项目陷入停滞、算力明争暗斗,5000亿美元的「星际之门」何去何从?
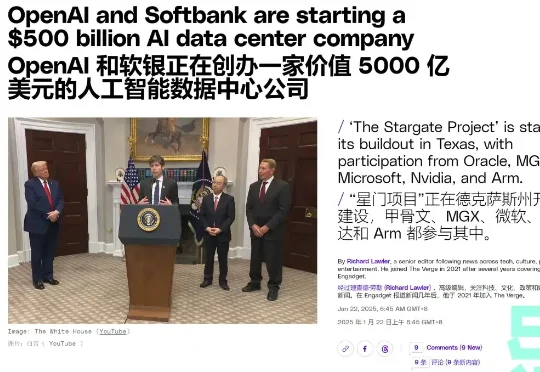
项目陷入停滞、算力明争暗斗,5000亿美元的「星际之门」何去何从?去年 1 月底,在一次白宫新闻发布会上,特朗普和 OpenAI CEO Sam Altman、软银 CEO 孙正义等人联合宣布了一个名为「星际之门」(Stargate Project)的人工智能项目。
来自主题: AI资讯
9603 点击 2026-02-24 09:16
 搜索
搜索
去年 1 月底,在一次白宫新闻发布会上,特朗普和 OpenAI CEO Sam Altman、软银 CEO 孙正义等人联合宣布了一个名为「星际之门」(Stargate Project)的人工智能项目。

硅谷最离谱宫斗:Ilya因嫉妒Jakub的「震撼突破」而点燃OpenAI火药桶,奥特曼被董事会踢出,引发高管离职潮。算力不足和预算挤压是根源,2026年文件曝光后,Ilya「塌房」。
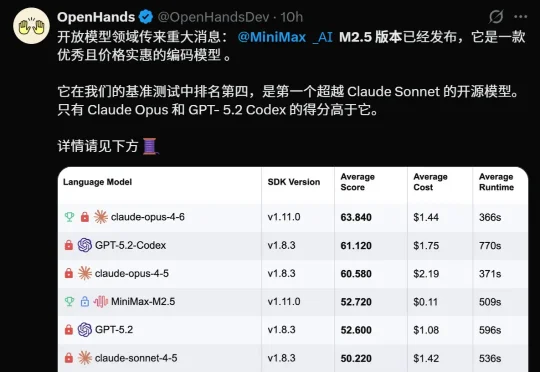
开源模型新王 MiniMax M2.5 震撼降临:M2.5 编码性能逼平 Claude Opus 4.6,价格却只有 1/20;1 美金 / 小时,这种尺寸和性能的模型,才能在算力短缺的时代不降智不卡顿,持续提供最好体验,成为最终王者!

随着豆包大模型和seedance视频生成模型等业务的爆发,自研芯片成功后,字节有望大大降低其算力成本。

思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!

Contrary 是一家成立于 2018 年的美国风险投资公司,由 Eric Tarczynski 创办,自成立以来,其以“人才驱动+研究驱动”为核心方法论,在全球顶级高校铺设了庞大的人才网络,通过识别最优秀的年轻技术人才来发现投资机会。
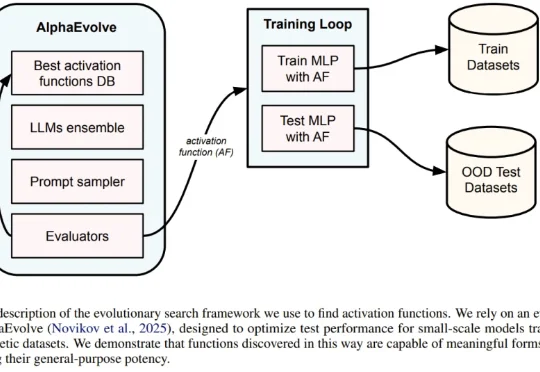
一直以来,神经网络的激活函数就像是 AI 引擎中的火花塞。从早期的 Sigmoid、Tanh,到后来统治业界的 ReLU,再到近年来的 GELU 和 Swish,每一次激活函数的演进都伴随着模型性能的提升。但长期以来,寻找最佳激活函数往往依赖于人类直觉或有限的搜索空间。

昨日,由中科曙光提供的3套scaleX万卡超集群系统,在国家超算互联网核心节点同时上线试运行。这是国内第一次在国家级算力枢纽节点上,同步部署并实际投入运营3套万卡级AI超集群,一举成为全国首个实现超3万卡部署、且已进入实际运营阶段的最大国产AI算力池。

Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!

为了给OpenAI凑齐3000亿美金的算力投名状,硅谷老教父Larry Ellison杀疯了!3万名员工集体祭天,283亿美金买回来的医疗巨头Cerner直接送上拍卖台。为了买显卡,甲骨文正在自残?