
腾讯悄悄上线了他们第一个设计Agent - Miora。
腾讯悄悄上线了他们第一个设计Agent - Miora。腾讯的设计Agent平台Miora,今天终于全面开放了。之前一直需要邀请码,还得预约排队,而今天,终于正式全量上线。别的不说,你永远可以相信腾讯的产品设计和审美。网址在此:miora.design
来自主题: AI资讯
8126 点击 2026-07-22 14:09
 搜索
搜索
腾讯的设计Agent平台Miora,今天终于全面开放了。之前一直需要邀请码,还得预约排队,而今天,终于正式全量上线。别的不说,你永远可以相信腾讯的产品设计和审美。网址在此:miora.design
今天,腾讯正式发布了其首个研究智能体(Research Agent)——Hyra(Hunyuan Research Agent)。Hyra能够像科研人员一样,提出假设、完成实验、总结经验,再基于经验不断提出新的方案,最终实现递归自我改进(Recursive Self-Improvement,RSI)。
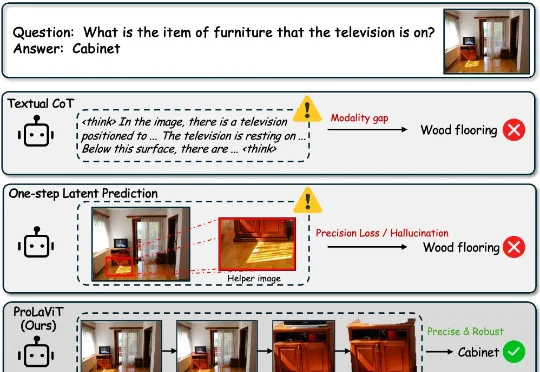
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。
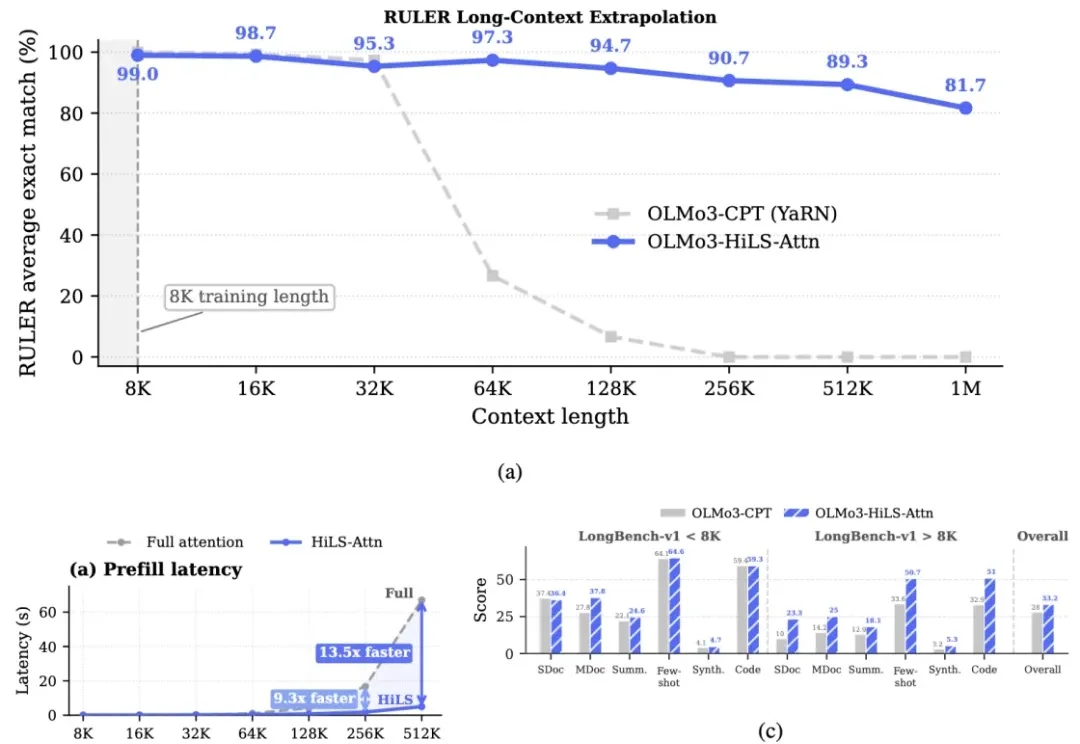
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

谈应用宝如何判断“分发”和“端侧”。

7月17日晚,在2026世界人工智能大会(WAIC)举办期间,由腾讯新闻、腾讯科技主办,腾讯华东总部、腾讯云智能特别支持的“腾讯WAIC之夜”在上海举行。腾讯新闻负责人何毅进在活动现场发表致辞。
