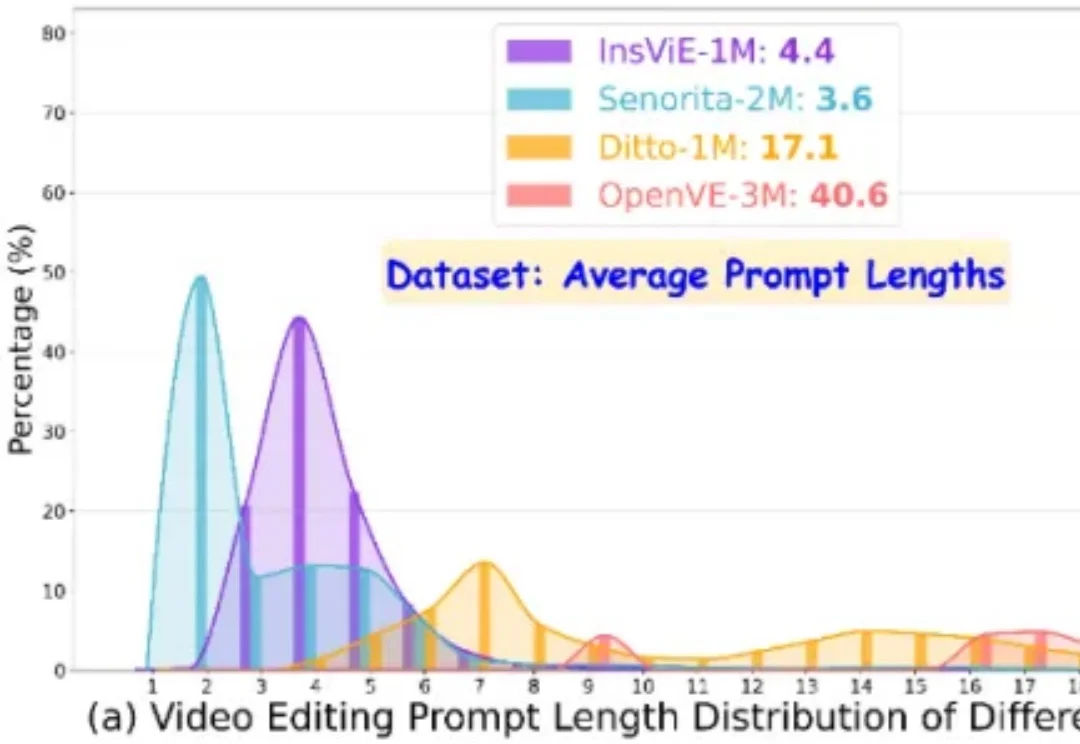
浙大联手字节:开源大规模指令跟随视频编辑数据集OpenVE-3M
浙大联手字节:开源大规模指令跟随视频编辑数据集OpenVE-3M作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。
来自主题: AI技术研报
7863 点击 2025-12-17 09:22
 搜索
搜索
作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。
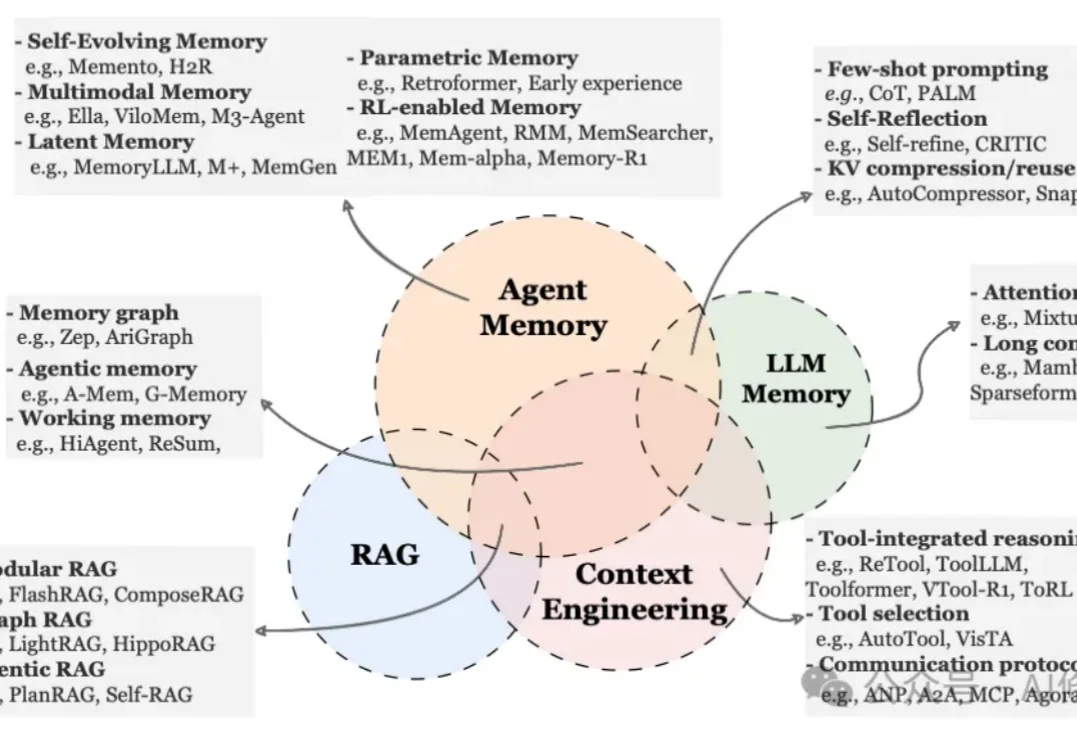
就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。

