# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
电影级视频生成模型来了。
来自阿里,来自通义——通义万相Wan2.2。并且率先将MoE架构实现到了视频生成扩散模型中,能够实现电影级效果。
嗯,依然发布即开源。
就在刚刚,阿里开源了新一代视频生成模型王者通义万相Wan2.2,包括文生视频、图生视频和混合视频生成。

其中Wan2.2-T2V-A14B和Wan2.2-I2V-A14B是业界首个使用MoE架构的视频生成模型,可一键生成电影级质感视频;5B版本则同时支持文生视频和图生视频,可在消费级显卡部署,也是目前最快的24fps、720P的基础模型。
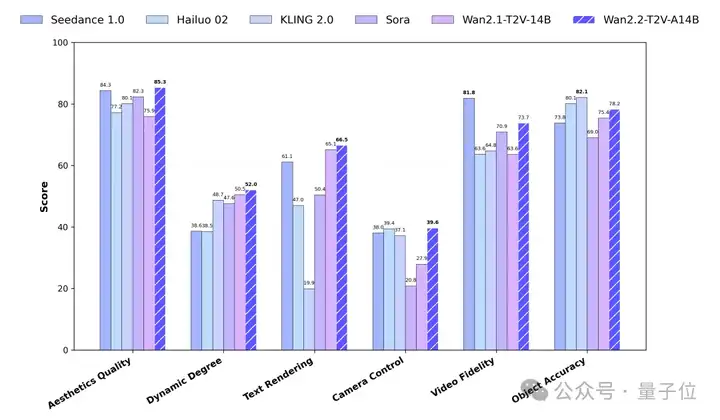
无论是对比自家上一代模型Wan2.1,还是视频生成模型标杆Sora,Wan2.2都明显有更强劲的表现。
那么话不多说,先看几个官方demo尝尝鲜。
Wan2.2首先致敬了多部经典电影,从科幻片到爱情片,Wan2.2都能1:1还原。

当然也可以创作自己的原创电影,想象自己是帅气的西部牛仔、沙漠中嗜血的孤狼。

仔细看,人物坐下时还能有极为真实的沙发回弹。

幻想题材也不在话下:

另外官方还做了部概念电影,点击下方立马大饱眼福~

难怪网友都直呼难以置信:
这么强还开源,一定需要用户很强的电影技术功底吧?
No No No!Wan2.2只需要用户自由选择美学关键词,就能轻松拍出王家卫、诺兰等名导的相同质感画面。
更流畅的复杂运动过程、更强的物理世界还原,电影工业要被重塑了…
现在,用户可直接通过通义万相平台(官网和APP),就能立即上手体验,也可在GitHub、HuggingFace以及魔搭社区下载模型和代码,具体链接指路本文末,都为大家准备好了。
具体上手体验下来,就是操作简单,但效果非常不简单。
在Prompt前加入自己的喜欢的美学关键词,就可以非常轻松地还原真实世界,多人互动也不会出现明显的动作扭曲,镜头变化也相当流畅。
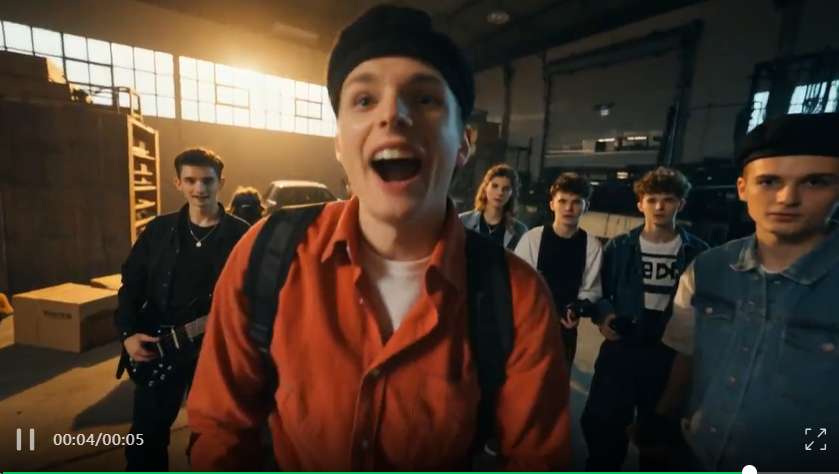
从现实到虚拟的过渡也很自然,不会出现明显的突兀感。

