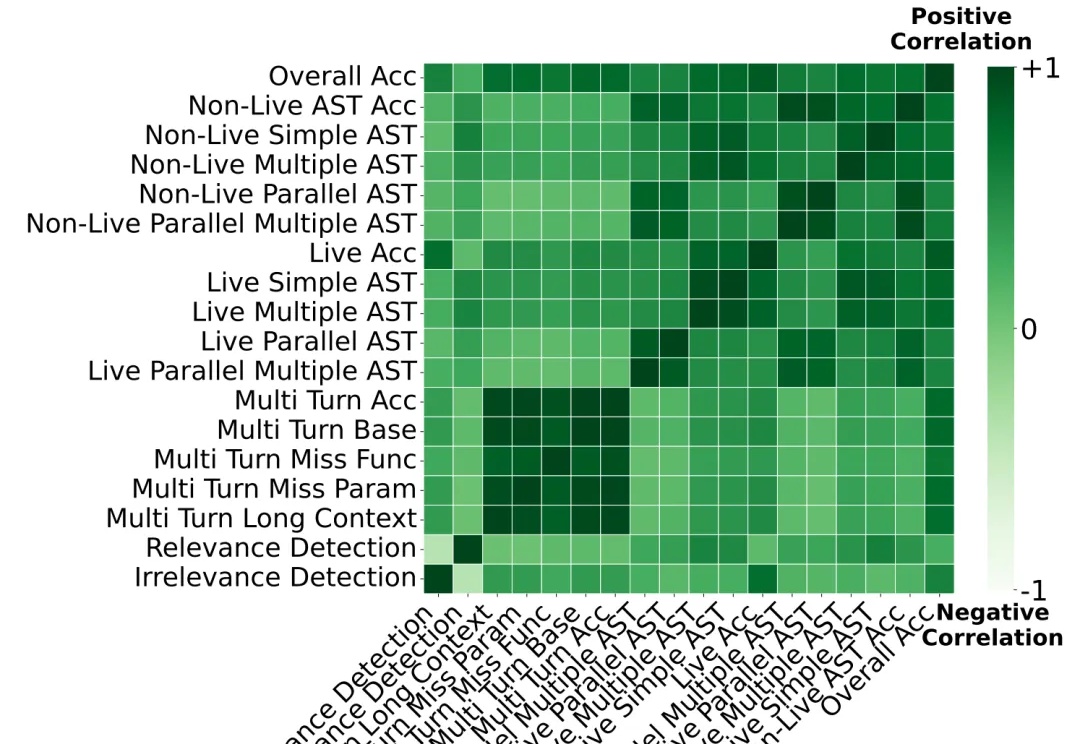
Meta超级智能实验室又发论文,模型混一混,性能直接SOTA
Meta超级智能实验室又发论文,模型混一混,性能直接SOTA模型也要学会取长补短。
来自主题: AI技术研报
6881 点击 2025-11-24 10:18
 搜索
搜索
模型也要学会取长补短。
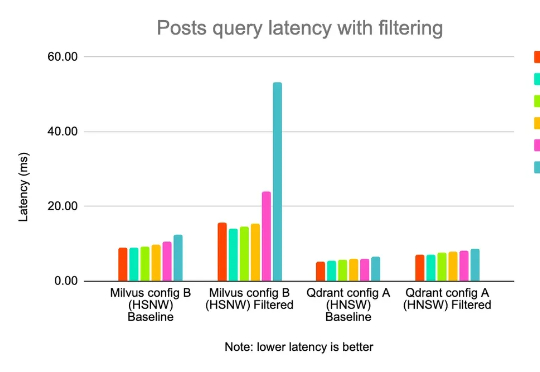
业务团队可能说他们想要个负重一吨,时速两百公里的马车…… 现如今,借助向量检索能力,实现基于语义相似度的智能搜索,已经是所有电商、推荐、社区平台技术架构的重要一环。 作为拥有约 1.08 亿日活、 1

