
给AI做微创手术:哈工大博士生发明新算法,5分钟让大模型减重近半
给AI做微创手术:哈工大博士生发明新算法,5分钟让大模型减重近半作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。
来自主题: AI技术研报
7890 点击 2025-12-31 08:30
 搜索
搜索
作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。

在国内,懂技术 —— 尤其是 AI 技术的年轻人,真的不缺崭露头角的机会。

他们不光能造GPU,还能写出全球顶级的算法!摩尔线程这次开源给国产具身智能递了一把「神兵利器」。

大模型时代,基础模型卷到飞起,参数规模爆炸再爆炸,但谈到落地应用,产业端反馈出的问题依然明显:
马斯克的Grok这两天再次大规模「翻车」,在邦迪海滩枪击案等重大事件中胡言乱语,将救人英雄误认为修树工人和以色列人质,甚至混淆枪击与气旋。这不仅是技术故障,更暴露了生成式AI在处理实时信息时致命的 「幻觉」 缺陷。当算法开始编造现实,我们该如何守住真相的底线?

“人工智能要发展到下一个台阶,一定要突破两座大山。第一座大山是Transformer,第二座大山是反向传播算法。”在大模型规模不断拔高、算力与数据卷到极致的当下,RockAI创始人刘凡平提出了一个与主流共识截然不同的判断。

AI领域共分成四个层次:AI技术应用、AI的算法算力、AI的体系架构、AI哲学。其中,「AI哲学」超越AI技术应用、算法算力、体系架构,属于最顶层阶段——「形而下者谓之器、形而上者谓之道」,将超越AI的「器」、「技」、「法」、「术」层面,上升到AI更高的「道」的层面。
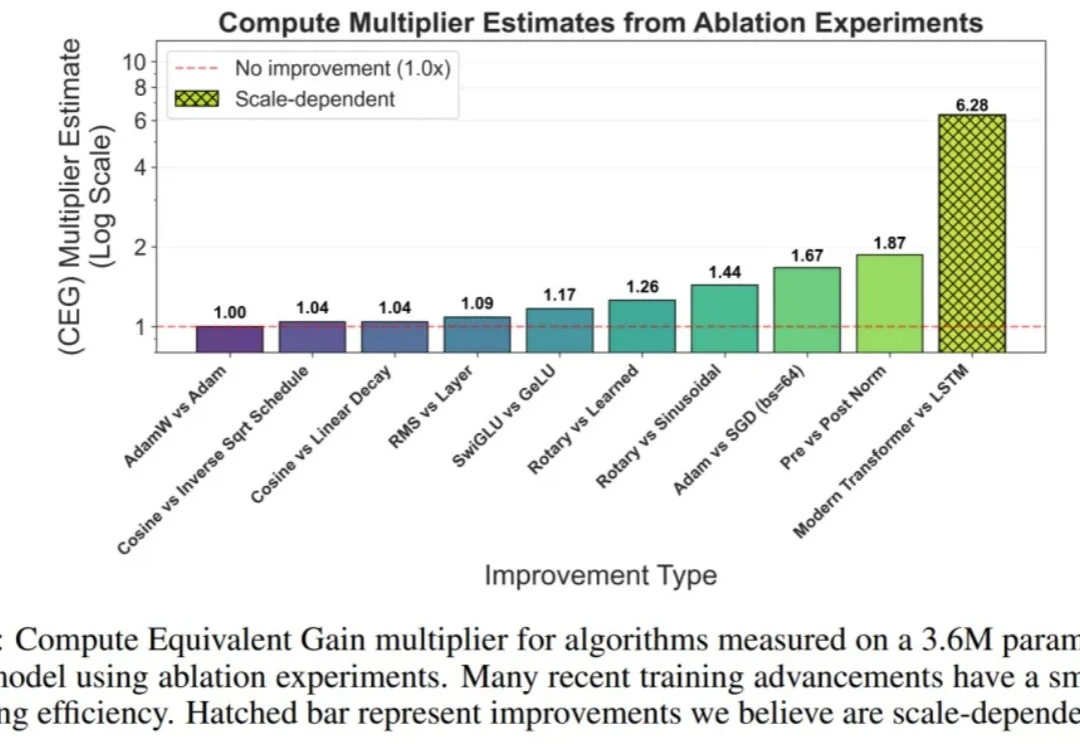
在过去十年中,AI 的进步主要由两股紧密相关的力量推动:迅速增长的计算预算,以及算法创新。

当AI不再仅仅是渲染队列中的一个工具,而是开始以智能体的身份,深度参与到剧本构思、视觉预览乃至最终剪辑的每一个环节,我们正站在一场影像文明变革的临界点。

几个小时前,NVIDIA CUDA Toolkit 13.1 正式发布,英伟达官方表示:「这是 20 年来最大的一次更新。」CUDA Tile 是 NVIDIA CUDA Toolkit 13.1 最核心的更新。它是一种基于 tile 的编程模型,能够以更高的层次编写算法,并抽象化专用硬件(例如张量核心)的细节。