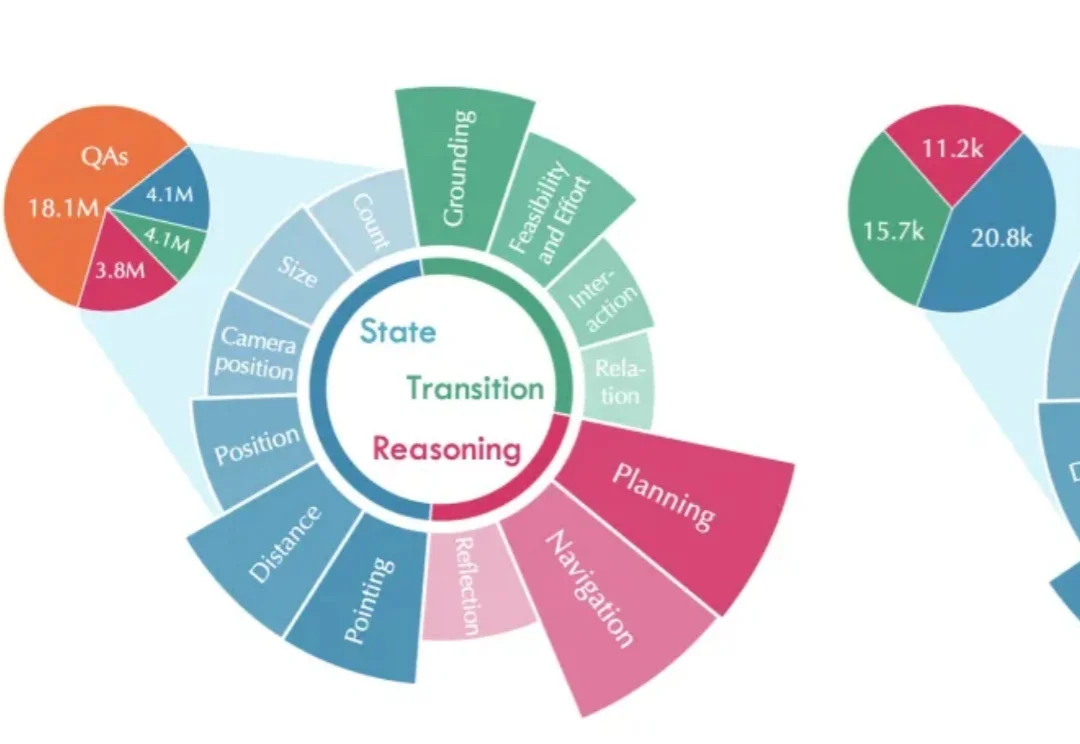
7 月 15 日,腾讯 Robotics X 实验室以及福田实验室联合腾讯混元推出两款具身智能基座模型 —— 具身 VLM 基座模型 Hy-Embodied-VLM-1.0 以及 具身世界认知基座模型 Hy-Embodied-RxBrain-1.0,不仅让具身大脑能够 “看” 懂现实世界,还学会同时推理和想象。
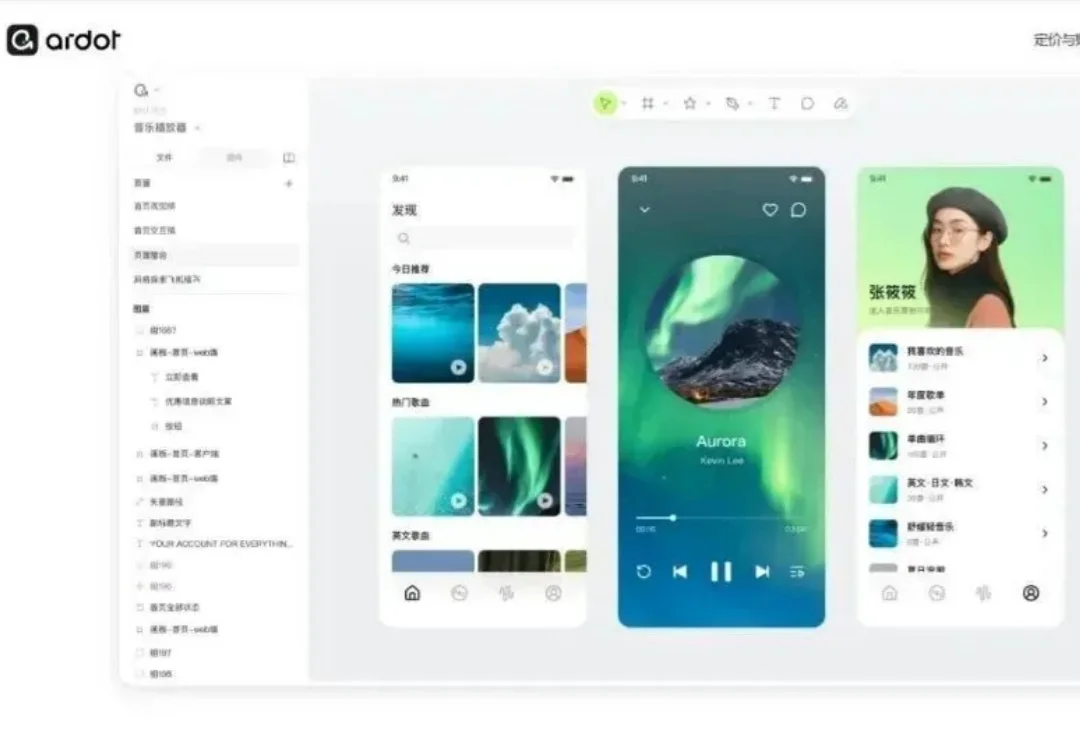
几乎所有 AI 设计工具都卡在同一个地方:它们很会生成,但不太会交付。

7月6日,腾讯混元Hy3正式版发布。
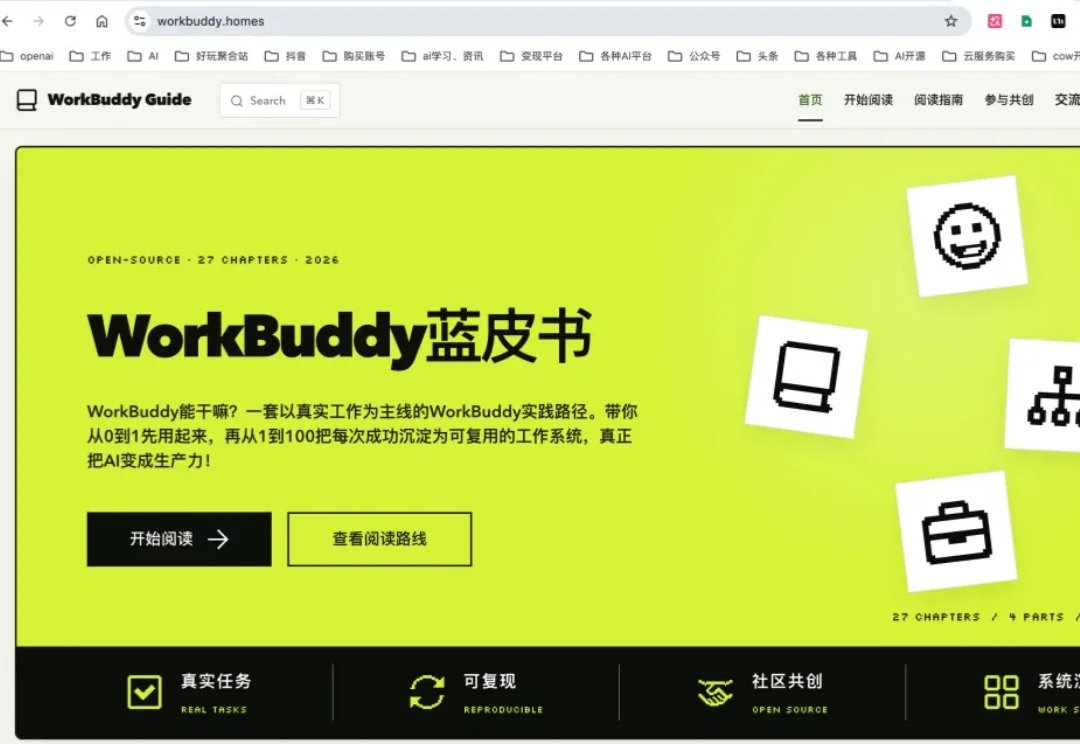
把腾讯WorkBuddy用透,你26年下半年会轻松很多。