世界模型”,在无需任何任务特定微调和成对动作数据的情况下,实现了强大的零样本机器人操作能力。
目前,该论文已被机器人领域顶级会议 IEEE International Conference on Robotics & Automation(ICRA 2026)接收。
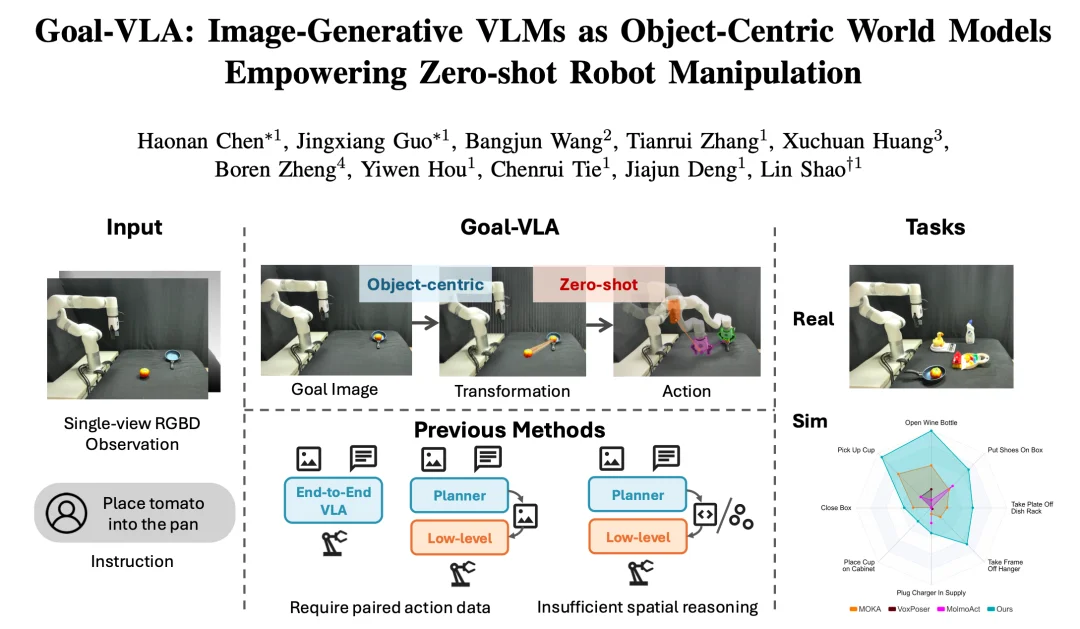
Goal-VLA 的核心洞察是使用物体目标状态表示来连接高层语义推理与底层动作控制。
与受限于特定机器人运动学的传统智能体中心(Agent-centric)世界模型不同,Goal-VLA 的世界模型聚焦于图像空间中的语义目标,即需要操作的物体的目标位姿。这使得系统可以将高层规划与底层控制彻底解耦:高层 VLM 提供泛化性极强的视觉目标,专门的空间基准模块将其转化为明确的空间指导,最终由免训练的底层策略完成物理执行。整个框架仅需用户的自然语言指令和单视角 RGB-D 图像即可运行,无需预先扫描地图或已知物体网格。
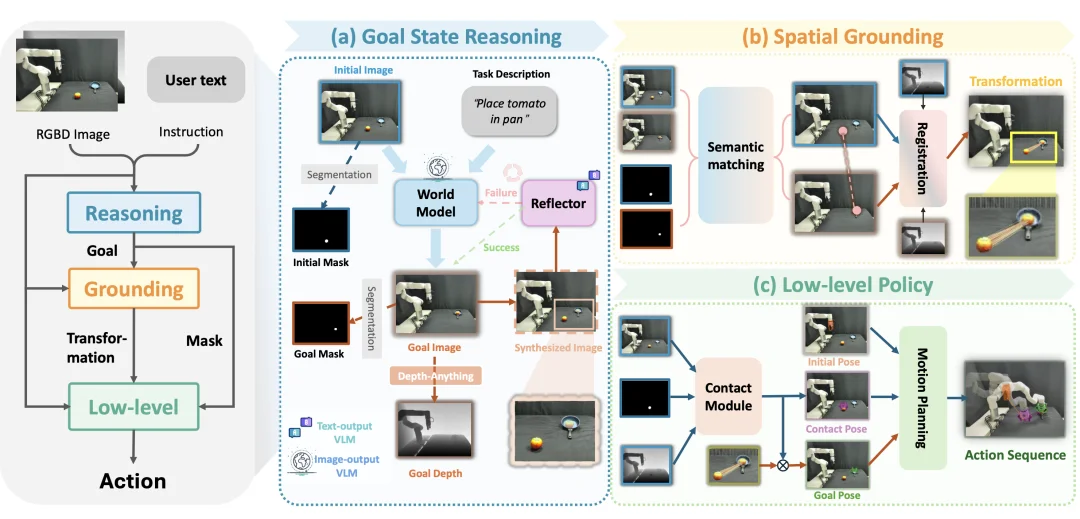
Goal-VLA 的执行流程分为三个关键阶段:
1. 目标状态推理(Goal State Reasoning)
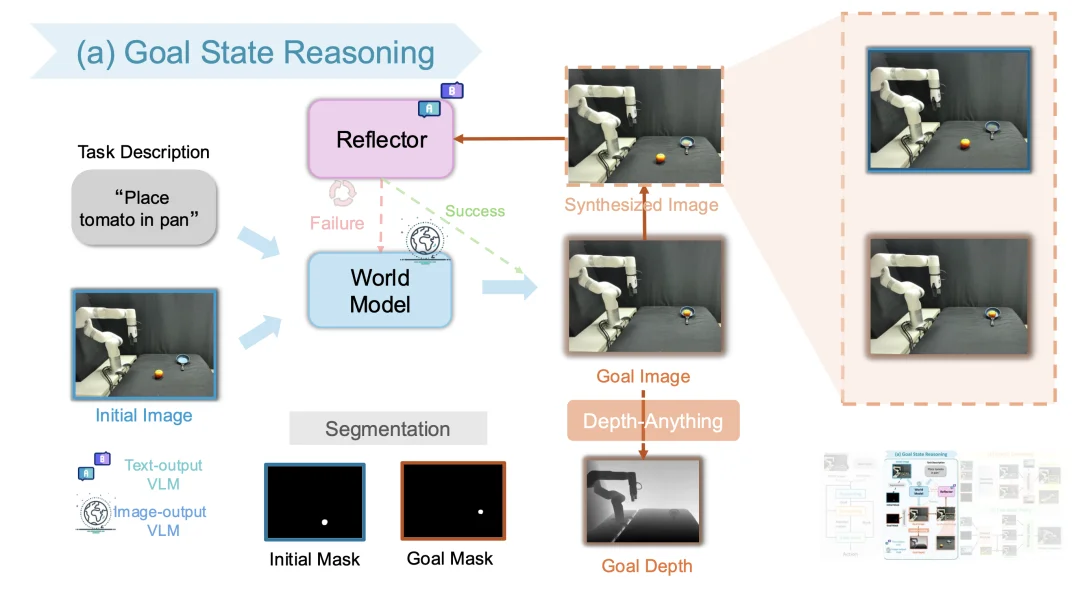
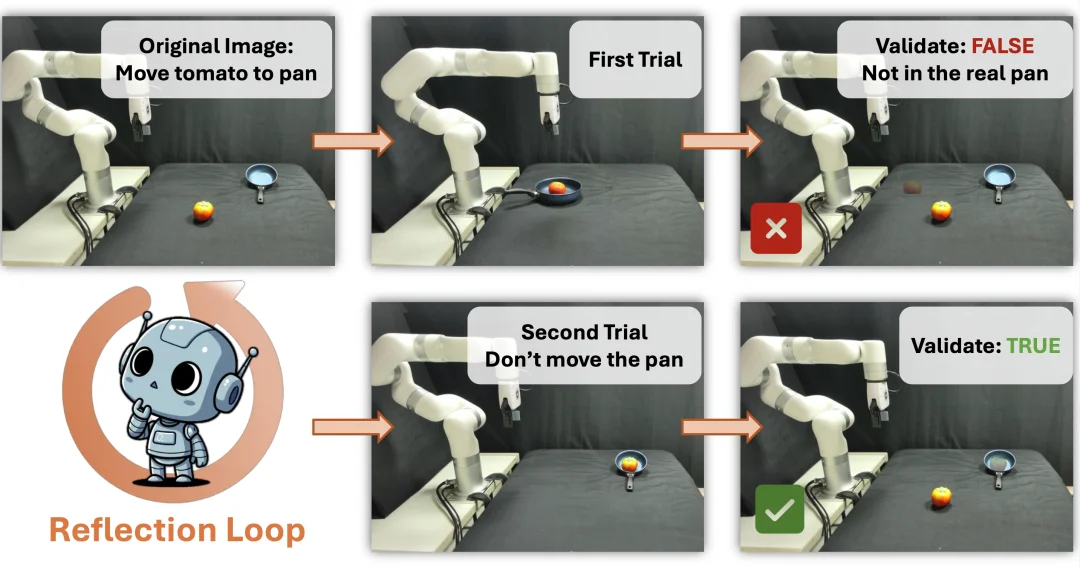
