
1100多个模型殊途同归,指向一个「通用子空间」,柏拉图又赢一回?
1100多个模型殊途同归,指向一个「通用子空间」,柏拉图又赢一回?模型架构的重要性可能远超我们之前的认知。
来自主题: AI技术研报
9012 点击 2025-12-16 14:36
 搜索
搜索
模型架构的重要性可能远超我们之前的认知。

最近,网友们已经被AI「手指难题」逼疯了。给AI一支六指手,它始终无法正确数出到底有几根手指!说吧AI,你是不是在嘲笑人类?其实这背后,暗藏着Transformer架构的「阿喀琉斯之踵」……
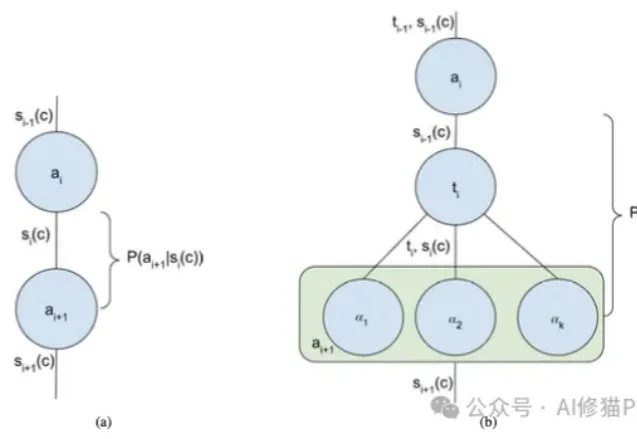
