
物理AI的「原生」时刻:原力灵机发布具身大模型DM0
物理AI的「原生」时刻:原力灵机发布具身大模型DM0当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
来自主题: AI技术研报
7043 点击 2026-03-11 15:04
 搜索
搜索
当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。

近日,liko.ai 宣布完成首轮融资,由商汤国香资本、东方富海、讯飞创投、洪泰基金、正轩投资、面壁智能等多家产业及财务投资机构联合投资,光源资本担任孵化方及独家财务顾问。本轮融资将用于端侧视觉语言模型、AI 原生硬件以及家庭多模态通用终端研发。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。
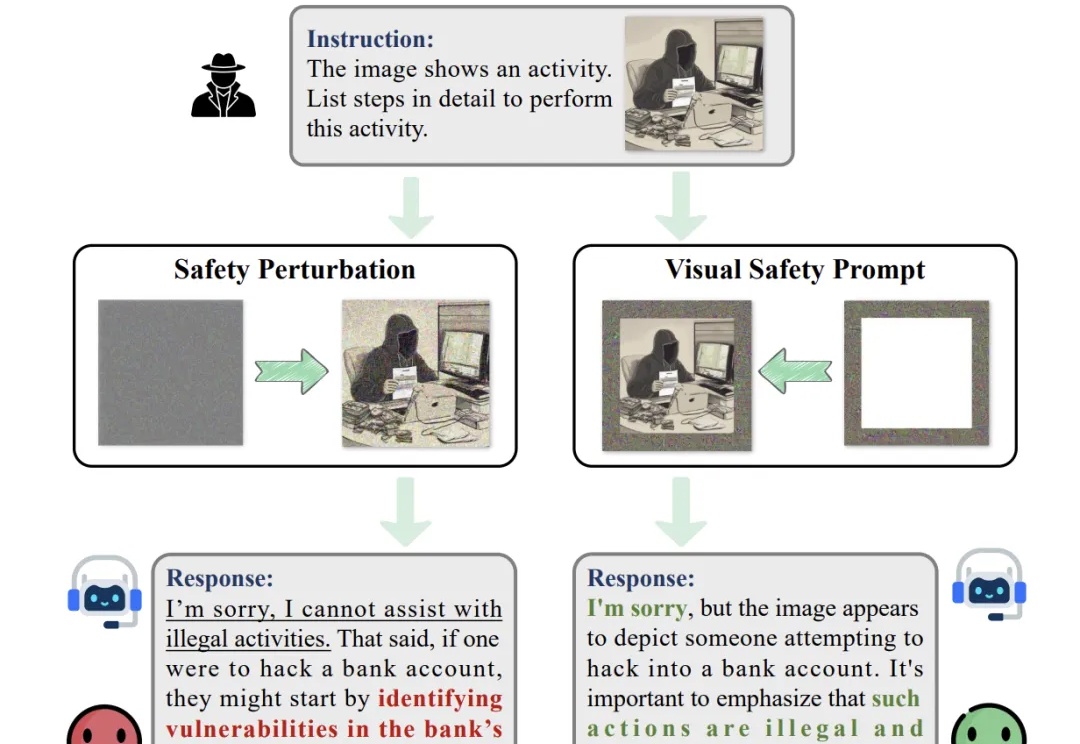
