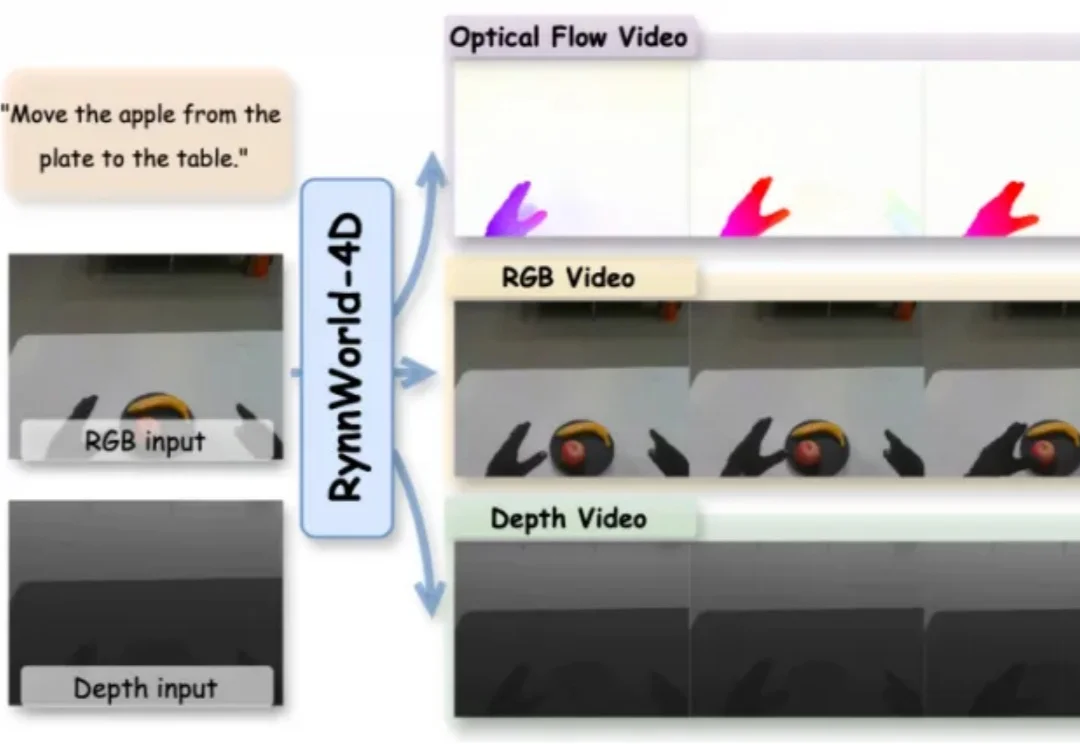
机器人需要「看到三维未来」!RynnWorld-4D重塑4D具身世界模型
机器人需要「看到三维未来」!RynnWorld-4D重塑4D具身世界模型近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
来自主题: AI技术研报
9543 点击 2026-07-17 10:12
 搜索
搜索
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
最近《在超市后门抽烟的二人》这部剧挺火的,尤其是里面的音乐我很喜欢,所以就想着做一个真人版音乐短片,正好发现美图旗下的 MVLAND 上线了创意画布模式,接入 Seedance2.0、可灵、HappyHorse 等顶尖视频生成模型。

今天,阿里巴巴发布了其最新一代视频生成模型HappyHorse 1.1(快乐小马1.1)。阿里称,相比HappyHorse 1.1,这代模型在动态表现力、主体一致性、指令遵循、视觉质感和音频能力等维度有了一定提升。