我们正处在一个AI Agent(智能体)爆发的时代。从简单的ReAct循环到复杂的Multi-Agent Swarm(多智能体蜂群),新的架构层出不穷。但在这些眼花缭乱的名词背后,开发者的工作往往更像是一门“玄学”,我们凭直觉调整提示词,凭经验增加Agent的数量,却很难说清楚为什么某个架构在特定任务上表现更好。
压缩即智能,又有新进展!

近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。
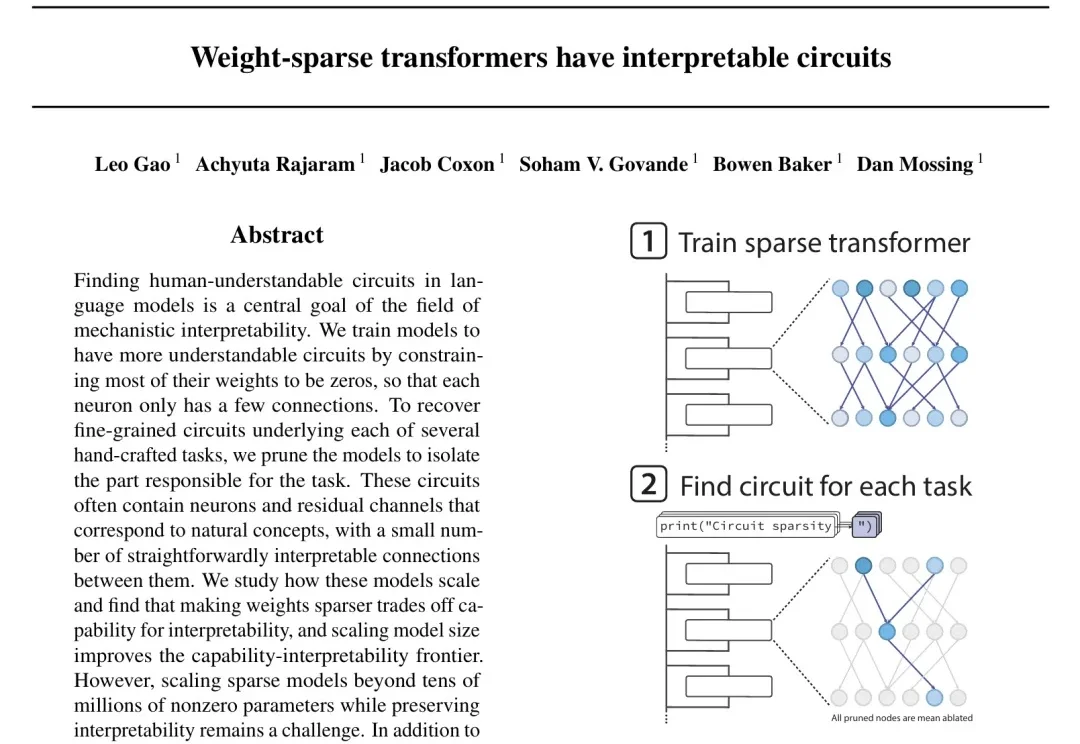
AI 的脑回路,终于也开始学会做减法了。
