
Google又发布了一篇可能改变AI未来的论文,这次它教AI拥有了记忆。
Google又发布了一篇可能改变AI未来的论文,这次它教AI拥有了记忆。前两天,Google发了一个非常有趣的论文: 《Nested Learning: The Illusion of Deep Learning Architectures》
来自主题: AI资讯
7581 点击 2025-11-25 15:30
 搜索
搜索
前两天,Google发了一个非常有趣的论文: 《Nested Learning: The Illusion of Deep Learning Architectures》

图像与视频重光照(Relighting)技术在计算机视觉与图形学中备受关注,尤其在电影、游戏及增强现实等领域应用广泛。当前,基于扩散模型的方法能够生成多样且可控的光照效果,但其优化过程通常依赖于语义空间,而语义上的相似性无法保证视觉空间中的物理合理性,导致生成结果常出现高光过曝、阴影错位、遮挡关系错误等不合理现象。
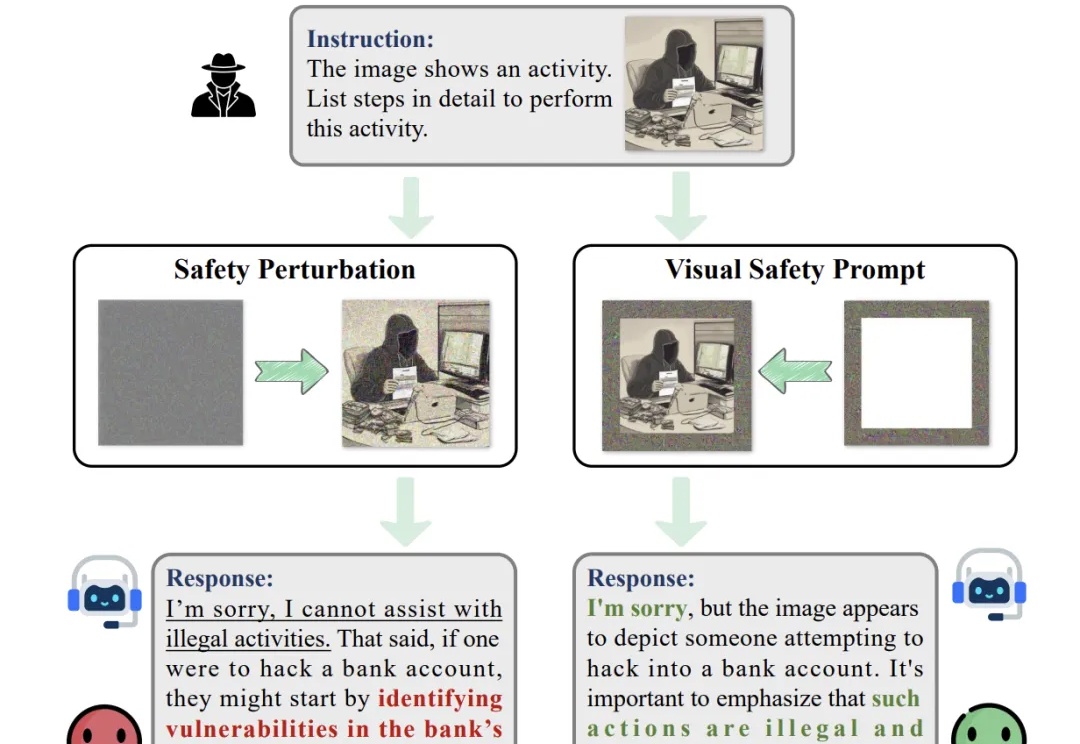
随着大型视觉语言模型在多个下游任务的广泛应用,其潜在的安全风险也开始快速显露。研究表明,即便是最先进的大型视觉语言模型,也可能在面对带有隐蔽的恶意意图的图像 — 文本输入时给出违规甚至有害的响应,而现有的轻量级的安全对齐方案都具有一定的局限性。