该模块负责将用户抽象的自然语言指令转化为具体且合理的视觉目标。系统首先利用文本 VLM 丰富用户的简短指令,将简短指令转化为包含丰富细节的提示词。 图像生成 VLM(Gemini 2.5 Flash-image)据此生成候选目标图像。为了解决生成图像可能存在的物理或语义不合理性,研究团队提出了一种迭代的 “合成 - 反思”(Reflection-through-Synthesis)机制。为了让验证模型能够清晰地评估该图像的物理可行性,系统使用 Grounded SAM [6] 从候选图像中分割出目标物体,并将其作为 “虚拟目标” 半透明地叠加到初始场景图像上。评估模型(Reflector VLM)对合成图像进行审查。若生成的图像不符合任务语义(例如目标物体的位置不可达或者错误),Reflector 会输出包含纠正反馈的修改提示,指导生成器重新生成,直至目标图像被验证通过 或者达到最大迭代次数。
2. 空间基准计算(Spatial Grounding)
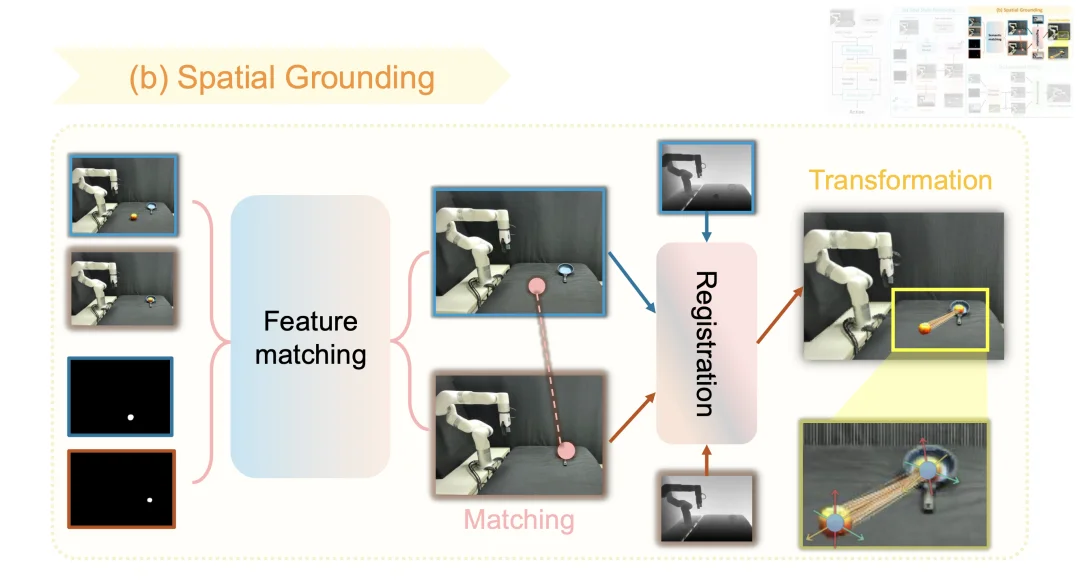
该模块负责将 2D 视觉目标转化为精确的 3D 空间变换。由于生成的目标图像在实例级外观上可能存在偏差,传统的光流估计容易失效。为了解决这个问题,Goal-VLA 提取像素级语义特征,通过计算相似度来建立初始帧与目标帧之间的像素匹配。结合初始真实深度图与目标预测深度图(使用 Depth Anything V2 [7] 估计并经深度对齐校准),系统将 2D 像素提升为 3D 点云 ,并使用 Umeyama 算法 [8] 求解出最优的旋转(Rotation)和平移(Translation)矩阵。
