LLM强化学习不稳定之谜,被Qwen团队从「一阶近似」视角解开
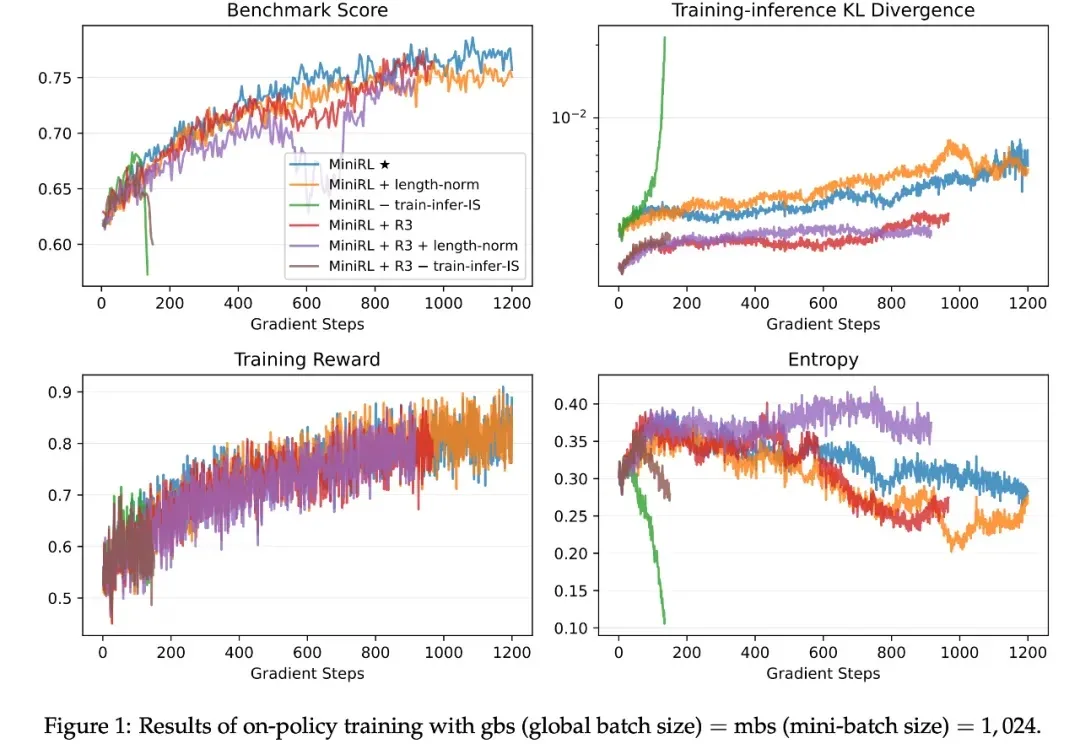
LLM强化学习不稳定之谜,被Qwen团队从「一阶近似」视角解开如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
来自主题: AI技术研报
6349 点击 2025-12-08 10:27
 搜索
搜索
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
关于如何避免让大语言模型产生幻觉,一直以来的相关研究都非常多。
2025年,AI大模型的竞争焦点正在发生根本性转移。

2025就要过去了。UC Berkeley、Stanford和IBM联手做了一件大事。他们调研了306份在一线“造 Agent”的从业者问卷,并深度访谈了20个已经成功落地并产生价值的一线企业案例(涵盖金融、科技、医疗等领域)。试图回答一个最朴素的工程问题:一个能用的、赚钱的Agent,到底是用什么架构搭出来的?

当问题又深又复杂时,一味上最强模型既贵又慢。测试时扩展能想得更久,却不一定想得更对。

走上了堪称是“最佳 AI 转型路径”之后,他也在读研期间和合作者针对 AI 记忆开展了一项研究,借此发明出一种名为 LightMem(轻量记忆)的技术。在 LongMemEval 和 LoCoMo 这两个专门用于考察 AI 长期记忆能力的基准测试上,LightMem 回答问题的准确率全面超越之前的冠军模型,最高提升了 7% 以上,在某些数据集上甚至提升了将近 30%。

在具身智能与视频理解飞速发展的今天,如何让 AI 真正 “看懂” 复杂的操作步骤?北京航空航天大学陆峰教授团队联合东京大学,提出视频理解新框架。该工作引入了 “状态(State)” 作为视觉锚点,解决了抽象文本指令与具象视频之间的对齐难题,已被人工智能顶级会议 AAAI 2026 接收。

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。
一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:

在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。