告别AI“乱画图表”!港中文团队发布首个结构化图像生成编辑系统
告别AI“乱画图表”!港中文团队发布首个结构化图像生成编辑系统AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
来自主题: AI技术研报
11076 点击 2025-10-12 15:03
 搜索
搜索
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
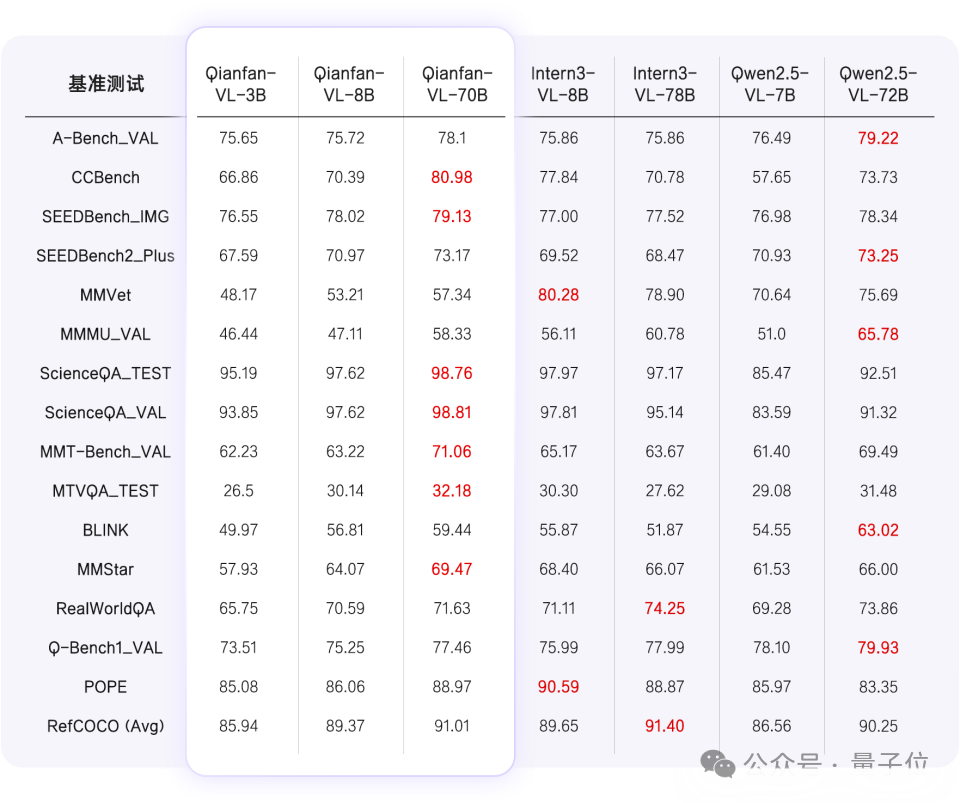
今天,百度智能云千帆正式推出全新视觉理解模型——Qianfan-VL,并全面开源!该系列包含3B、8B和70B三个尺寸版本,是面向企业级多模态应用场景,进行了深度优化的视觉理解大模型。
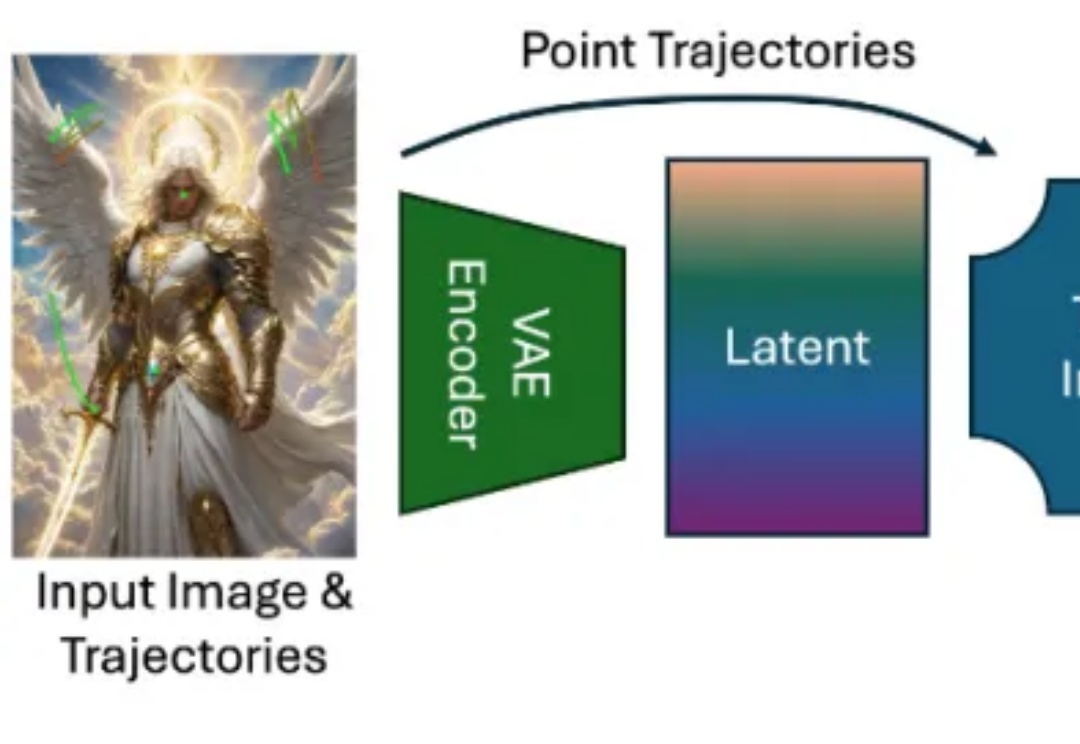
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。

2024年12月31日,阿里云宣布2024年度第三轮大模型降价,通义千问视觉理解模型全线降价超80%。
在人工智能快速发展的当下,这个问题有了新的答案——处理284张720P的图片。2023年12月,随着字节跳动发布最新的豆包视觉理解模型,AI领域又迎来一次"降维打击":每千tokens的输入价格降至3厘,较行业常见价格低了整整85%。

前脚大模型六小虎之一的智谱刚完成新一轮30亿的融资;后脚字节跳动发布豆包视觉理解模型、快手可灵1.6正式上线。