在视频内还可以编辑文字,提升画面层次。

尤其是Wan2.2在光影上下足了功夫,影子的变换都足够平滑。

另外,Wan2.2本次还支持ComfyUI,借助其自动卸载功能,50亿参数版本的显存要求直接降低至8GB。

那么,具体是如何实现的呢?
本次Wan2.2在模型架构上,首次创新地将MoE架构引入视频生成。
要知道视频生成模型目前面临的最大瓶颈,就是在扩展参数规模时,所涉及的token长度远超文本和图像。
而MoE架构通过将复杂输入拆分给多个专家模型分别处理,可实现在模型参数扩充的前提下,不额外增加多余的计算负载。
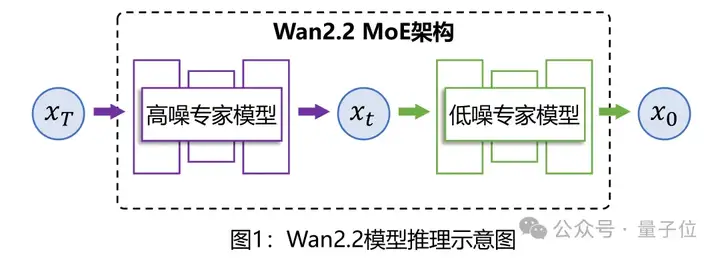
传统语言模型中MoE架构是在Transformer的FFN层进行多专家的切分,Wan2.2则根据扩散模型的阶段性降噪过程,利用信噪比将其分为高噪声阶段和低噪声阶段。
然后通过选择900的去噪时间步,将模型分为高噪模型和低噪模型,输入首先交由高噪专家模型负责前期去噪并构建主体结构,再经过低噪专家模型进行后期去噪生成细节。
引入MoE架构后,Wan2.2拥有了最低的验证损失(Validation loss),即生成视频与真实视频之间的差异最小,质量也最高。
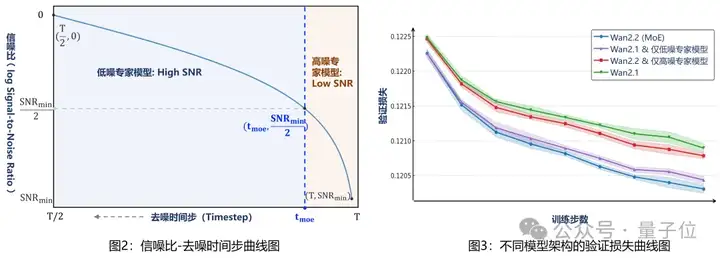
相比于Wan2.1,本次模型在训练数据上也实现了显著提升,其中图像数据增加了65.6%,视频数据增加83.2%。
其中更多的是集中在后期的美学数据上,引入专门的美学精调阶段,通过颗粒度训练,让模型能够生成与用户给定Prompt相对应的美学属性。
另外,模型在训练过程中还融合了电影工业标准的光影塑造、镜头构图法则和色彩心理学体系,将专业导演的美学属性进行分类并整理成美学提示词。
因此用户可自由选择合适的提示词组合,生成目标视频。
在训练后期,模型还通过RL微调,进一步对齐人类审美偏好。
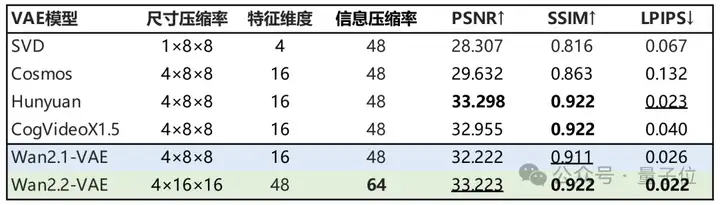
为了更方便地在消费级显卡上部署模型,5B版本采用自研的高压缩比3D VAE结构,在视频生成隐空间中,分别在高度(H)、宽度(W)和时间(T)三个维度上进行16x16x4的压缩比,以减少显存占用。
通过引入残差采样结构和非对称编解码框架,可以在更高的信息压缩率下依旧保持重建质量领先。
Wan2.2还首次推出了电影级美学控制系统,将光影、色彩、镜头语言三大电影美学元素全部打包装进模型,用户可直接通过选择美学关键词,就能获取电影质感的视频画面。
具体来说,首先是将复杂的电影摄影技术转化为12个美学维度,共计60多个专业级参数,包括:
可自由选择不同时段的光线(如黄昏、黎明、夜晚),或者特定光源(如日光、人造光),也可以精准控制光线的强度(柔光或硬光)和光线方向(顶光、侧光等)。