当用户给出一句简单提示词时,当前的音视频生成模型往往已经能够生成具有不错质量的视听内容。然而,一旦提示词变得复杂,问题便开始暴露出来。
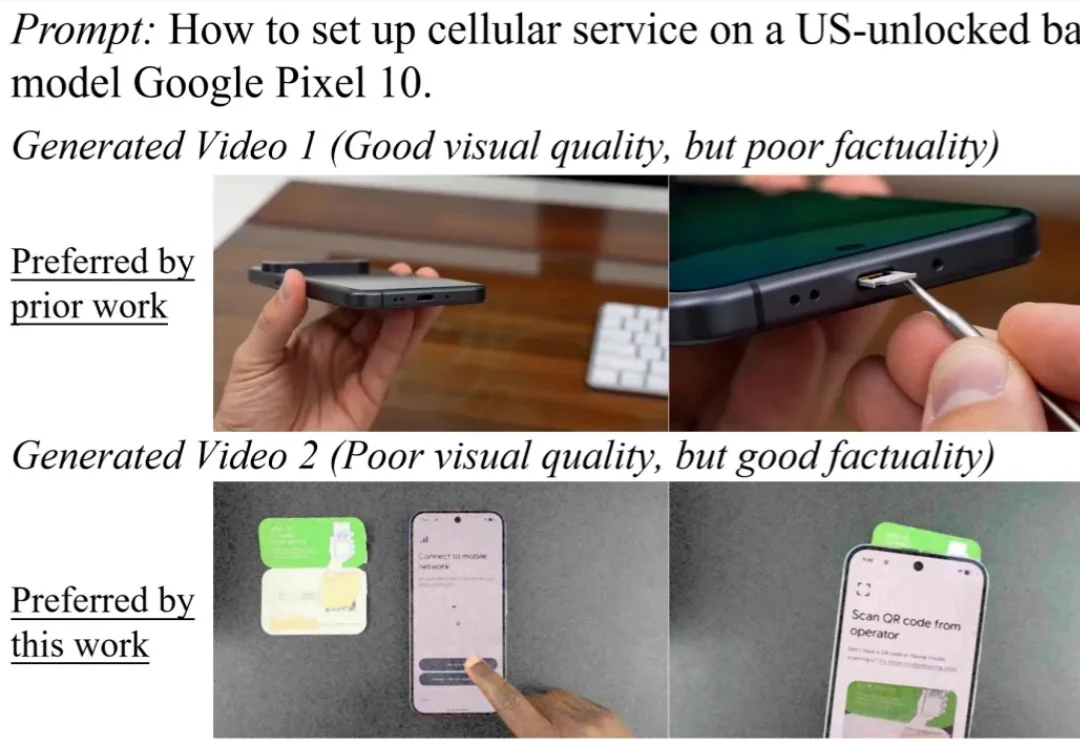
当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?
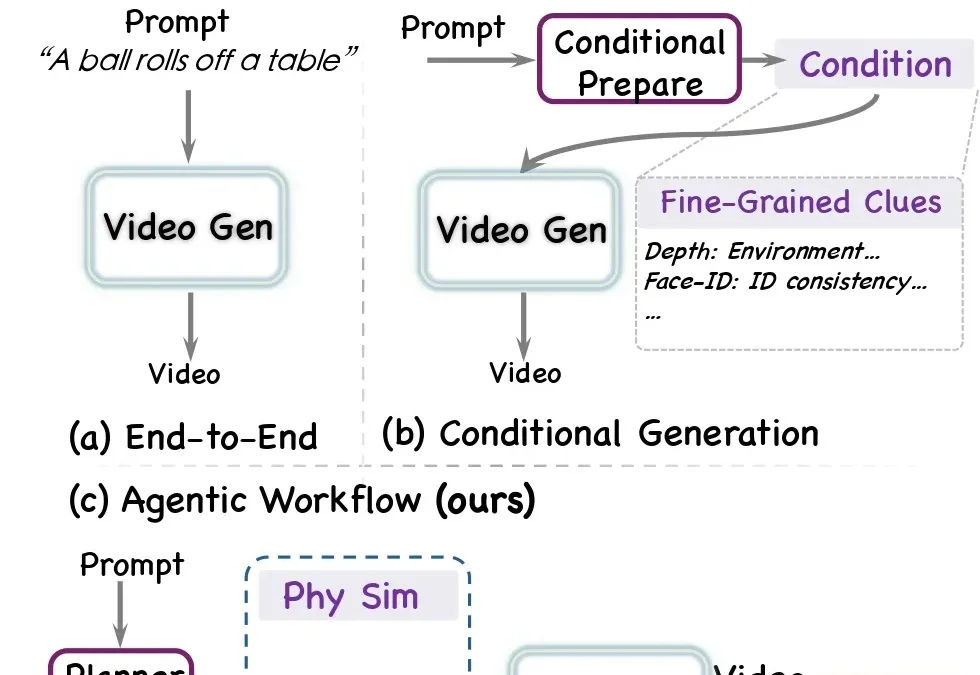
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
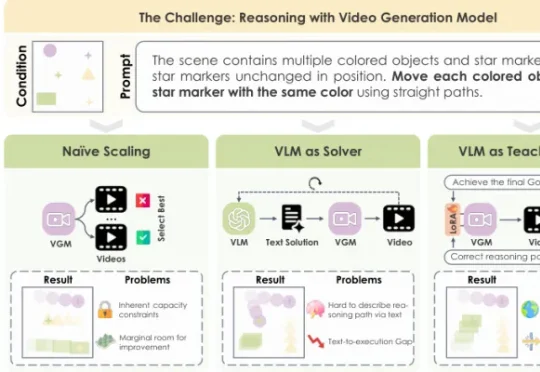
怎么让VGM学会按规则推理?过去主要有两条路。两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。
京东首次开源长音视频生成框架JoyAI-Echo。它直击长视频生成中的角色一致性、声音稳定性和生成速度三大核心难题,一举在多个核心指标上超越行业标杆模型。根据公开评测结果,JoyAI-Echo在跨镜头一致性、语音准确率、用户偏好等关键指标上均取得领先表现,与业内主流长视频生成模型相比优势明显,出道即跻身全球第一梯队。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

对于 Seedance 视频生成模型,大家都不陌生了。