
RAG效果要提升,先搞定高质量Context Pruning
RAG效果要提升,先搞定高质量Context PruningContext Pruning如何结合rerank,优化RAG上下文?
来自主题: AI技术研报
9771 点击 2025-11-28 10:05
 搜索
搜索
Context Pruning如何结合rerank,优化RAG上下文?
终于有人要给大模型安“脖子”了!

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
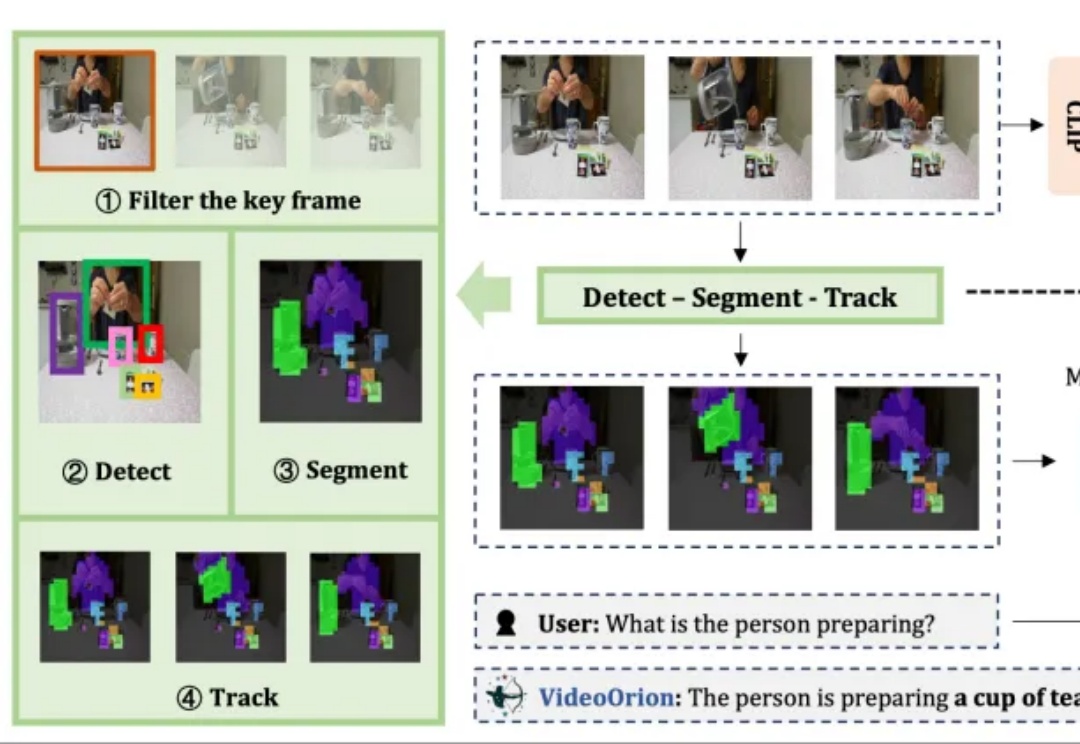
被顶会ICCV 2025以554高分接收的视频理解框架来了!
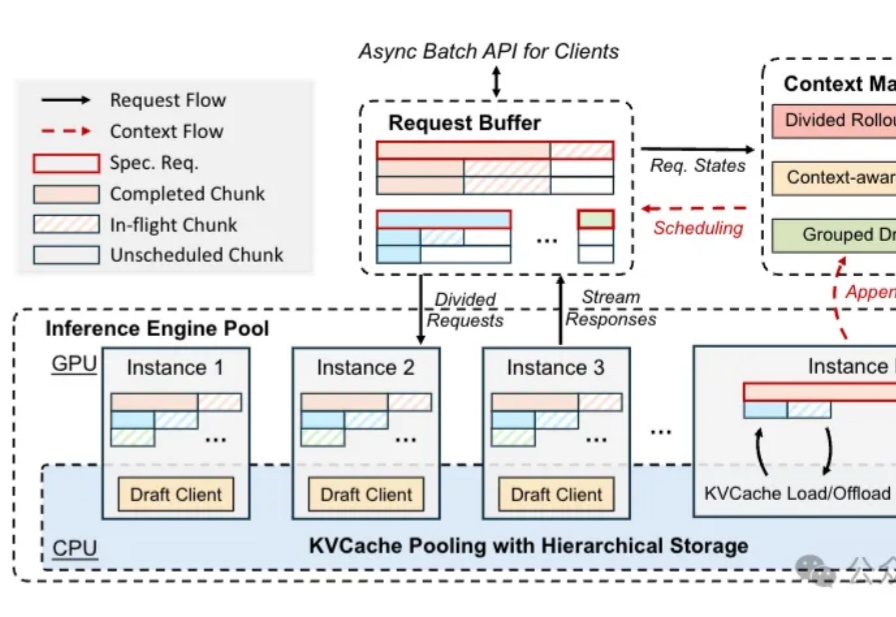
u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……

