
首帧的真正秘密被揭开了:视频生成模型竟然把它当成「记忆体」
首帧的真正秘密被揭开了:视频生成模型竟然把它当成「记忆体」在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。
来自主题: AI技术研报
9124 点击 2025-12-06 11:03
 搜索
搜索
在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。

作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。

DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。 为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试
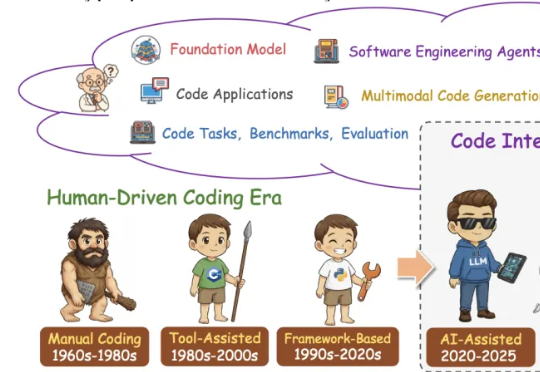
这篇学术论长文由北京航空航天大学复杂关键软件环境全国重点实验室领衔。《From Code Foundation Models to Agents and Applications》一文是对过去几年代码智能领域的一次系统梳理:模型、任务、训练、智能体、安全与应用都被串联成了一条完整、连贯的技术链路。

Anthropic发布了Programmatic Tool Calling(PTC)特性,让Claude通过代码编排工具执行,降低token消耗、减少延迟并提升准确性。

全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。

当地时间12月4日下午,谷歌研究员的一篇论文在现场引来了超多AI爱好者的围观。甚至,被业界专家视为“为AGI发展提供了新框架”,一位人士评价为:这篇论文将成为逐步推动实现AGI的5~10篇论文中的一篇。

芯片速度触顶,AI却在疯狂跃迁。摩尔定律不管用了!Nature最新文章给出一个颠覆直觉的解释:智能的增长不靠芯片,而是结构被重新组织,更多单元被接入同一套协作网络。

大模型总是无法理解空间,就像我们难以想象四维世界。

DeepSeek 一发布模型,总会引起业内的高度关注与广泛讨论,但也不可避免的暴露出一些小 Bug。