李飞飞「空间智能」系列新进展,吴佳俊团队新「BVS」套件评估计算机视觉模型
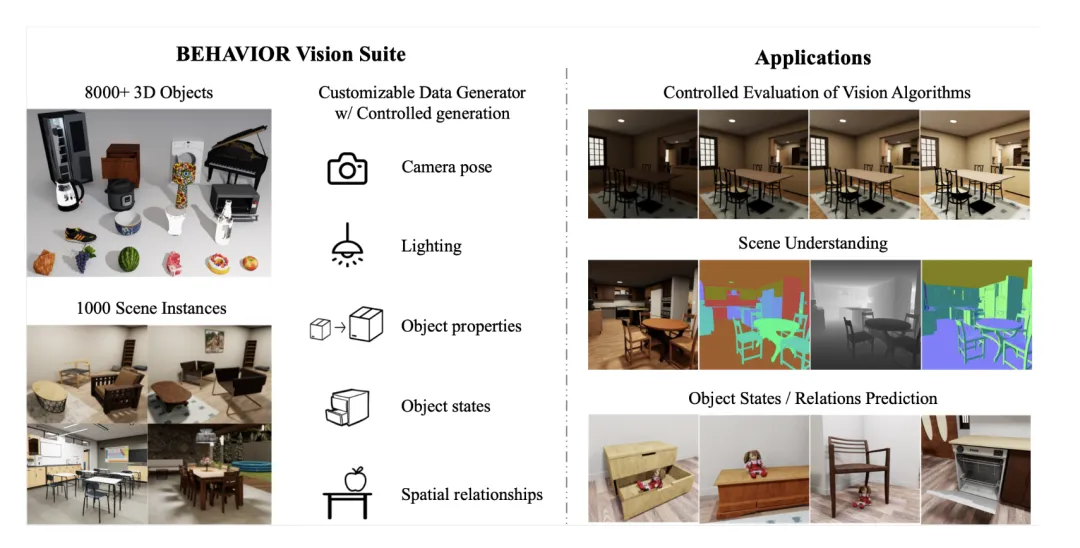
李飞飞「空间智能」系列新进展,吴佳俊团队新「BVS」套件评估计算机视觉模型在不久之前的 2024 TED 演讲中,李飞飞详细解读了 空间智能(Spatial Intelligence)概念。她对计算机视觉领域在数年间的快速发展感到欣喜并抱有极大热忱,并为此正在创建初创公司
来自主题: AI资讯
11077 点击 2024-05-21 15:31
 搜索
搜索
在不久之前的 2024 TED 演讲中,李飞飞详细解读了 空间智能(Spatial Intelligence)概念。她对计算机视觉领域在数年间的快速发展感到欣喜并抱有极大热忱,并为此正在创建初创公司

前有OpenAI的GPT-4o,后有谷歌的系列王炸,先进的多模态大模型接连炸场。

我们知道,球状星团是一种受引力束缚,成员由几万颗到数百万颗恒星组成的古老星团,在外观上大多呈球形,但也有可能受其他天体系统的引力影响使得形状偏离球形。球状星团的动力学演化过程,星族合成路径等是当今天文学界的研究热点。

简单粗暴的理解,就是语言能力足够强大之后,它带来的泛化能力直接可以学习图像视频数据和它体现出的模式,然后还可以直接用学习来的图像生成模型最能理解的方式,给这些利用了引擎等已有的强大而成熟的视频生成技术的视觉模型模块下指令,最终生成我们看到的逼真而强大的对物理世界体现出“理解”的视频。

视觉模型,同样遵循「参数越多性能越强」的规律?刚刚,一项来自苹果公司的研究验证了这个猜想。

来自MABZUAI和Meta的研究人员发表的最新研究,在「非标准」指标上全面比较了常见的视觉模型。

GPT-4V的开源替代方案来了!极低成本,性能却类似,清华、浙大等中国顶尖学府,为我们提供了性能优异的GPT-4V开源平替。

12月5-6日,主题为“未来AI设计”的美图创造力大会在厦门举行。美图公司发布自研AI视觉大模型MiracleVision(奇想智能)4.0版本,主打AI设计与AI视频。

通义千问开源全家桶正式上线!业界最强72B模型直接超越开源标杆Llama 2-70B,还有1.8B模型、音频大模型全部开源,阿里云这次真的把家底都掏出来了。

用视觉来做Prompt!沈向洋展示IDEA研究院新模型,无需训练或微调,开箱即用