NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构
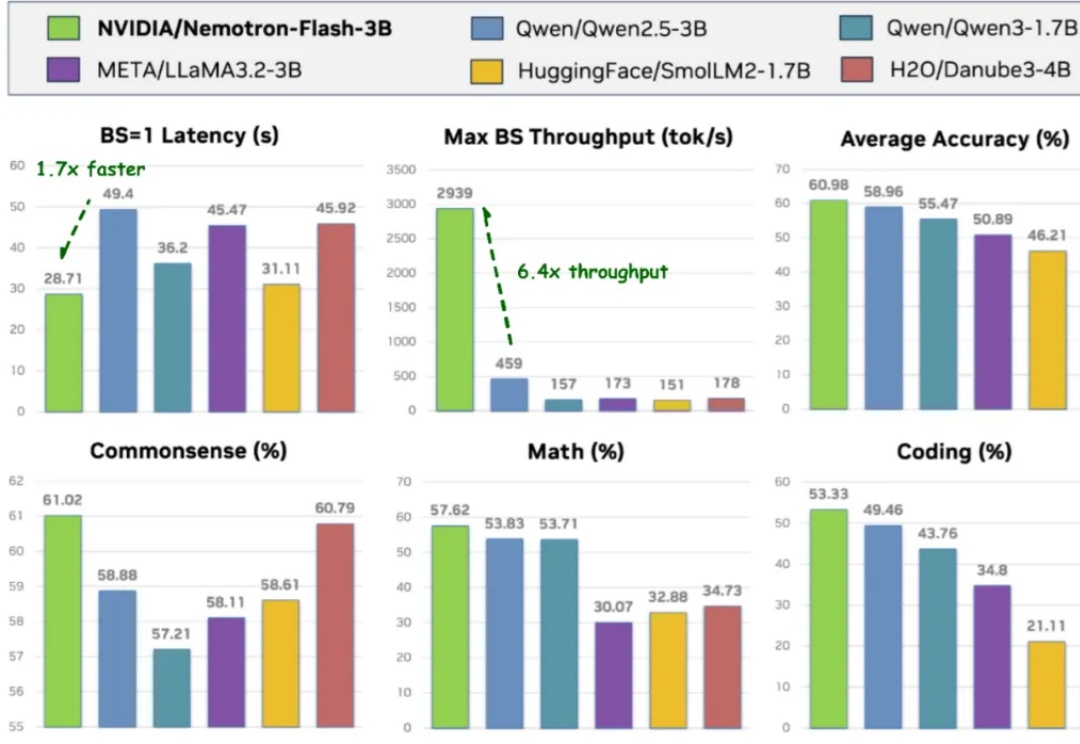
NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。
来自主题: AI技术研报
8816 点击 2025-12-01 10:09
 搜索
搜索
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。

OpenAI,亟需一场翻身仗!今天,全网最大的爆料:GPT-5基石实为GPT-4o。自4o发布之后,内部预训练屡屡受挫,几乎沦为「弃子」。
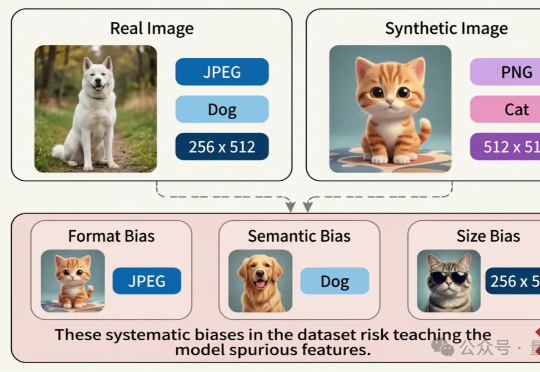
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

本文第一作者为刘禹宏,上海交通大学人工智能专业本科四年级学生,相关研究工作于上海人工智能实验室科研实习期间完成。通讯作者为王佳琦、臧宇航,在该研究工作完成期间,均担任上海人工智能实验室研究员。

人工智能研究的最新目标,尤其是在追求“通用人工智能”(AGI)的实验室中,是一个被称为“世界模型”(world model)的概念:这是一种AI内部携带的环境表征,就像一个计算型的雪球玻璃球。AI系统可以借助这个简化的内部模型,在真正执行任务之前,先对预测和决策进行评估。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?

而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。