3. 底层策略(Low-level Policy)
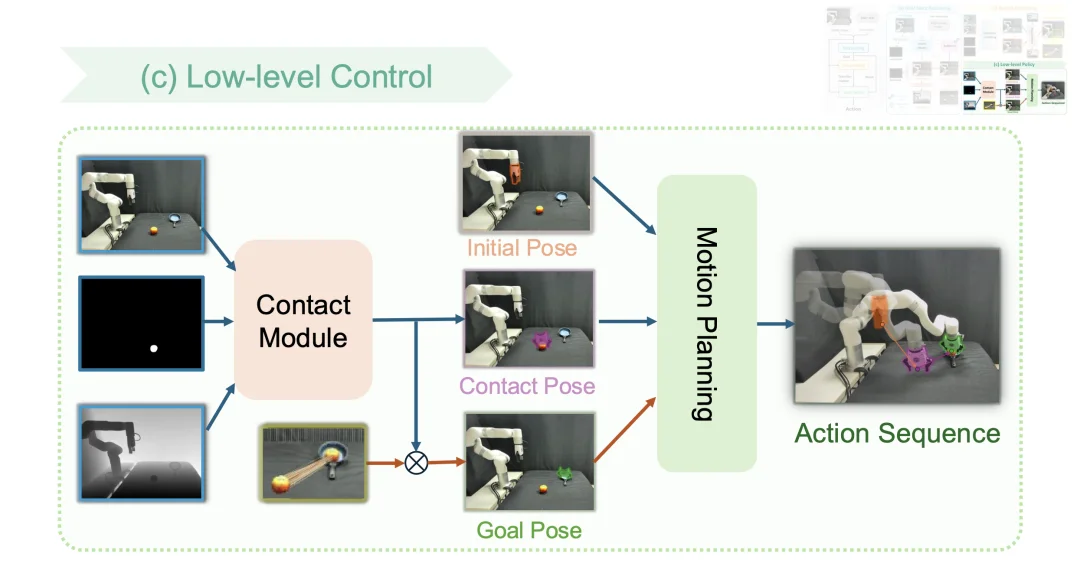
底层策略将高层提供的物体目标位姿转化为可执行动作。接触模块在物体点云表面采样,并筛选出无碰撞的最优接触位姿(例如抓取的姿态)。系统假设抓取后夹爪与物体的相对位姿保持不变,将空间基准模块计算出的物体变换矩阵应用于夹爪,推导出最终的目标位姿。最后,运动规划器(Motion Planning Module)生成从当前构型到目标位姿的无碰撞轨迹,完成任务执行。
研究团队在 RLBench [9] 仿真环境(8 个任务)和真实的 UFACTORY X-ARM 7 机械臂(4 个任务)上进行了广泛的评估。所有评估均在严格的零样本设定下进行。
仿真环境基准测试 (RLBench)
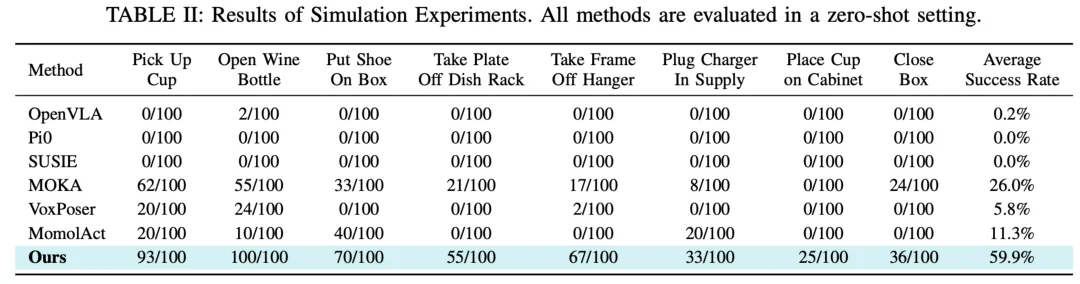
在 RLBench 的 8 个涵盖抓取、放置、插拔等复杂技能的任务中(每个任务测试 100 次),Goal-VLA 展现了显著的性能提升,实现了 59.9% 的平均成功率。相比之下,基于关键点的分层模型 MOKA [4] 仅为 26.0%。而严重依赖带有动作成对数据的端到端模型 OpenVLA [2] 和 Pi0 [10],在未经过微调的零样本测试中几乎完全失败。
真实世界机械臂实验

研究团队使用 7-DOF UFACTORY X-ARM 7 机械臂测试了 4 个具有挑战性的物理任务:番茄入锅(测试包含关系的推理)、桌面清扫(测试工具使用和间接操作)、精确称重(测试高精度放置)以及直立瓶子(测试姿态重定向)。
