
老黄杀入OpenClaw战场!最强开源「龙虾」模型直逼Opus 4.6
老黄杀入OpenClaw战场!最强开源「龙虾」模型直逼Opus 4.6OpenClaw又迎重磅玩家!英伟达深夜带着Nemotron 3 Super炸场,1200亿参数专为Agent打造,性能直逼Claude Opus 4.6。推理狂飙3倍,吞吐量猛涨5倍,「龙虾」这是要上天了。
来自主题: AI技术研报
9364 点击 2026-03-12 14:54
 搜索
搜索
OpenClaw又迎重磅玩家!英伟达深夜带着Nemotron 3 Super炸场,1200亿参数专为Agent打造,性能直逼Claude Opus 4.6。推理狂飙3倍,吞吐量猛涨5倍,「龙虾」这是要上天了。
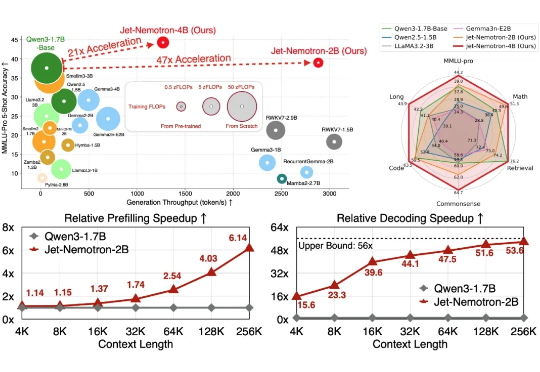
Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。
