
打通感知-理解-交互链路,全栈视频理解大模型VideoChat3开源了
打通感知-理解-交互链路,全栈视频理解大模型VideoChat3开源了视频是描述物理世界的重要数据形态,更是人类与物理世界交互的重要载体,视频理解大模型是让 AI 从数字世界走向物理世界最基础、最原生的组成部分。
来自主题: AI技术研报
7798 点击 2026-07-23 10:37
 搜索
搜索
视频是描述物理世界的重要数据形态,更是人类与物理世界交互的重要载体,视频理解大模型是让 AI 从数字世界走向物理世界最基础、最原生的组成部分。
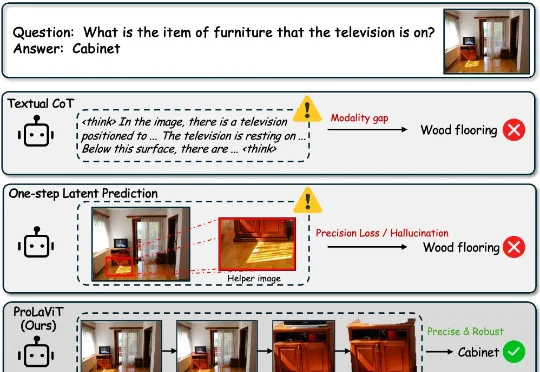
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。
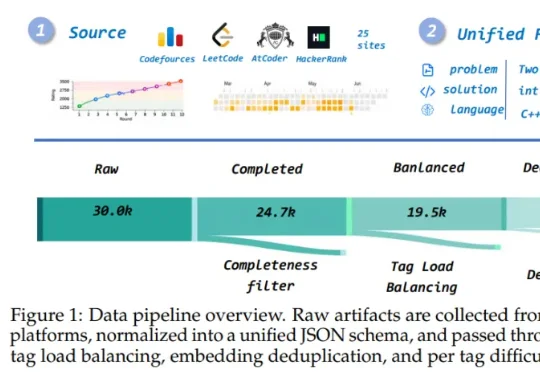
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。
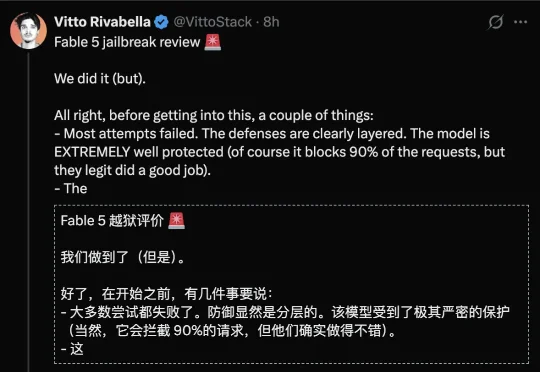
Fable 5再次被越狱了!这已经是该模型第二次防线失守。黑客Vitto Rivabella,公开宣布:Fable 5,又被攻破了。要知道,Claude Fable 5恢复访问时,Anthropic特意强调:上次Fable 5被禁就是因为亚马逊的研究人员发现了一种绕过Fable 5安全防护的方法。
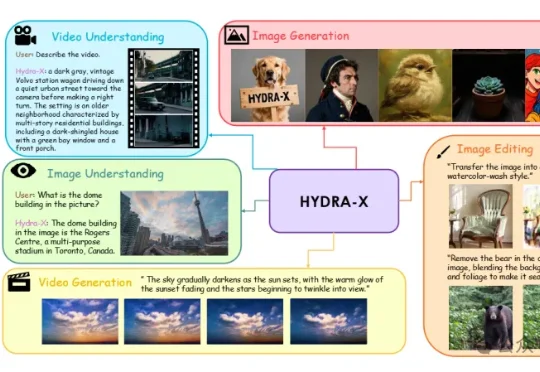
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

继 Step 3.5 Flash 后,阶跃星辰最近又推出新一代高效率 Flash 开源模型 ——Step 3.7 Flash。该模型最大特点就是多(模)、快(速)、好(用)、省(钱)。总参数 196B,采用稀疏 MoE 架构,推理激活参数仅 11B,配备 1.88B ViT 视觉编码器,推理速度最高 400 TPS,支持 256K 上下文。

他身前是13英寸笔记本,眼前铺开的则是174英寸的超宽屏幕。这块屏幕来自这幅XR智能眼镜,屏幕上同时铺着三个窗口:左边是Claude Code,代码正一行行往外吐;中间是编辑器,光标在等他的下一次指令;右边是飞书,同事刚发来一条消息。而这并非幻想画面。实际上,这是使用VITURE眼镜进行vibe coding的新潮流。

很多人知道,苹果 Vision pro 是 VR 眼镜的市场标杆产品,Meta和Google都曾大举进军AI眼镜,但鲜有人知的是,2025年冲到北美第一的 XR 眼镜,是一家很低调的公司——VITURE。

谷歌旗下AI开发工具Antigravity(反重力)近日推送2.0版本更新,却引发开发者社区强烈反弹。这次被官方称为"升级"的更新实际上将原有的VS Code风格IDE功能剥离,替换为纯Agent模式界面,导致大量用户配置丢失、插件失效,开发者纷纷寻找回退方案。
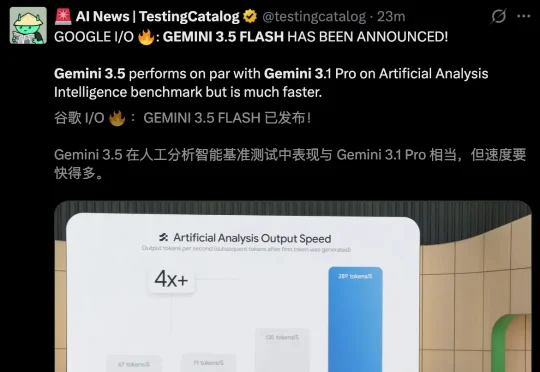
劈柴和Hassabis把半年大招一晚清仓了!Gemini Omni任意输入生成视频,3.5 Flash断层碾压一切,Spark 7×24h云端替你干活。这次,谷歌是要把OpenAI和Anthropic一起给埋了。