Goal-VLA 达到了 60% 的平均成功率,远超其他基线方法。这一结果证明了 Goal-VLA 生成显式 3D 目标位姿的策略,能够为真实世界中的复杂操作提供精确的空间指导。
仿真环境与真实实验共同证明,Goal VLA 框架能够实现跨物体、跨环境、跨任务和跨本体的零样本执行能力。
消融实验
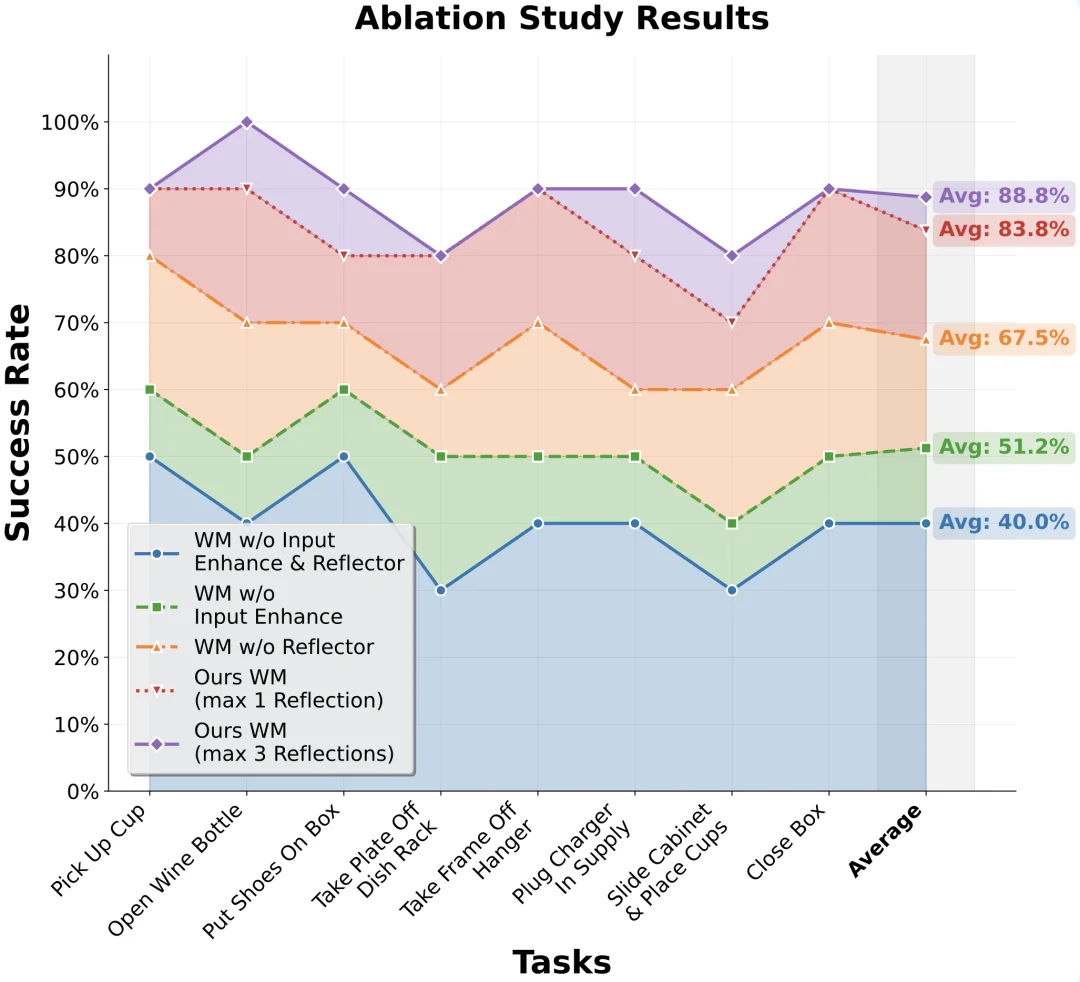
研究团队对高层推理模块进行了消融分析。单独增加输入提示词增强(Input Enhancement)带来了 27.5% 的成功率提升。而完整的 “合成 - 反思” 循环机制,将模型的基础成功率从 40.0% 跃升至 83.8%,当允许最大 3 次反思迭代时,成功率进一步攀升至 88.8%。这证明了视觉反馈和自我纠正在图像生成过程中的必要性。
Goal-VLA 为解决机器人操作泛化难题提供了一种具有高度启发性的解耦范式。其核心贡献在于:
参考文献
[1] Zitkovich, Brianna, et al. "Rt-2: Vision-language-action models transfer web knowledge to robotic control." Conference on Robot Learning. PMLR, 2023.