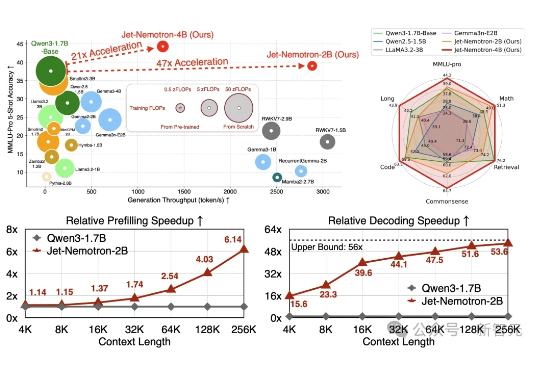
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
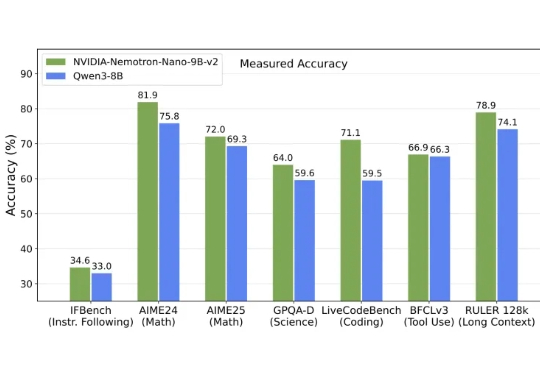
英伟达发布全新架构9B模型,以Mamba-Transformer混合架构实现推理吞吐量最高提升6倍,对标Qwen3-8B并在数学、代码、推理与长上下文任务中表现持平或更优。
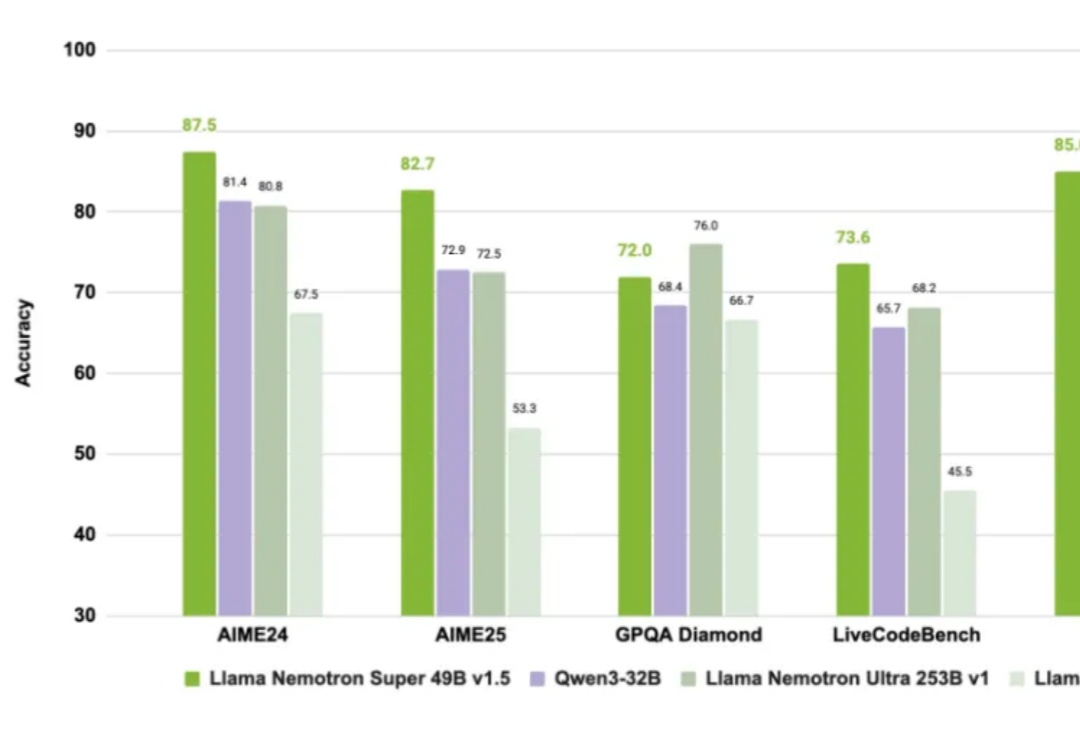
众所周知,老黄不仅卖铲子(GPU),还自己下场开矿(造模型)。

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。
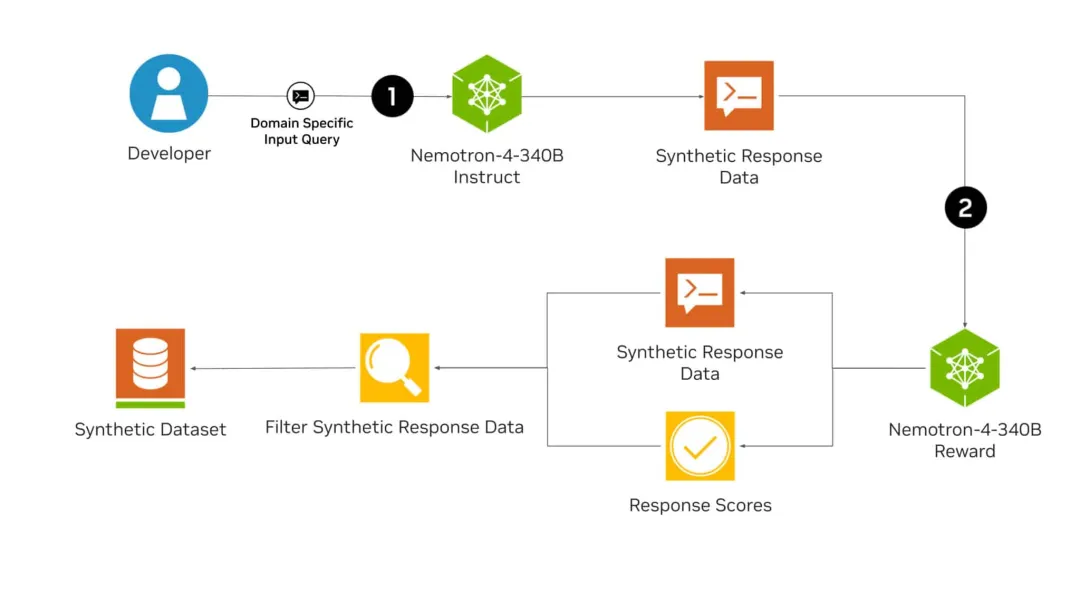
性能超越 Llama-3,主要用于合成数据。