刚刚,Anthropic 发布了一项新研究成果。今天,他们发布的成果是《Natural emergent misalignment from reward hacking》,来自 Anthropic 对齐团队(Alignment Team)。他们发现,现实中的 AI 训练过程可能会意外产生未对齐的(misaligned)模型。
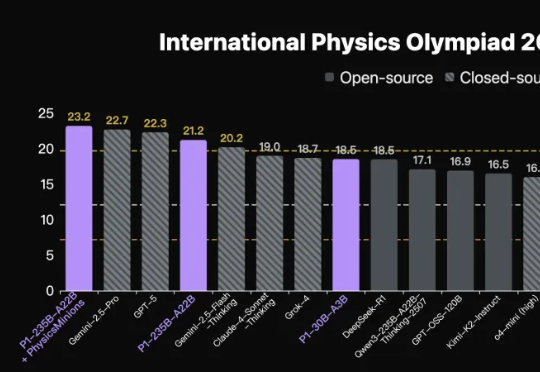
首个拿下国际物理奥林匹克竞赛IPhO 2025理论考试金牌的开源模型,出自国产。上海人工智能实验室团队推出新模型家族,代号P1。在IPhO 2025理论考试中,P1-235B-A22B取得21.2/30分,成为首个达到该金牌线的开源模型,仅次于Gemini-2.5-Pro与GPT-5。

今天,来自快手可灵团队和香港城市大学的研究者们,正在尝试打破这一界限。他们提出了一个全新的任务范式——「视频作为答案」,并发布了相应模型VANS。而这项工作则开创性地提出了Video-Next Event Prediction任务,要求模型直接生成一段动态视频作为回答。

就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
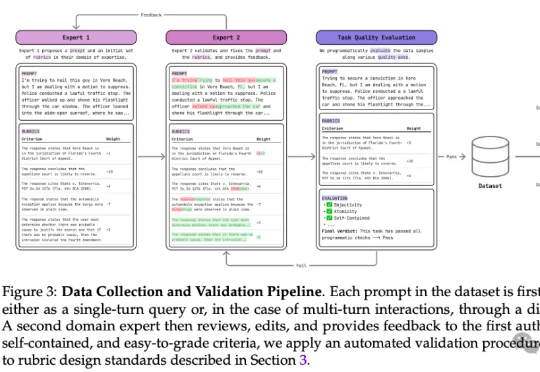
最新PRBench基准可以测试AI在金融和法律领域的表现。结果显示,即使是顶尖大模型在处理复杂任务时也表现不佳,尤其在涉及重大经济后果的任务中。PRBench通过模拟真实场景和多轮对话,揭示了AI在专业领域的不足,强调开发更可靠AI系统的重要性。
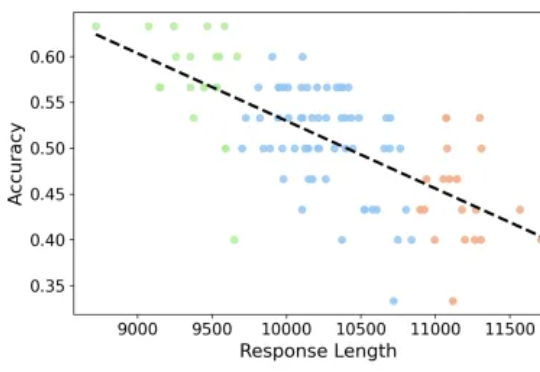
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作

前沿AI竞赛在2025年11月达到高潮。48小时内,谷歌推出Gemini 3 Pro宣称在主要推理基准测试中领先,而OpenAI立即用GPT-5.1-Codex-Max反击,这是一款专门训练用于通过创新"压缩"(compaction)技术自主工作超过24小时的专业编码模型[43]。加上Claude Sonnet 4.5已确立的编码统治地位和激进的安全过滤器,开发者面临前所未有的选择:
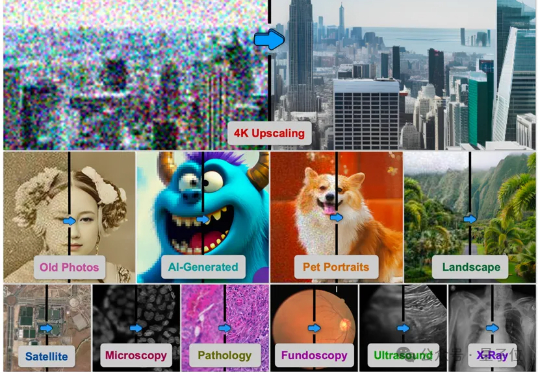
由德克萨斯A&M大学、斯坦福大学、Snap公司、CU Boulder大学、德克萨斯大学奥斯汀分校、加州理工大学、Topaz Labs以及加州大学Merced分校的研究者联合提出的基于AI智能体的方法4KAgent针对不同类型的图像以及需求对图像进行智能修复并放大到4K分辨率,带来优秀的视觉感知效果。该工作已被NeurIPS 2025接收。