
深度|打破次元边界,Xmax AI发布世界首个虚实融合的实时交互视频模型X1,开启视频交互新范式
深度|打破次元边界,Xmax AI发布世界首个虚实融合的实时交互视频模型X1,开启视频交互新范式如果 2024 年我们还在感叹 Sora 模拟物理世界的真实感,那么在 2026 年的今天,单纯的高清视频生成已不再是终点。
来自主题: AI资讯
7887 点击 2026-02-09 17:08
 搜索
搜索
如果 2024 年我们还在感叹 Sora 模拟物理世界的真实感,那么在 2026 年的今天,单纯的高清视频生成已不再是终点。

初创公司 Xmax AI 推出的首个虚实融合的实时交互视频模型 X1,没有复杂的 Prompt,不需要漫长的渲染等待,只需要手势进行交互,就可以让虚拟世界与现实相连,在镜头中令「幻想」成真,让用户体验到实时交互的心流体验。
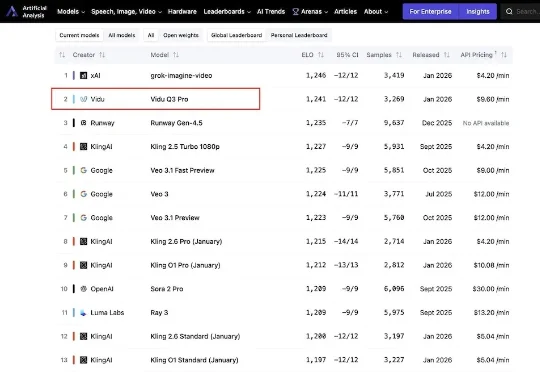
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。
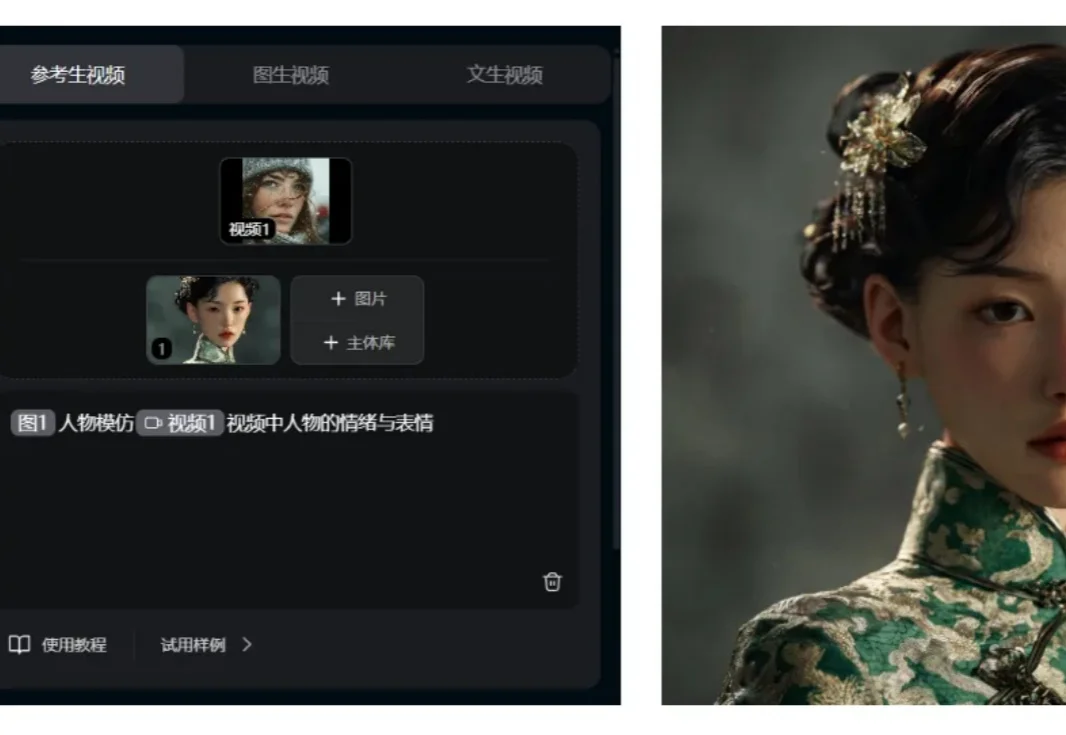
现在的视频创作环境太卷了。去年我们还在感叹AI视频能动了,现在大家的要求直接拔高到了不仅要能动,还要动得高级、动得精准。

不er,这个世界还有什么是真的?反正我是已经分不清了...

他们开发了一个叫做 Lemon Slice-2 的 AI 模型,可以把任何一张静态图片——无论是公司员工照、卡通角色、还是文艺复兴时期的油画——瞬间变成一个能实时对话的视频头像。

DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。 为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试
2025 年 1 月创立了一家专注“实时交互多模态内容”的 AI 初创企业;同年 2 月完成种子轮,由红杉中国和 IDG 资本联合领投;8 月 Pre-A 估值突破 4 亿美元;11 月 A 轮估值 突破13.2亿美元。换算一下,这家才刚满一岁的“tiny AI venture”,如今的身价已经站进全球视频模型创业公司第一梯队

终于,几天前登上 Artificial Analysis 榜首的神秘模型 Whisper Thunder (aka) David 现出了真身。

字节新视频模型Vidi2,理解能力超过了Gemini 3 Pro。