
让AI像巴甫洛夫的狗一样学习?北航团队提出智能基础模型,跨越生物与AI鸿沟
让AI像巴甫洛夫的狗一样学习?北航团队提出智能基础模型,跨越生物与AI鸿沟假如你正在教一只小狗学习新技能。当你摇响铃铛然后给它食物,重复几次之后,只要一摇铃铛,即使没有食物,小狗也会留着口水跑过来。这就是著名的巴甫洛夫实验,它展现了生物是如何学习的。
来自主题: AI技术研报
6280 点击 2025-12-10 09:59
 搜索
搜索
假如你正在教一只小狗学习新技能。当你摇响铃铛然后给它食物,重复几次之后,只要一摇铃铛,即使没有食物,小狗也会留着口水跑过来。这就是著名的巴甫洛夫实验,它展现了生物是如何学习的。

Canvas-to-Image 是一个面向组合式图像创作的全新框架。它取消了传统「分散控制」的流程,将身份参考图、空间布局、姿态线稿等不同类型的控制信息全部整合在同一个画布中。用户在画布上放置或绘制的内容,会被模型直接解释为生成指令,简化了图像生成过程中的控制流程。
引言:全网热议背后的本体论修正
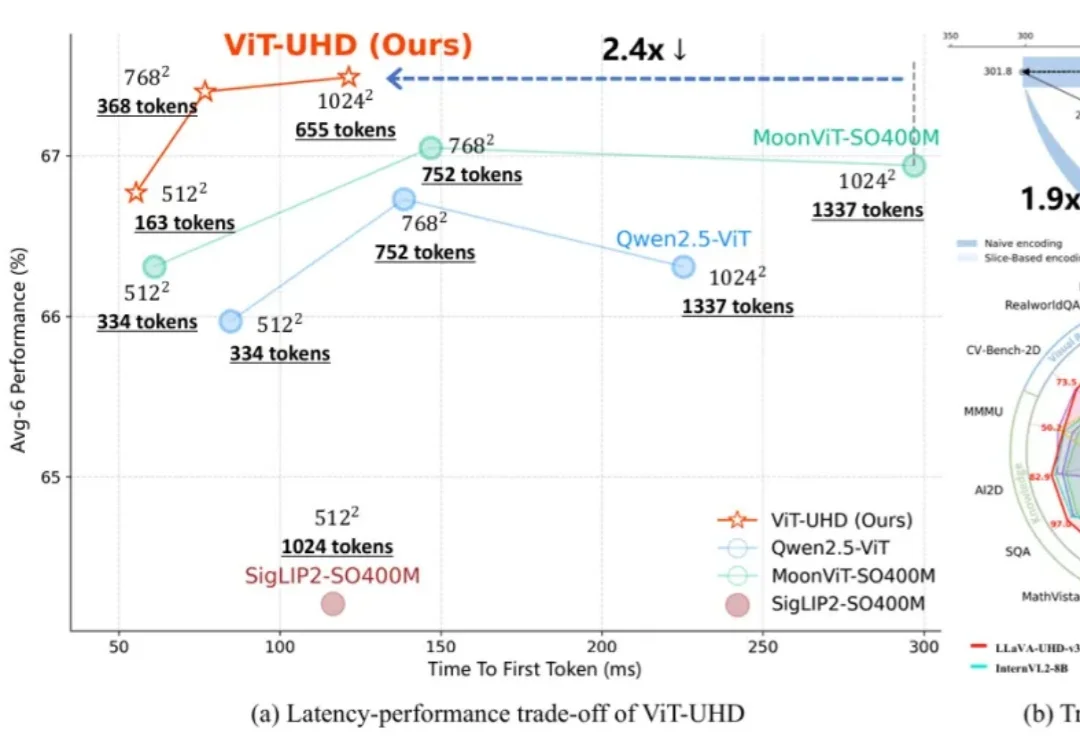
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。
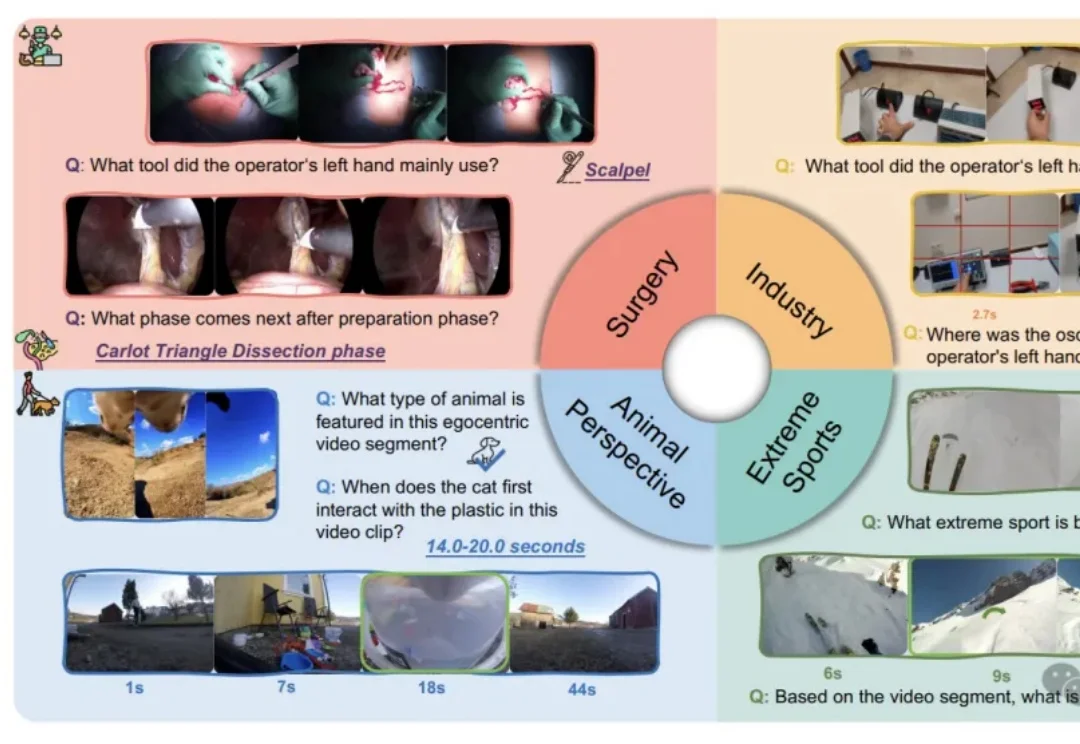
我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。
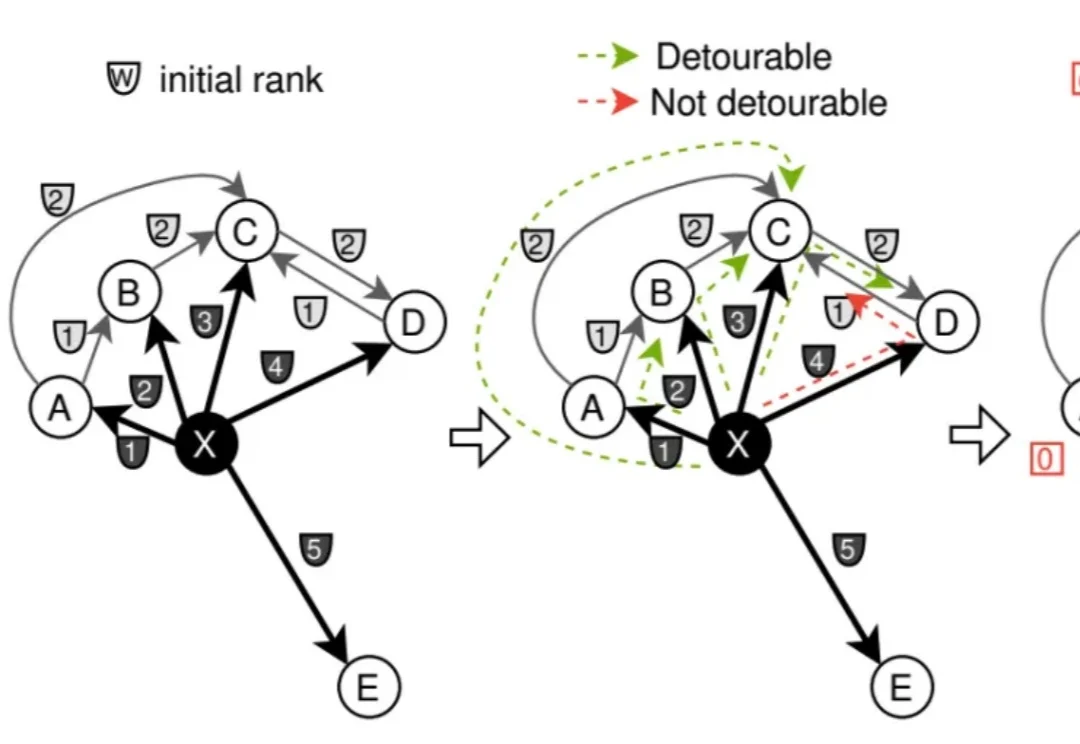