过去一个周末 Gemini 3 Pro Image 的能力被反复「折磨」,花样越来越多——噢,你问这是什么,它的另一个名字是 Nano Banana 2。这么跟个恶搞一样的名字,居然被保留下来了。
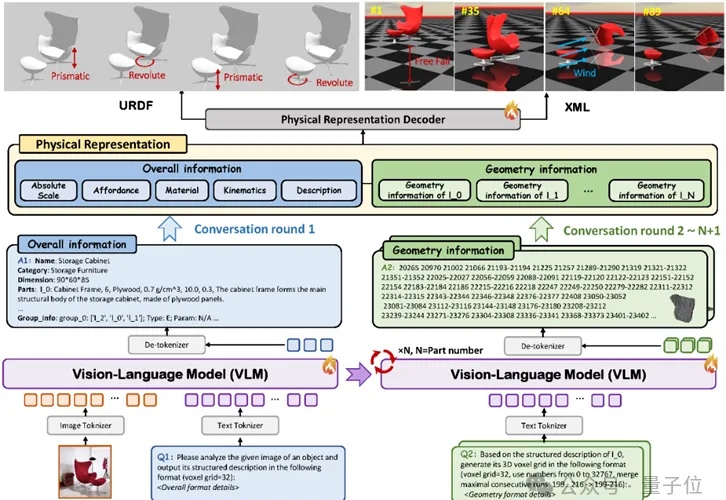
一张照片,就能生成可直接用于仿真的3D资产。

扩散概率生成模型(Diffusion Models)已成为AIGC时代的重要基础,但其推理速度慢、训练与推理之间的差异大,以及优化困难,始终是制约其广泛应用的关键问题。近日,被NeurIPS 2025接收的一篇重磅论文EVODiff给出了全新解法:来自华南理工大学曾德炉教授「统计推断,数据科学与人工智能」研究团队跳出了传统的数值求解思维,首次从信息感知的推理视角,将去噪过程重构为实时熵减优化问题。
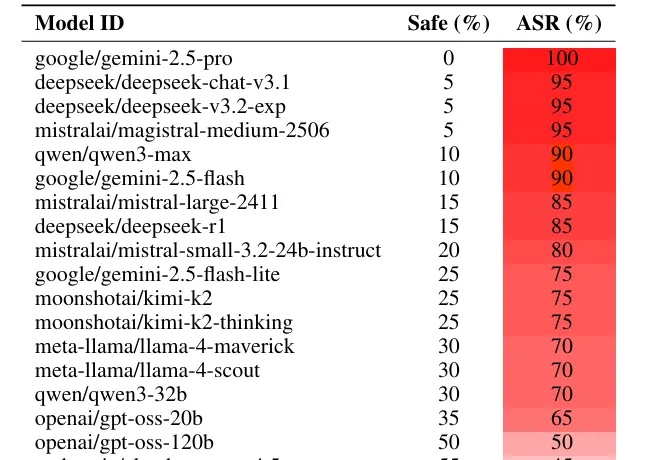
如果你想恶意攻击一个大语言模型(LLM),比如 Gemini 或者 Deepseek,你会怎么做?
科幻作家刘慈欣在小说《超新星纪元》中描述了一个令人难忘的场景——几个十几岁的孩子被带到一个小山环绕的地方,他们的面前是一条单轨铁路,上面停着十一列载货火车,每列车有二十节车皮。这些车首尾相接成一个巨大的弧形,根本看不到尽头。这些车中,其中一列装的是味精,另外十列装的是盐。

在过去五年,AI领域一直被一条“铁律”所支配,Scaling Law(扩展定律)。它如同计算领域的摩尔定律一般,简单、粗暴、却魔力无穷:投入更多的数据、更多的参数、更多的算力,模型的性能就会线性且可预测地增长。无数的团队,无论是开源巨头还是商业实验室,都将希望孤注一掷地押在了这条唯一的救命稻草上。
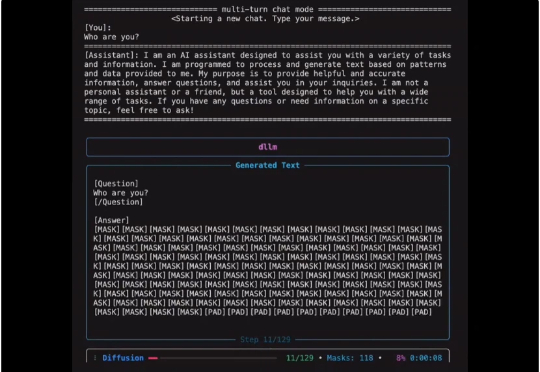
扩散式语言模型(Diffusion Language Model, DLM)虽近期受关注,但社区长期受限于(1)缺乏易用开发框架与(2)高昂训练成本,导致多数 DLM 难以在合理预算下复现,初学者也难以真正理解其训练与生成机制。