
超越π0.5,复旦团队首创「世界模型+具身训练+强化学习」闭环框架
超越π0.5,复旦团队首创「世界模型+具身训练+强化学习」闭环框架Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。
来自主题: AI技术研报
9908 点击 2025-12-05 09:27
 搜索
搜索
Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。

这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。
本文为Milvus Week系列第三篇,该系列旨在分享Milvus的创新与实践成果,以下是DAY3内容划重点: Milvus2.6中,Zilliz借助Geolocation Index for Milvus,首次将地理空间数据与向量检索融合,使 AI 可以在理解语义的同时,理解空间。

最近研究发现,大模型在判断逻辑谬误时容易「想太多」,误报正常句子,但在确定有谬误后,其分类能力较强。研究人员构建了首个高质量英文逻辑谬误基准SMARTYPAT-BENCH,并开发了基于Prolog的逻辑谬误自动生成框架SMARTYPAT,为大模型逻辑能力评估提供新思路,可用于谬误识别、辩论教育等领域。

昨日,有位推特博主晒出了国内几大开源模型在轻量级软件工程 Agent 基准测试 mini-SWE-agent 上的成绩。该基准主要测试大模型在真实软件开发任务中的多步推理、环境交互和工程化能力。

在AIGC的浪潮中,3D生成模型(如TRELLIS)正以惊人的速度进化,生成的模型越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。复杂的去噪过程、庞大的计算量,让生成一个高质量3D资产往往需要漫长的等待。
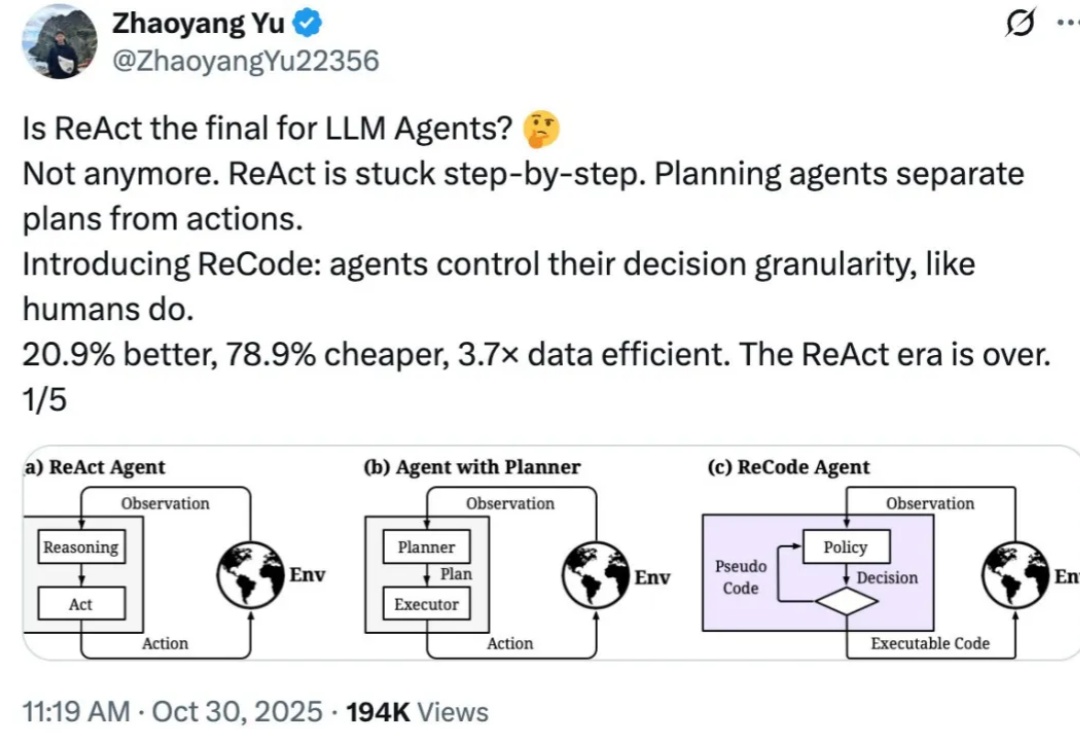
想象你在准备早餐:你不会先写一份详细到「左手抓鸡蛋、右手拿碗、手腕旋转 45 度敲击蛋壳」这样的清单,也不会只有一个笼统的计划叫「做个早餐」,然后不知所措。

DeepSeek V3.2的Agentic能力大增,离不开这项关键机制:Interleaved Thinking(交错思维链)。Interleaved Thinking风靡开源社区背后,离不开另一家中国公司的推动。

OpenAI搞了个新活:让ChatGPT自己“坦白从宽”。
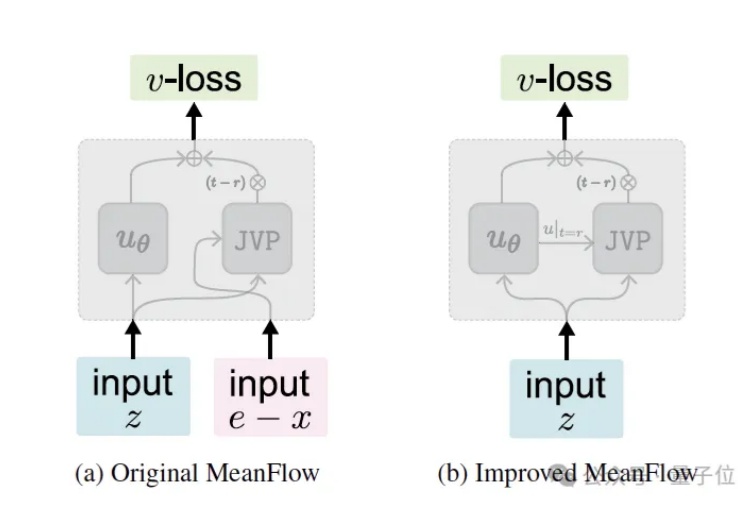
继今年5月提出MeanFlow (MF) 之后,何恺明团队于近日推出了最新的改进版本—— Improved MeanFlow (iMF),iMF成功解决了原始MF在训练稳定性、指导灵活性和架构效率上的三大核心问题。