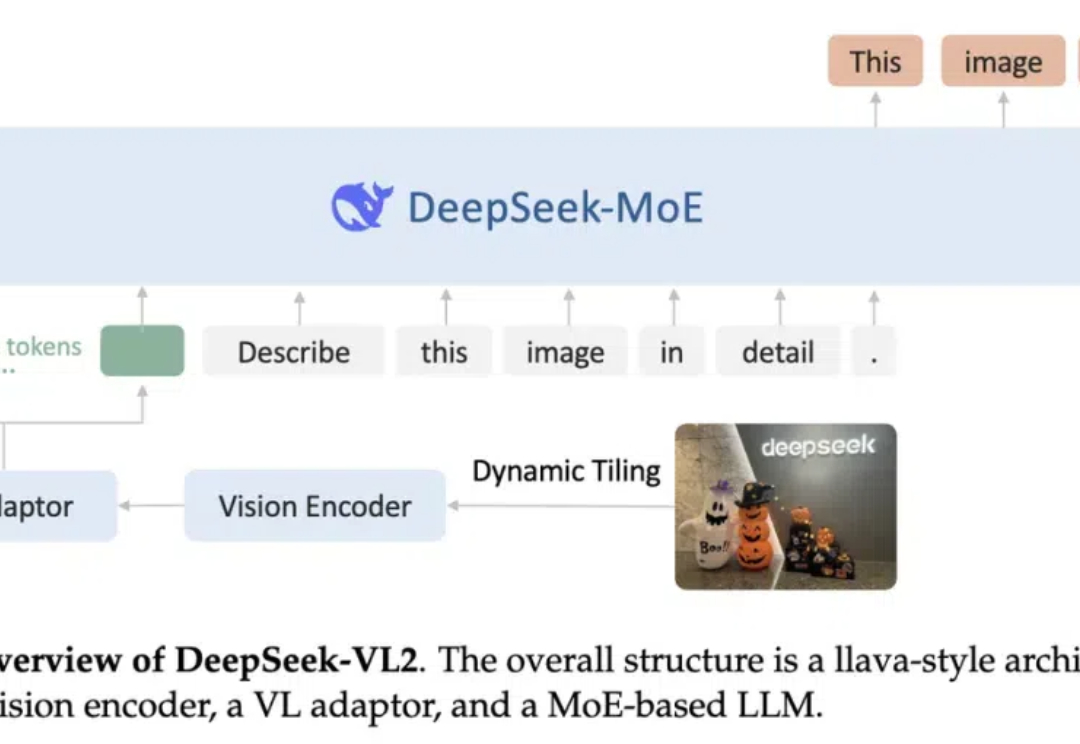
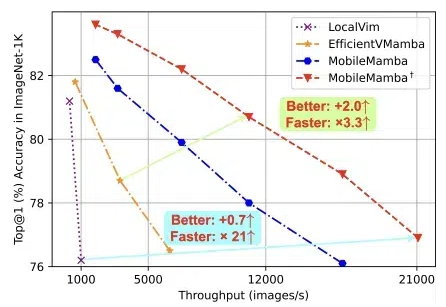
对话肖特特:从伯克利到PromptAI创业,发明创造下一代视觉智能
对话肖特特:从伯克利到PromptAI创业,发明创造下一代视觉智能通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。
来自主题: AI资讯
10713 点击 2024-12-16 10:48