
GPT-5准确率不足40%!北大发布多模态、高难度化学基准SUPERChem
GPT-5准确率不足40%!北大发布多模态、高难度化学基准SUPERChem北大团队发布化学大模型基准SUPERChem,这是一个多模态、高难度的化学推理基准。它针对现有化学评测的不足,系统构建了评估大语言模型化学推理能力的新体系。
来自主题: AI技术研报
10080 点击 2025-12-15 15:16
 搜索
搜索
北大团队发布化学大模型基准SUPERChem,这是一个多模态、高难度的化学推理基准。它针对现有化学评测的不足,系统构建了评估大语言模型化学推理能力的新体系。
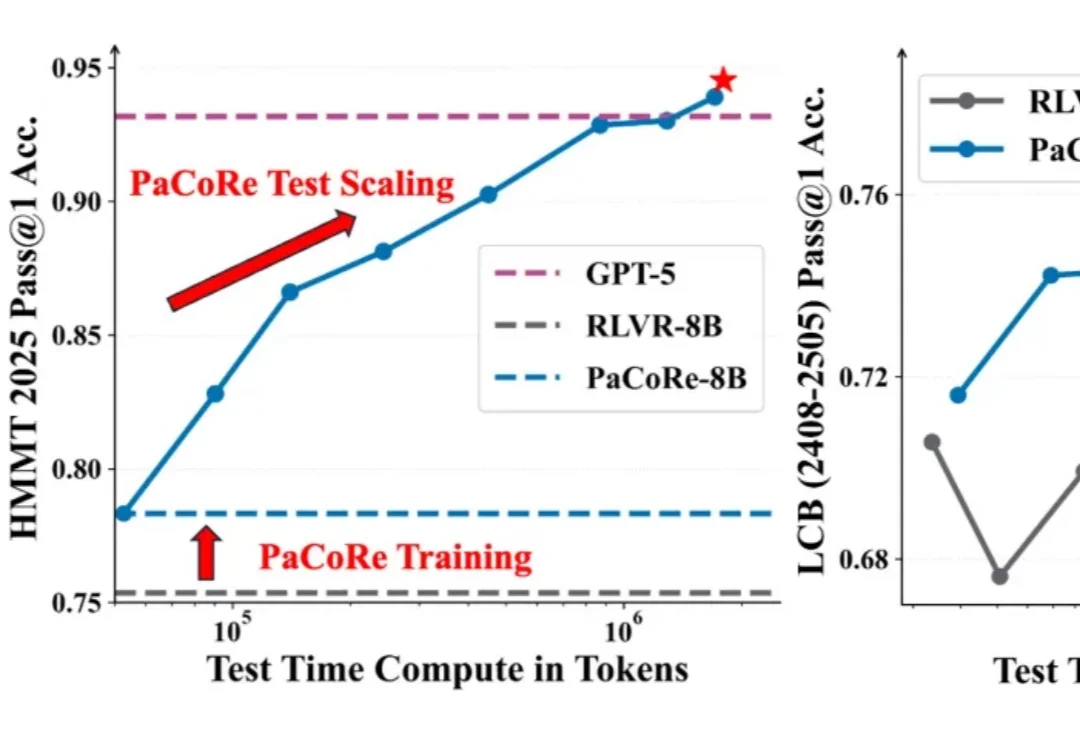
8B 模型在数学竞赛任务上超越 GPT-5!
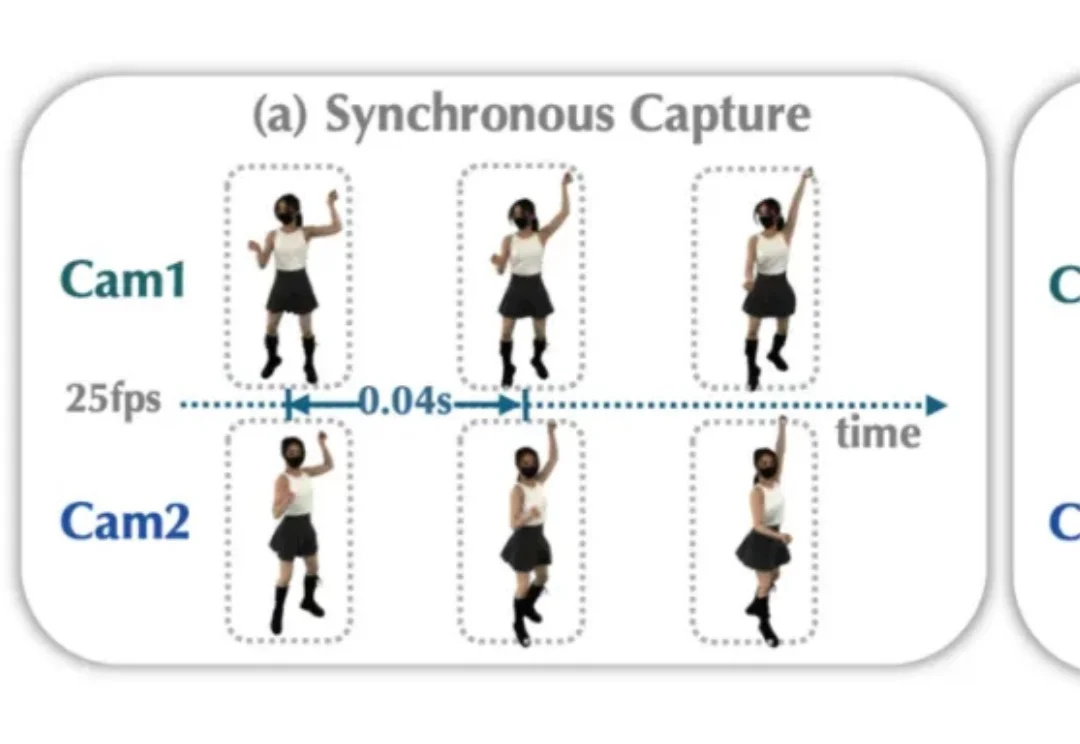
当古装剧中的长袍在武林高手凌空翻腾的瞬间扬起 0.01 秒的惊艳弧度,当 VR 玩家想伸手抓住对手 “空中定格” 的剑锋,当 TikTok 爆款视频里一滴牛奶皇冠般的溅落要被 360° 无死角重放 —— 如何用普通的摄像机,把瞬间即逝的高速世界 “冻结” 成可供反复拆解、传送与交互的数字化 4D 时空,成为 3D 视觉领域的一个难题。

