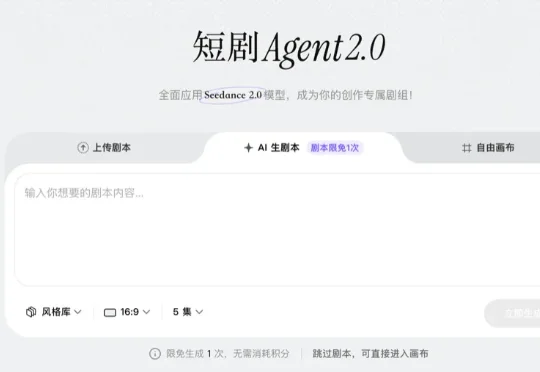
小云雀短剧Agent升级2.0,我花200元就做了一部AI版的《给阿嬷的情书》
小云雀短剧Agent升级2.0,我花200元就做了一部AI版的《给阿嬷的情书》近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。
来自主题: AI资讯
12038 点击 2026-05-29 15:28
 搜索
搜索
近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。

当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出—— 那就是分辨率越高,生成所需要的时间就越长。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。
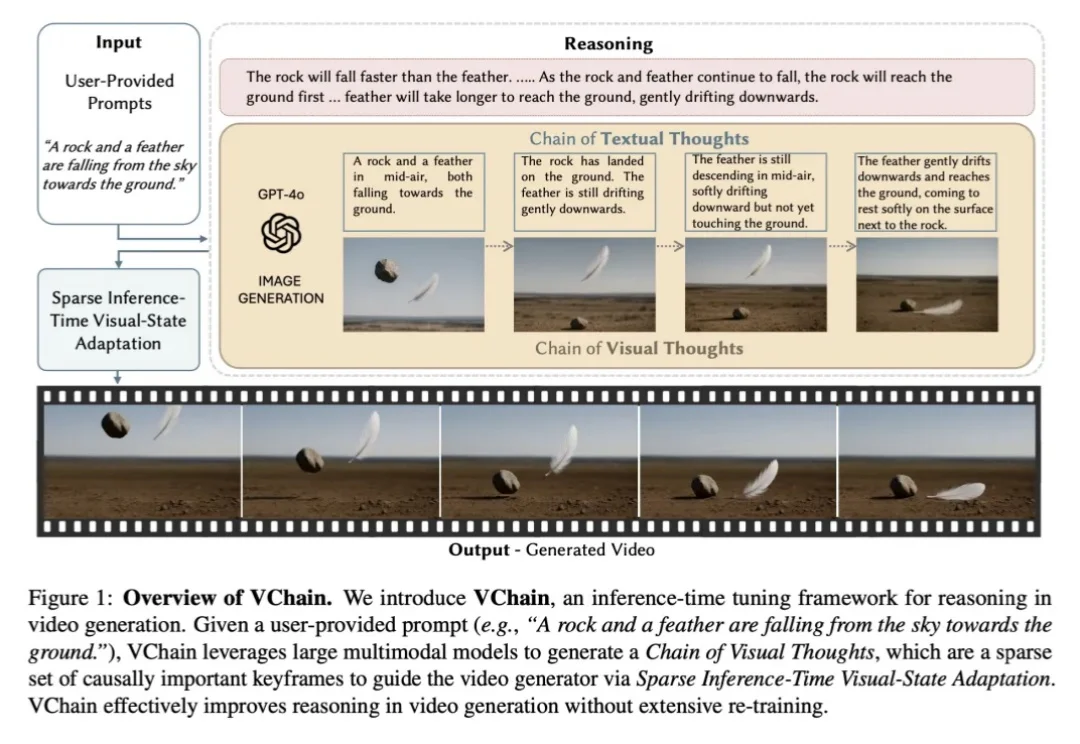
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。
做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。
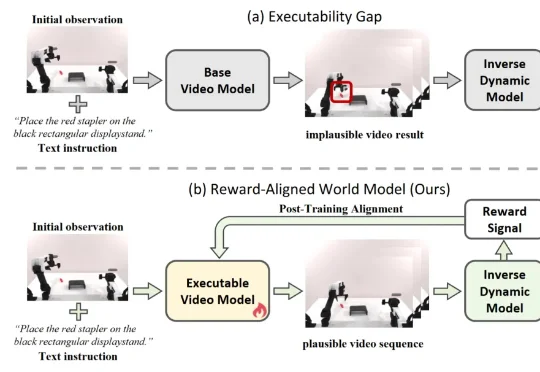
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。

据 The Informaton 报道,字节跳动已经暂缓了视频生成模型 Seedance 2.0 的全球发布计划。背后的导火索,是一连串来自好莱坞头部片厂和流媒体平台的版权争议。
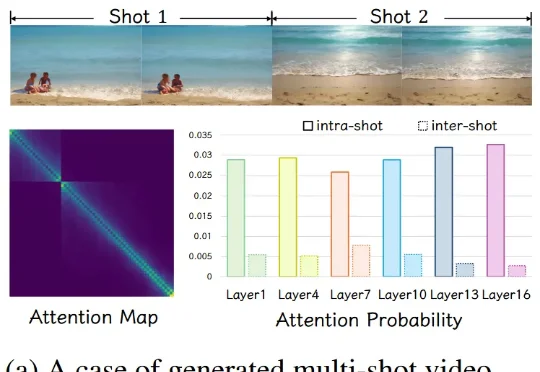
基于对注意力特性的观察,CineTrans 提出块对角掩码的通用机制,使视频生成模型能高效地自动化转场。为了进一步提升转场模型的效果和准确性,作者设计了详细的多镜头视频生产管线,并收集了一个高质量、多镜头数据集 Cine250K,大幅提升多镜头转场视频生成的效果。作为首个时间级可控的自动化转场模型,CineTrans 为这一领域的众多后续方法提供了关键技术。

2026年2月12日,字节跳动正式发布新一代AI视频生成模型Seedance 2.0,同步接入豆包App、即梦App等平台,凭借广播级画质、丝滑运镜、多镜头叙事控制的工业级生成能力,迅速引发全球行业关注。