本文为Milvus Week系列第5篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。

今年以来,开源项目LightX2V 及其 4 步视频生成蒸馏模型在 ComfyUI 社区迅速走红,单月下载量超过 170 万次。越来越多创作者用它在消费级显卡上完成高质量视频生成,把“等几分钟出一段视频”变成“边看边出片”。

最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。
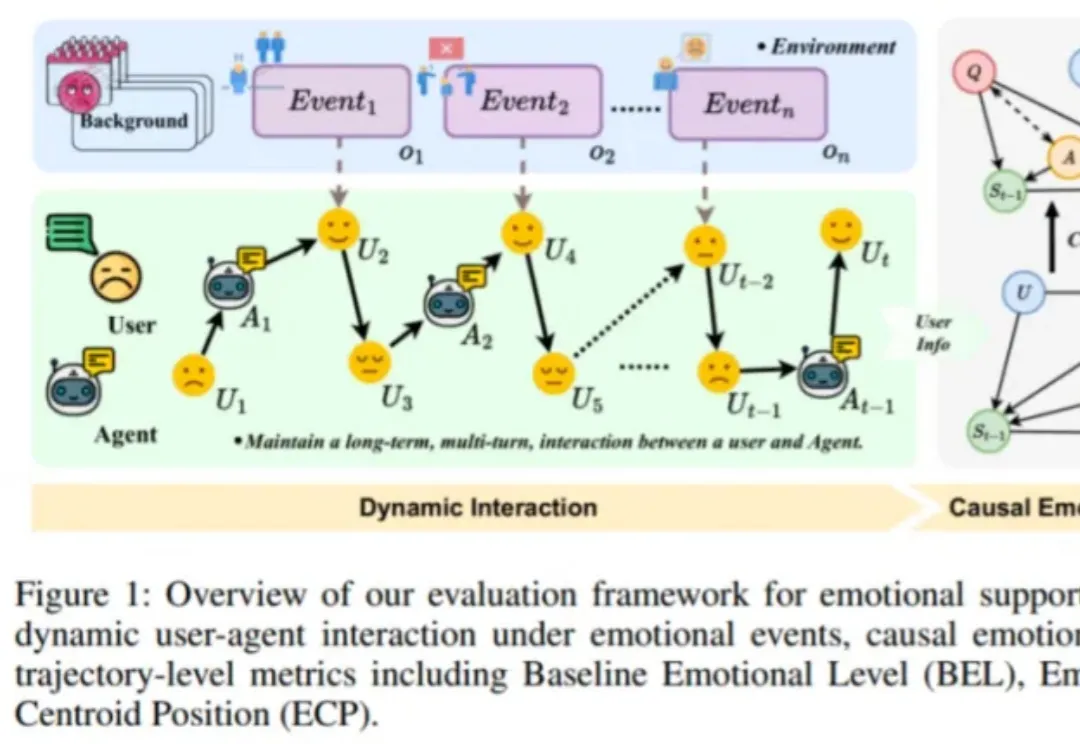
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。