
17万条推理轨迹扒出AI推理的真相:有劲儿,但用错了地方|哈佛新论文解读
17万条推理轨迹扒出AI推理的真相:有劲儿,但用错了地方|哈佛新论文解读而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。
来自主题: AI技术研报
8992 点击 2025-11-29 20:10
 搜索
搜索
而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。

大无语事件天天有,今天特别多——AI大模型公司阶跃星辰的研究员,自曝被苹果挂在arXiv上的论文,狠狠坑了一把。自己去反馈问题,对方简单回了两句就把issue关了;直到自己留下公开评论,对方才撤稿下架代码了。

RAG效果不及预期,试试这10个上下文处理优化技巧。对大部分开发者来说,搭一个RAG或者agent不难,怎么把它优化成生产可用的状态最难。在这个过程中,检索效率、准确性、成本、响应速度,都是重点关注问题。
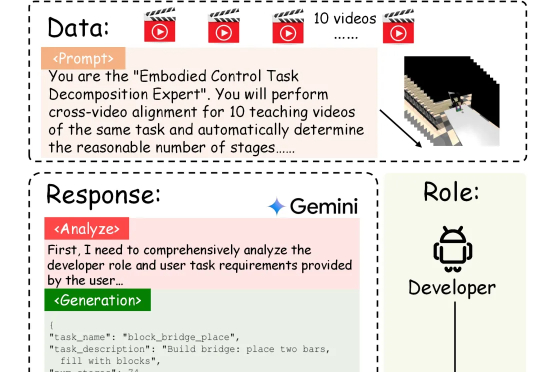
具身智能的「ChatGPT时刻」还没到,机器人的「幻觉」却先来了?在需要几十步操作的长序列任务中,现有的VLA模型经常「假装在干活」,误以为任务完成。针对这一痛点,北京大学团队提出自进化VLA框架EvoVLA。该模型利用Gemini生成「硬负样本」进行对比学习,配合几何探索与长程记忆,在复杂任务基准Discoverse-L上将成功率提升了10.2%,并将幻觉率从38.5%大幅降至14.8%。

人工智能在过去的十年中,以惊人的速度革新了信息处理和内容生成的方式。然而,无论是大语言模型(LLM)本体,还是基于检索增强生成(RAG)的系统,在实际应用中都暴露出了一个深层的局限性:缺乏跨越时间的、可演化的、个性化的“记忆”。它们擅长瞬时推理,却难以实现持续积累经验、反思历史、乃至真正像人一样成长的目标。
在软件开发领域,需求工程(Requirements Engineering, RE)一直是项目成功的关键环节。然而,传统 RE 方法面临着效率低下、需求变更频繁等挑战。根据 Standish Group 的报告,仅有 31% 的软件项目能在预算和时间内完成,而需求相关问题导致的项目失败率高达 37%。

Context Pruning如何结合rerank,优化RAG上下文?
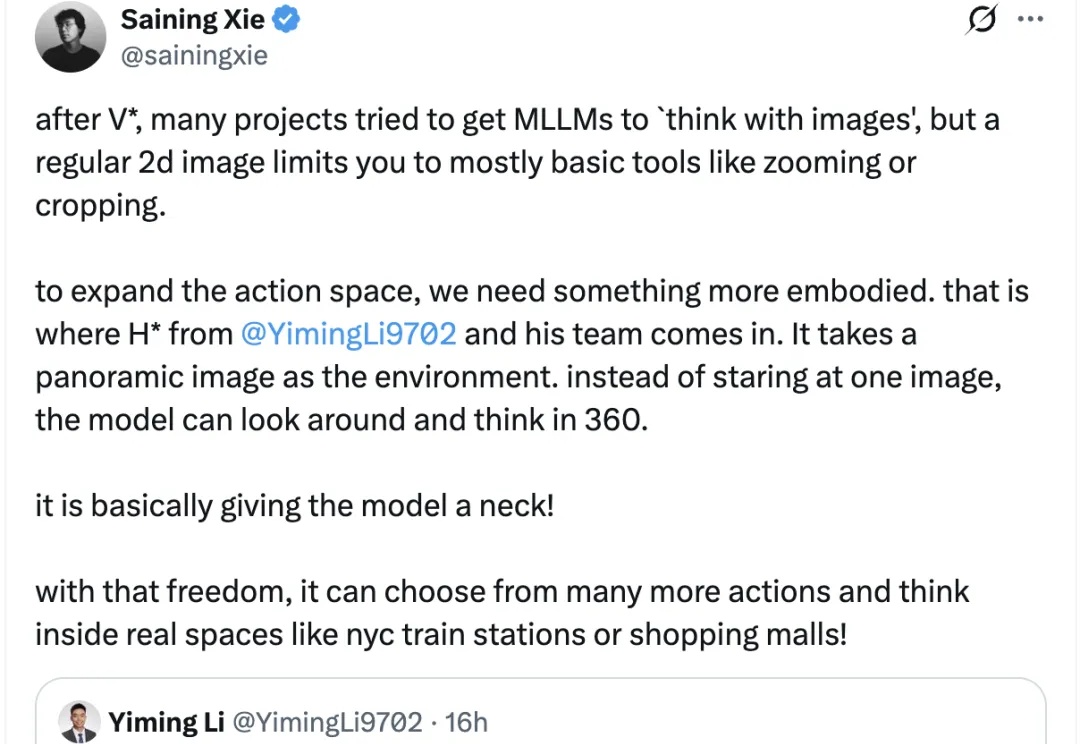
终于有人要给大模型安“脖子”了!