从单张图像创建可编辑的 3D 模型是计算机图形学领域的一大挑战。传统的 3D 生成模型多产出整体式的「黑箱」资产,使得对个别部件进行精细调整几乎成为不可能。

当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。
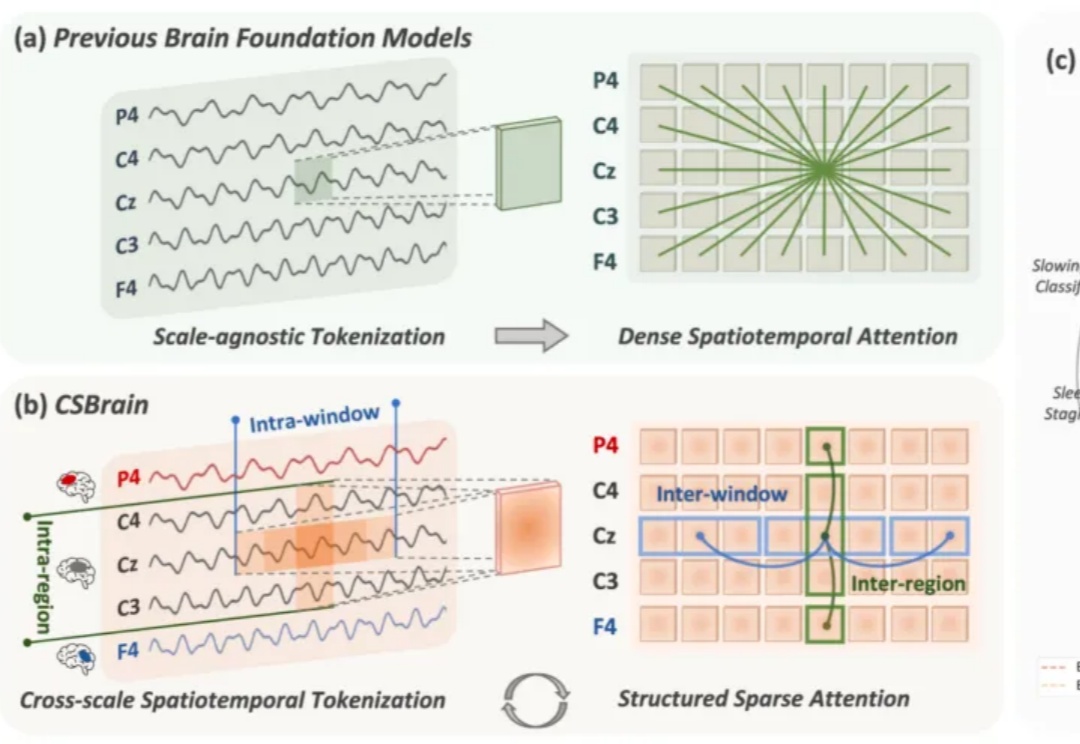
脑机接口(Brain-Computer Interface, BCI)被视为连接人类智能与人工智能的终极界面。要真正实现这一愿景,核心在于高精度的脑信号解码,即让通用 AI 模型能够真正「读懂」复杂多变的脑活动。

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。

智能体终于拥有了可以海量复制的“实战演练场”。阿里此次开源的新项目ROCK,解决了无法在真实环境中规模化训练的难题。有了ROCK,开发者想要训练AI执行复杂任务时可以不再“手搓”环境,直接进行标准化的一键部署。