也可以修改环境对比度高低,营造出明暗对比氛围。
可以调用多种构图法(如中心构图、对称构图等),灵活选择近远景或不同拍摄角度,精准控制画面焦点。

轻松切换色调温度(暖色调或冷色调),传递不同情绪范围,或者选择不同程度的饱和度。

另外,模型还提供不同的镜头焦距(如广角或长焦等),以及不同类型的镜头(如单人镜头、双人镜头等)。

因此用户只需要在指令前添加以上美学关键词前缀,模型就会自动理解不同美学元素间的内在联系,并精确响应用户需求。
除美学控制外,本次Wan2.2也在复杂运动能力上有了大幅度提升,重点针对四类动态表现能力进行了优化:
Wan2.2构建了人类面部原子动作和情绪表情系统,不仅能生成常见的喜怒哀乐,还可以还原复杂微表情,如“强忍泪水时的嘴唇颤抖”、“羞涩微笑中的脸颊微红”等。
构建了丰富的手部动作系统,从基础物理操作到专业领域的精密动作范式都能够轻松生成。
无论是单人表演还是多人复杂互动,模型可理解角色间的位置关系、力量传递等,生成符合物理规律的动作序列,避免人物穿模。
对高速运动(如体操、竞技滑雪、花样游泳等)中存在失真的情况,Wan2.2可以减少动作扭曲,让画面保持动感的同时兼具美感。
Wan2.2还拥有更为强大的复杂指令遵循能力,可以生成物理规律严谨且细节丰富的现实世界动态表现,显著提升视频的真实感和可控性。
加上Wan2.2,本周阿里通义实验室已经连续发布四项开源模型,包括之前的Qwen3-Coder、Qwen3-235B-A22B-Instruct-2507(非思考版)模型、Qwen3-235B-A22B-Thinking-2507推理模型。

截止到目前,Qwen系列模型的累计下载量已超4亿次,衍生模型超14万,位居全球排名第一,构建了强大的模型生态。
其中通义万相作为通义大模型旗下的AI绘画创作模型,目前开源产品主要涵盖生图和生视频两大类,生视频又可细分为文生视频和图生视频,以及混合视频生成。
从2月底发布的Wan2.1开始,通义万相陆续开源多款模型,例如首尾帧生视频、Wan2.1-VACE,而Wan2.2则主要是在Wan2.1的技术模型上进行迭代升级,预计后续通义万相还将继续冲击国产开源视频生成宝座。

本次除了正式宣布Wan2.2的开源,官方还公布了万相妙思+的全球创作活动,鼓励创作者积极探索Wan2.2的生动表现力,包括电影级镜头语言和极致运动表现等。
比赛要求使用通义万相作为主要创作工具,视频时长分兴趣组和专业组,兴趣组要求5-15秒,专业组要求30秒以上,视频大小不超过500MB,格式为MOV或MP4。
怎么说呢,中国的AI电影时代,可能要从杭州开始了。
现在距离你的电影大作,不需要导演、不需要剪辑、不需要摄影……只需要一个会提示词的编剧。
官网指路:https://wan.video/welcome
GitHub:https://github.com/Wan-Video/Wan2.2
Hugging Face:https://huggingface.co/Wan-AI
ModelScope:https://modelscope.cn/organization/Wan-AI
参考链接:
[1]https://blog.comfy.org/p/wan22-day-0-support-in-comfyui
[2]https://x.com/Alibaba_Wan/status/1949827662416937443
文章来自于“量子位”,作者“鹭羽”。


【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
