Lumina-mGPT 2.0:自回归模型华丽复兴,媲美顶尖扩散模型
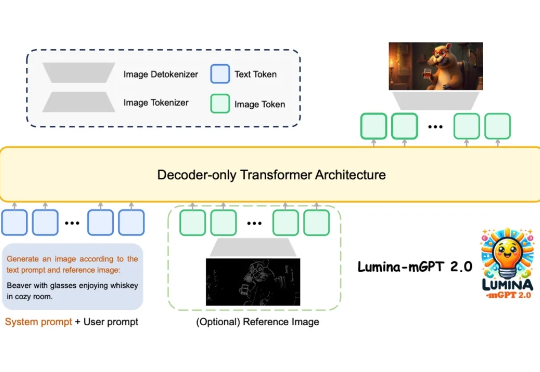
Lumina-mGPT 2.0:自回归模型华丽复兴,媲美顶尖扩散模型上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。
来自主题: AI技术研报
8695 点击 2025-08-12 17:03
 搜索
搜索
上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。
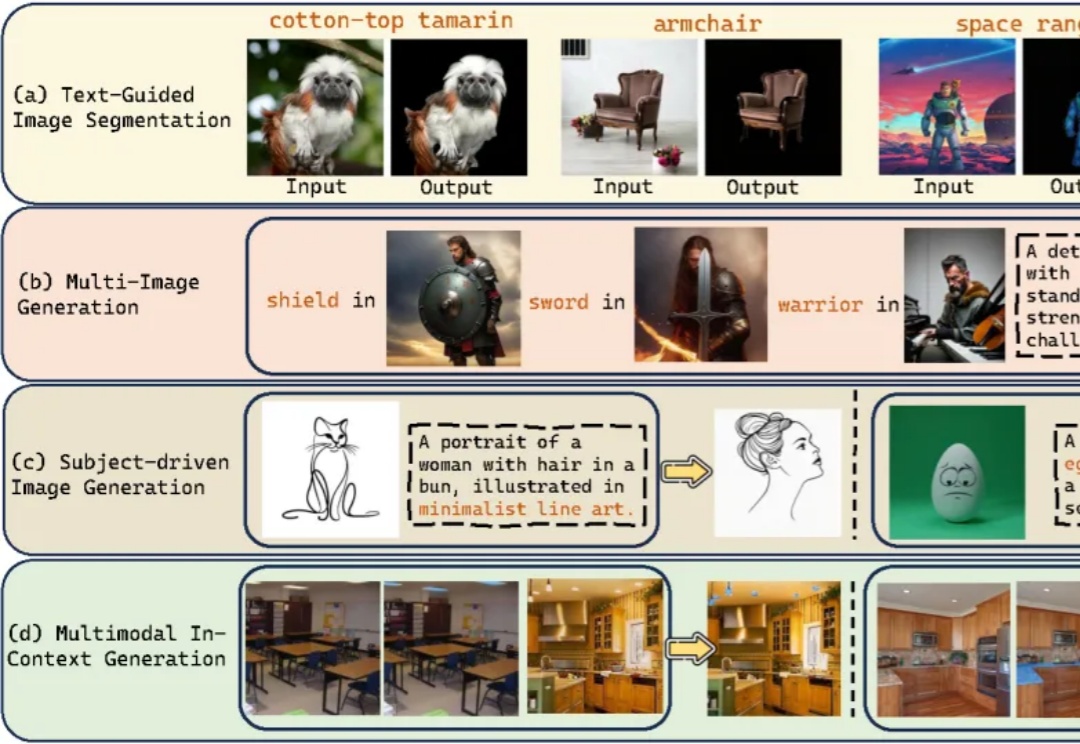
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。
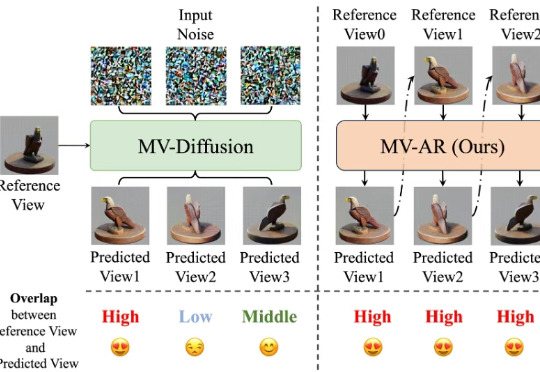
本文介绍并开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。
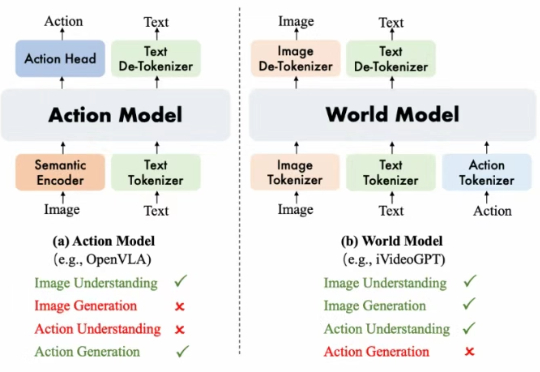