破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?

6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。
邹忌曾经有一个问题:吾与徐公孰美?

在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:

多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?

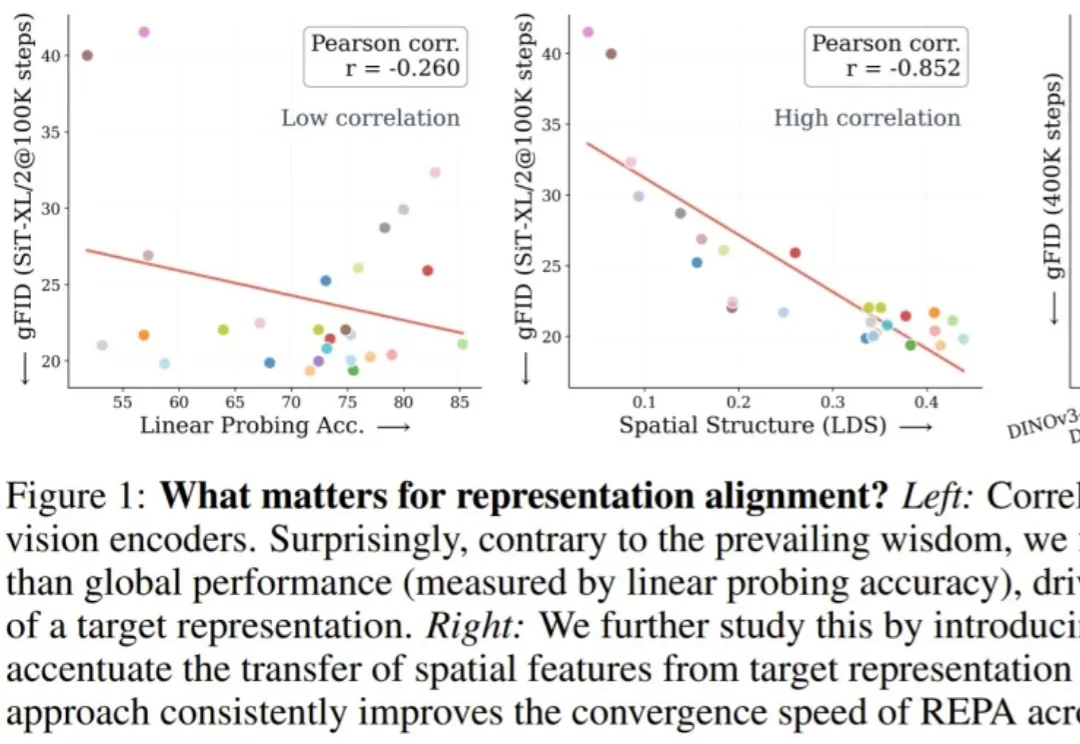
在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。

北航刘偲教授团队提出首个大规模真实星座调度基准AEOS-Bench,更创新性地将Transformer模型的泛化能力与航天工程的专业需求深度融合,训练内嵌时间约束的调度模型AEOS-Former。这一组合为未来的“AI星座规划”奠定了新的技术基准。