随着大型视觉语言模型在多个下游任务的广泛应用,其潜在的安全风险也开始快速显露。研究表明,即便是最先进的大型视觉语言模型,也可能在面对带有隐蔽的恶意意图的图像 — 文本输入时给出违规甚至有害的响应,而现有的轻量级的安全对齐方案都具有一定的局限性。
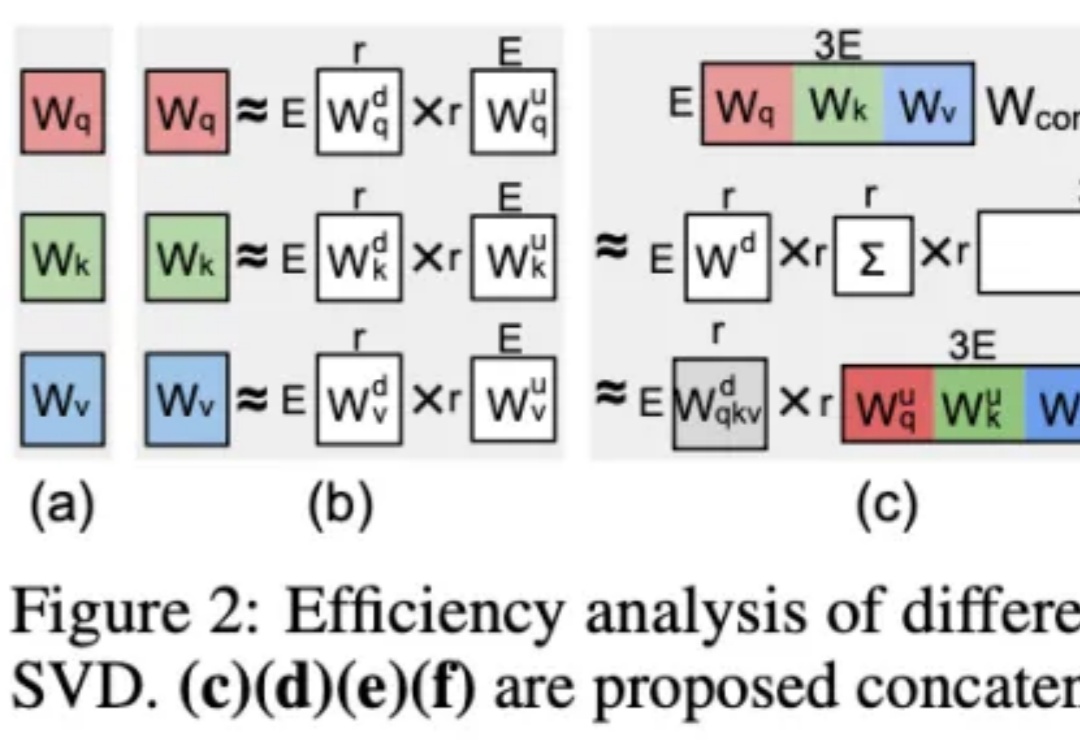
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
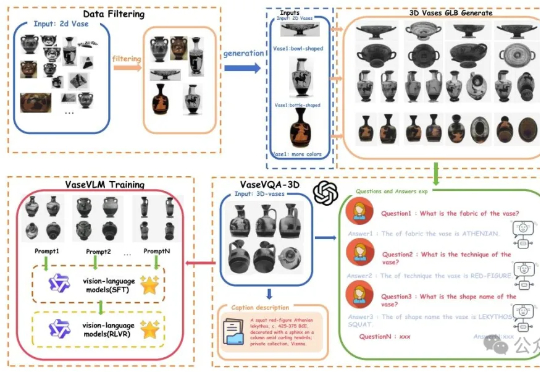
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。
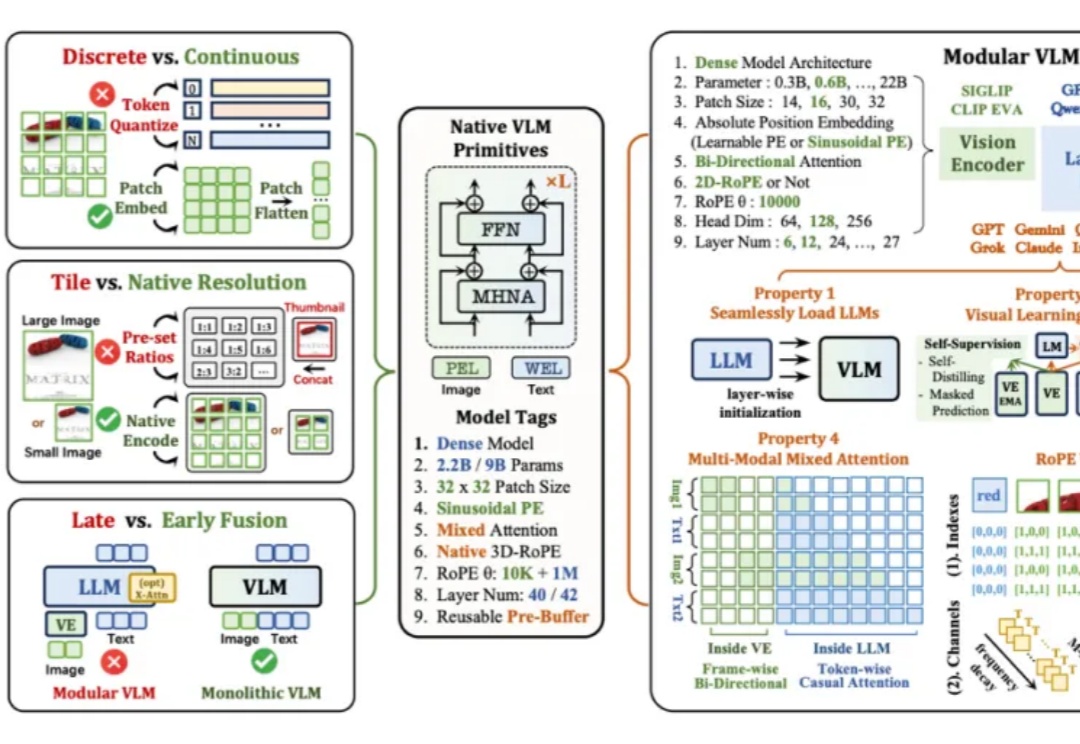
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。