从 0 到上线,在OpenAI内部,安卓版 Sora经历的时间只有 28 天,而且期间只用了 2-3 名员工。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

在Anthropic,有一位驻场哲学家Amanda Askell专门研究如何与AI模型打交道。她不仅主导设计了Claude的性格、对齐与价值观机制,还总结出一些行之有效的提示词技巧。哲学在AI时代不仅没有落伍,反而那些通过哲学训练掌握提示词技巧的人,年薪中位数可以高达15万美元。

随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。
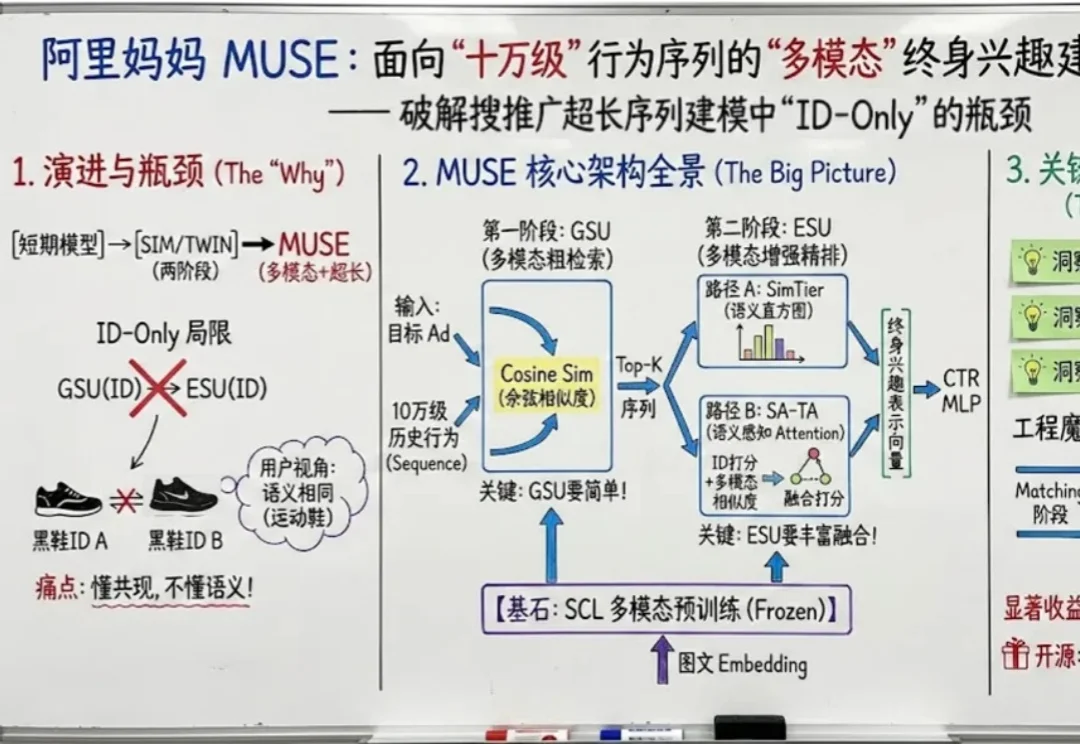
如果把用户在互联网上留下的每一个足迹都看作一段记忆,那么现在的推荐系统大多患有 “短期健忘症”。
要说真学术,还得看推特。