# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?
香港大学团队提出一种无需数据标记的 ViT 密集表征增强方法 PH-Reg(Post Hoc Registers),为该挑战提供了全新且高效的解决方法。该方法融合测试时增强(test-time augmentation)的去噪策略,去除教师模型密集特征中的伪影;并通过自蒸馏方法,在无需额外数据标记的条件下,得到能够输出无伪影密集特征的学生模型。
PH-Reg 具备良好的架构适配性,可灵活应用于 CLIP、DINOv2 等不同模型架构,能够高效去除密集特征的伪影,以此显著提升模型在下游任务中的性能表现。

尽管当前 ViT 模型基于数据驱动的注意力机制具备强大表示能力,但模型密集特征中存在的伪影往往会破坏其精细定位能力,而该能力对于语义分割等需高空间精度的任务而言至关重要。传统的优化方法,如在模型架构中添加 register tokens 并从头开始训练,需要消耗大量的计算资源,导致现有模型的性能提升既昂贵又耗时。
为解决上述问题,该论文提出一种高效的 PH-Reg 自蒸馏框架。该框架无需数据标记,且不再依赖 “从头开始” 的全量训练,而是通过巧妙结合测试时(test-time)密集特征增强和自蒸馏策略,仅优化学生模型中少量解锁的权重参数,即可实现无伪影的密集特征增强。
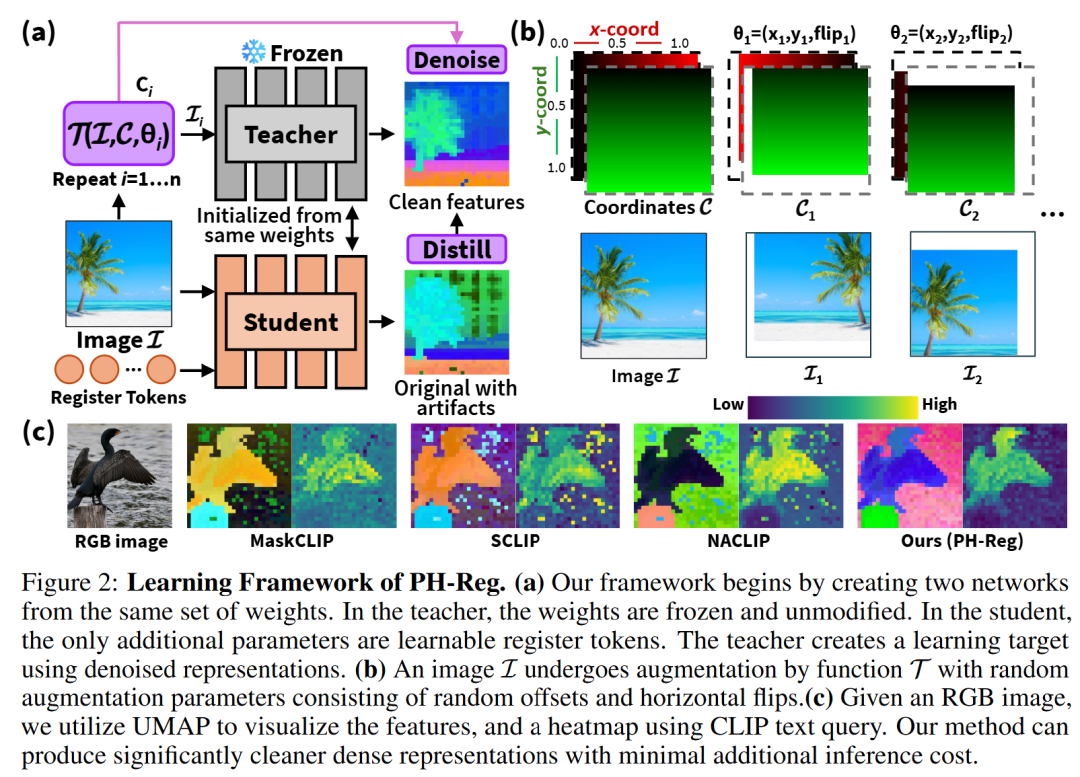
研究发现,伪影并非相对于图像内容保持静态,因此当图像经过增强处理(如随机偏移、水平翻转等)时,密集特征中的伪影并不会以相同方式或幅度同步偏移。受此启发,此算法在无需梯度反向传播的情况下,能够生成去噪且无伪影的密集特征。
PH-Reg 采用自蒸馏策略,无需依赖数据标记,仅通过引入 register tokens,以最小侵入性方式对学生模型架构进行增强。在蒸馏过程中,仅对 register tokens、卷积层、位置嵌入(positional embeddings)及最后一个 Transformer 模块进行针对性更新,既最大限度保留了 ViT 模型预训练权重的核心信息,又显著节省了计算资源。
本文应用该方法对多个 ViT 主干模型在多种密集特征预测任务上进行了系统验证,实现结果表明在不同模型与任务类型下均展现出一致且稳定的替身效果,体现了该方法的鲁棒性的广泛适用性。主要实验结果如下:
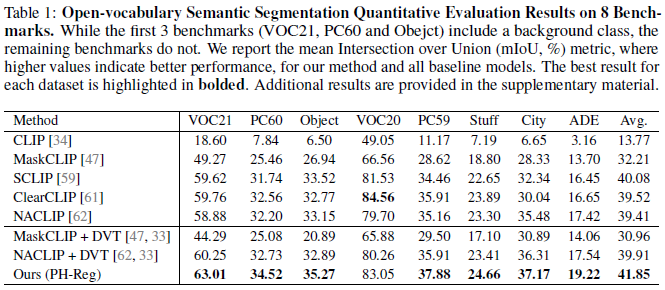
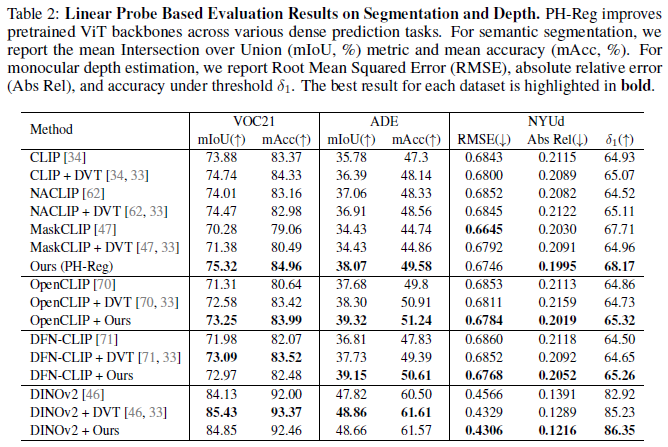
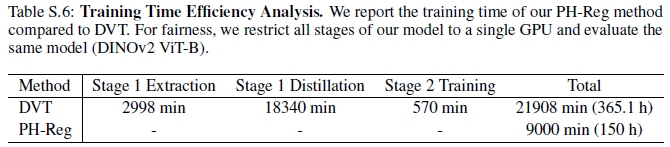
PH-Reg 框架包含了一种无需重训、即插即用的 ViT 模型去噪方案,在无需数据标记的条件下,通过自蒸馏能够高效修复 CLIP、DINOv2 等现有预训练模型中的伪影问题。
该研究不仅有效提升了 ViT 主干模型中密集特征的语义一致性,更为未来大规模视觉模型的快速微调与蒸馏机制探索提供了全新思路与研究方向。
文章来自于“机器之心”,作者 “陈寅杰、颜子鹏”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