阿里巴巴达摩院提出了 WorldVLA, 首次将世界模型 (World Model) 和动作模型 (Action Model/VLA Model) 融合到了一个模型中。WorldVLA 是一个统一了文本、图片、动作理解和生成的全自回归模型。
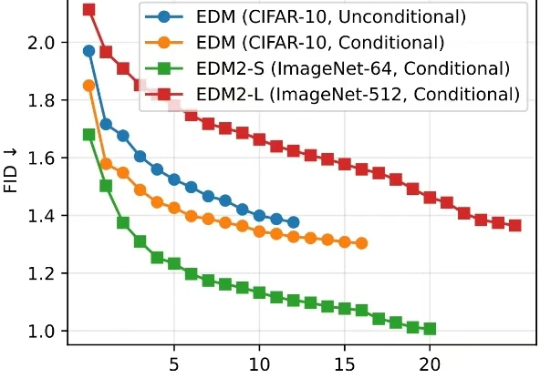
清华大学朱军教授团队与 NVIDIA Deep Imagination 研究组联合提出一种全新的视觉生成模型优化范式 —— 直接判别优化(DDO)。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。
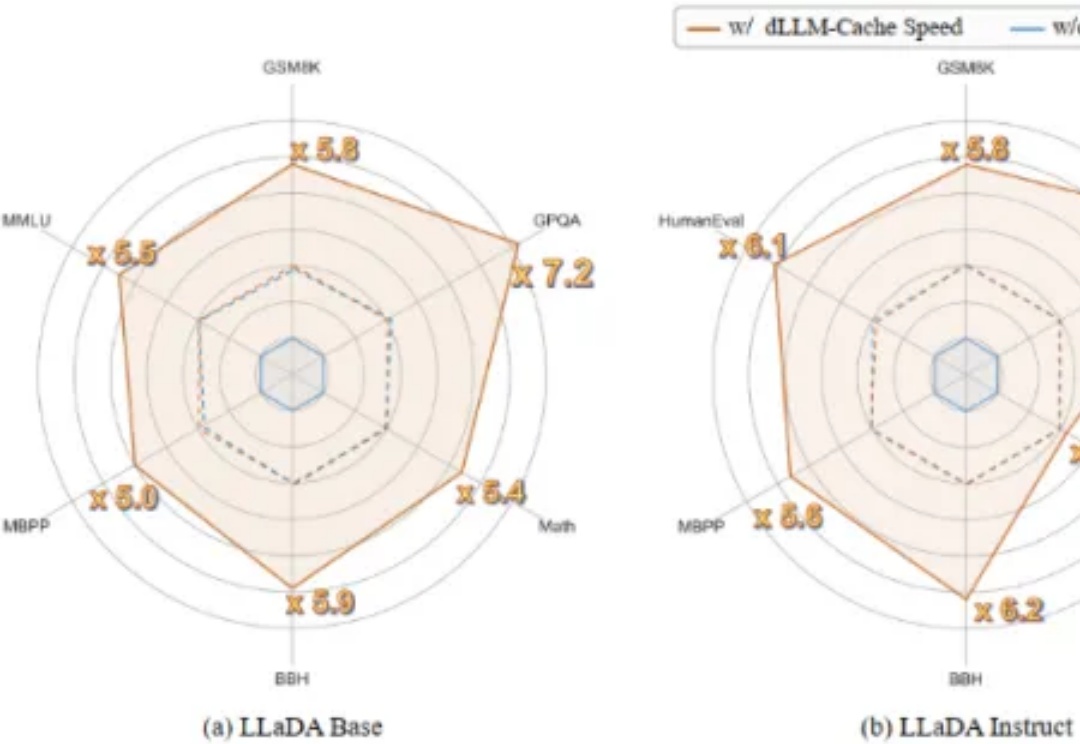
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
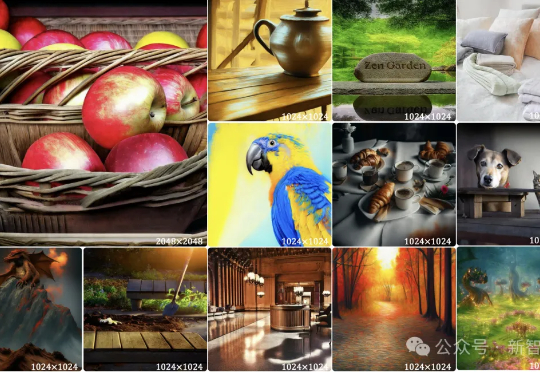
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。