米哈游蔡浩宇AI公司首个视频模型曝光了
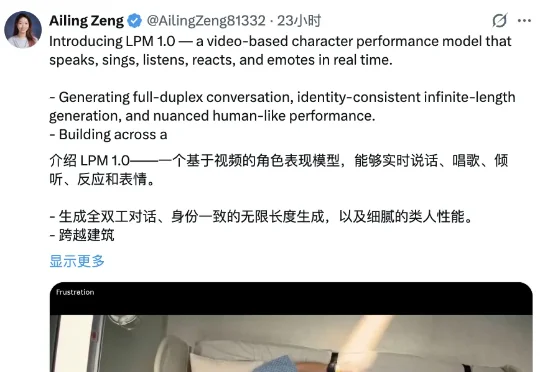
米哈游蔡浩宇AI公司首个视频模型曝光了米哈游蔡浩宇的AI公司Anuttacon,首个视频模型正式曝光!Anuttacon技术团队成员@Ailing Zeng,在X上展示了全新视频角色表演生成模型——LPM 1.0。
来自主题: AI资讯
8764 点击 2026-04-11 14:30
 搜索
搜索
米哈游蔡浩宇的AI公司Anuttacon,首个视频模型正式曝光!Anuttacon技术团队成员@Ailing Zeng,在X上展示了全新视频角色表演生成模型——LPM 1.0。

近日,京东开源图像模型JoyAI-Image-Edit,将空间智能纳入图像理解与编辑,让AI开始处理真实世界中的空间关系,让模型真正“理解空间,编辑空间”。简单解释,这是一个以空间智能为核心的图像生成与编辑模型,让 AI 真正“看懂”三维空间,从而让生成更合理、编辑更精准。

恰好最近,我留意到常用的一个视频生成工具 Vidu,上线了 ViduClaw 「V 龙」——全球首个多模态创意营销 Claw。虽然此前已有不少 AI 厂商推出了自家的「Claw」,但作为视频模型厂商,而且做得这么完整的,Vidu 是我见到的业内头一个。
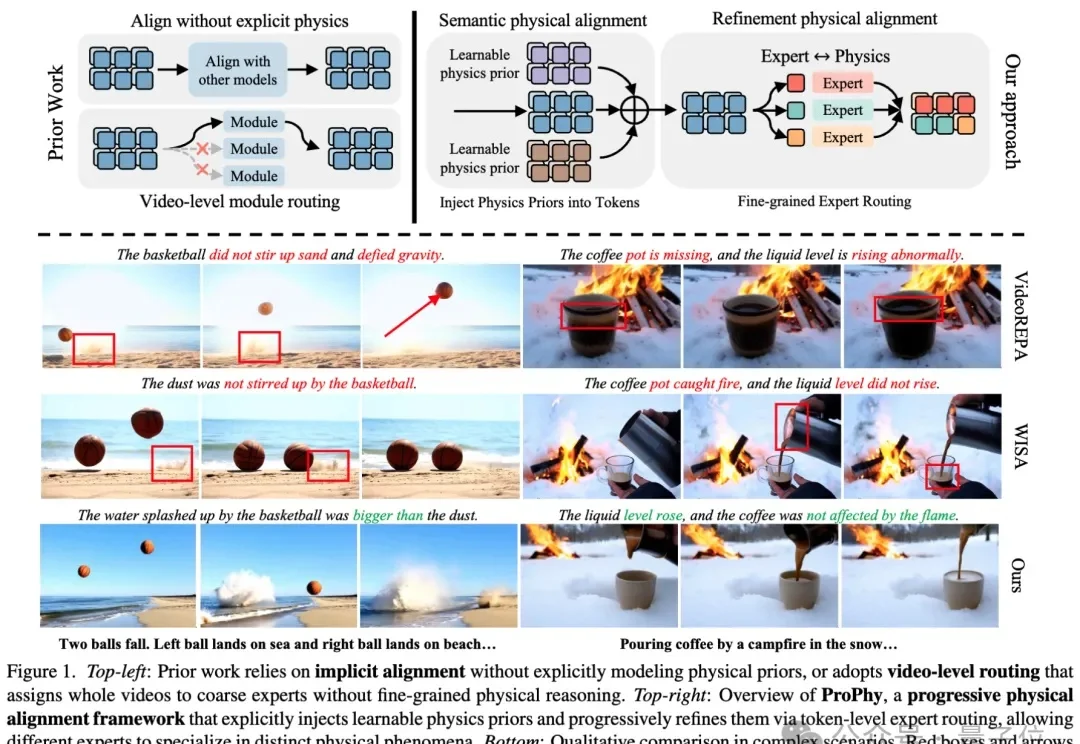
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。
来自天工AI的SkyReels-V4,没打招呼,直接登顶Artificial Analysis文转视频(含音频)全球榜,超越Veo 3.1、Sora 2。一个月前,其Preview版本才刚拿下该榜全球第2。

据 The Informaton 报道,字节跳动已经暂缓了视频生成模型 Seedance 2.0 的全球发布计划。背后的导火索,是一连串来自好莱坞头部片厂和流媒体平台的版权争议。
春节期间, Seedance 2.0 爆火,堪称现象级,这也再次把视频生成推上风口。前两天,字节跳动又携手北大、安努智能和 Canva 共同开源了具备实时生成能力的视频模型 Helios 家族。该系列包含了 Helios-Base、Helios-Mid 与 Helios-Distilled 三个版本,全面覆盖了 T2V、I2V、V2V 以及交互式生成任务。
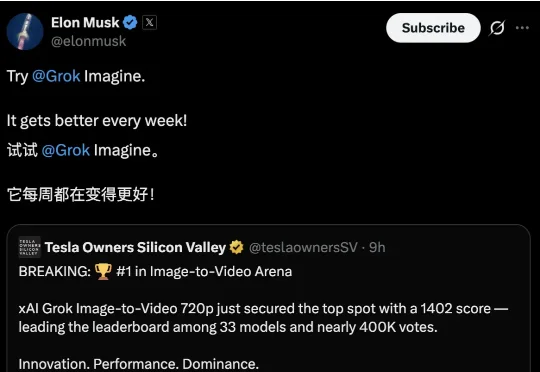
xAI的Grok图像转视频模型(grok-image-video-720p)登顶「Image-to-Video Arena」排行榜,以1404分的超高ELO评分力压群雄,位居第一。马斯克亲自发帖为自家Grok Image模型站台,称它每周都在迭代优化。
这两周,字节新发布的 AI 视频模型 Seedance2.0 特别火,真正的全民热议。 我给我爹看了几个模型生成的视频,他的反应特别有代表性。看完以后他跟我说了一句话:「你别胡说八道,这就是真人啊。」

爆红社交平台、登顶全球评测,中国AI视频模型集体破圈。