[2] Kim, Moo Jin, et al. "Openvla: An open-source vision-language-action model." arXiv preprint arXiv:2406.09246 (2024).
[3] Ahn, Michael, et al. "Do as i can, not as i say: Grounding language in robotic affordances." arXiv preprint arXiv:2204.01691 (2022).
[4] Liu, Fangchen, et al. "Moka: Open-world robotic manipulation through mark-based visual prompting." arXiv preprint arXiv:2403.03174 (2024).
[5] Huang, Wenlong, et al. "Voxposer: Composable 3d value maps for robotic manipulation with language models." arXiv preprint arXiv:2307.05973 (2023).
[6] Ren, Tianhe, et al. "Grounded sam: Assembling open-world models for diverse visual tasks." arXiv preprint arXiv:2401.14159 (2024).
[7] Yang, Lihe, et al. "Depth anything v2." Advances in Neural Information Processing Systems 37 (2024): 21875-21911.
[8] Umeyama, Shinji. "Least-squares estimation of transformation parameters between two point patterns." IEEE Transactions on pattern analysis and machine intelligence 13.4 (2002): 376-380.
[9] James, Stephen, et al. "Rlbench: The robot learning benchmark & learning environment." IEEE Robotics and Automation Letters 5.2 (2020): 3019-3026.
[10] Black, Kevin, et al. "$\pi_0 $: A Vision-Language-Action Flow Model for General Robot Control." arXiv preprint arXiv:2410.24164 (2024).
文章来自于"机器之心",作者 "陈浩楠"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