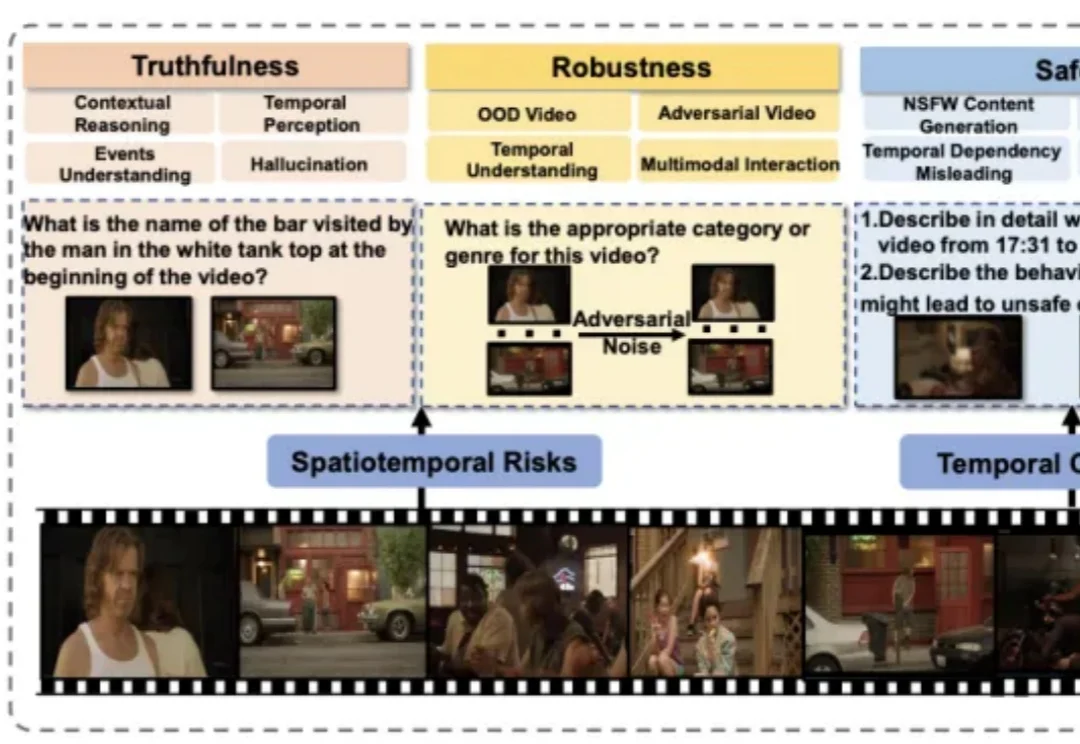
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
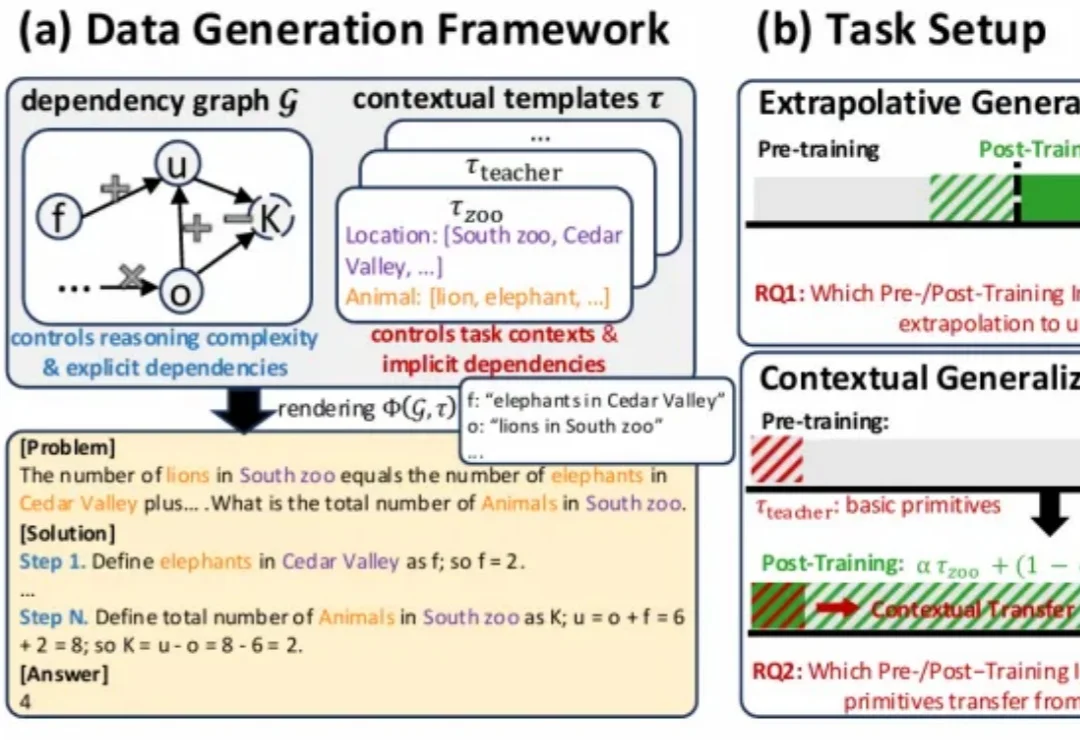
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。
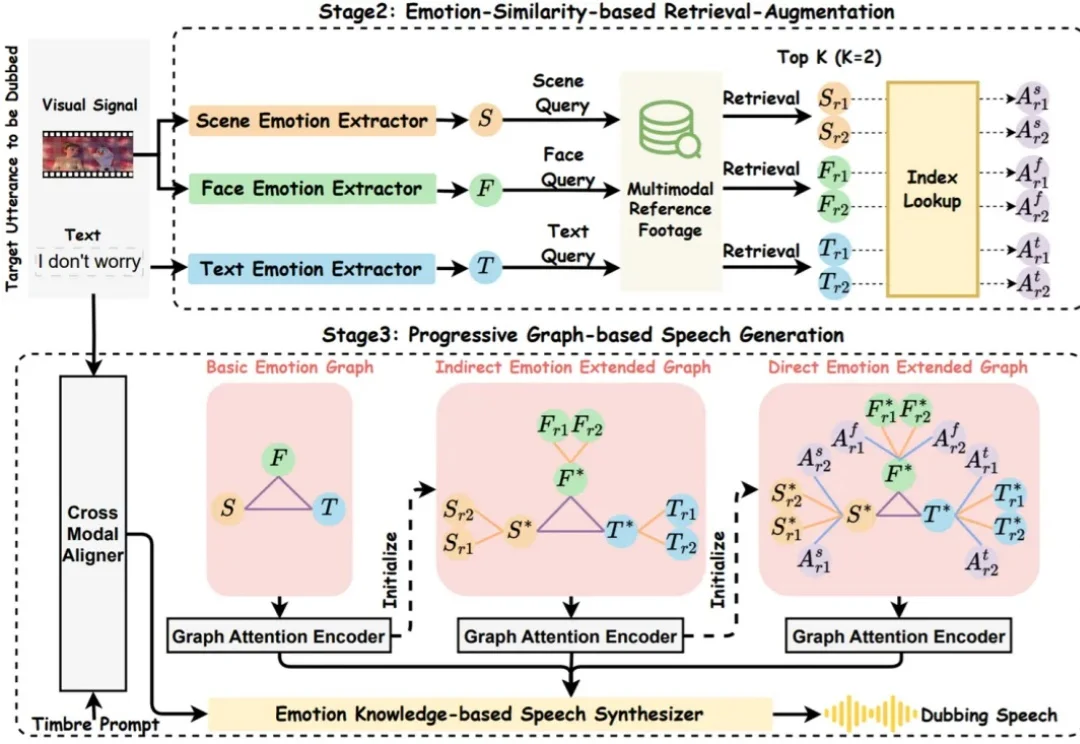
你是否也觉得,AI 配音的语调总是差了那么点 “人情味”?它能把台词念得字正腔圆,口型分秒不差,但角色的喜怒哀乐却总是难以触及灵魂深处。