
AI又封神了!华人新作直出憨豆+《猫和老鼠》,平行宇宙对上戏了
AI又封神了!华人新作直出憨豆+《猫和老鼠》,平行宇宙对上戏了憨豆先生坐在《猫和老鼠》的客厅里,汤姆在一旁跌进油漆桶,杰瑞躲在沙发后偷笑。这一幕,不是梦,也不是恶搞,而是AI真实生成的画面。在最新一篇论文中,研究者让从未共存的角色相遇,并解决了「风格错乱」的世纪难题。也许,我们正在迎接一个虚构与真实彻底混合的时代。
来自主题: AI技术研报
10364 点击 2025-11-17 10:21
 搜索
搜索
憨豆先生坐在《猫和老鼠》的客厅里,汤姆在一旁跌进油漆桶,杰瑞躲在沙发后偷笑。这一幕,不是梦,也不是恶搞,而是AI真实生成的画面。在最新一篇论文中,研究者让从未共存的角色相遇,并解决了「风格错乱」的世纪难题。也许,我们正在迎接一个虚构与真实彻底混合的时代。

和任何人,去任何地方!复旦大学携手阶跃星辰打破 “复制粘贴” 魔咒,重磅推出全新 AI 合照生成模型 WithAnyone —— 只需上传照片,就能一键生成自然、真实、毫无违和感的 AI 合照!
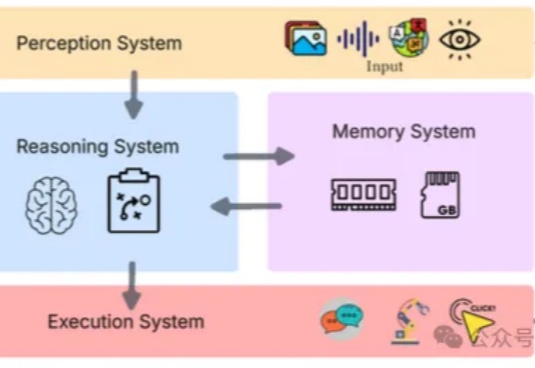
如何构建一个真正意义上的“自主代理”(Agent),而不是一个“带LLM的高级工作流”? 让钢铁侠中的“贾维斯”(J.A.R.V.I.S.)真正来到现实,不仅能对话,还能调动资源、控制机械、在复杂战局中自主执行多步任务。
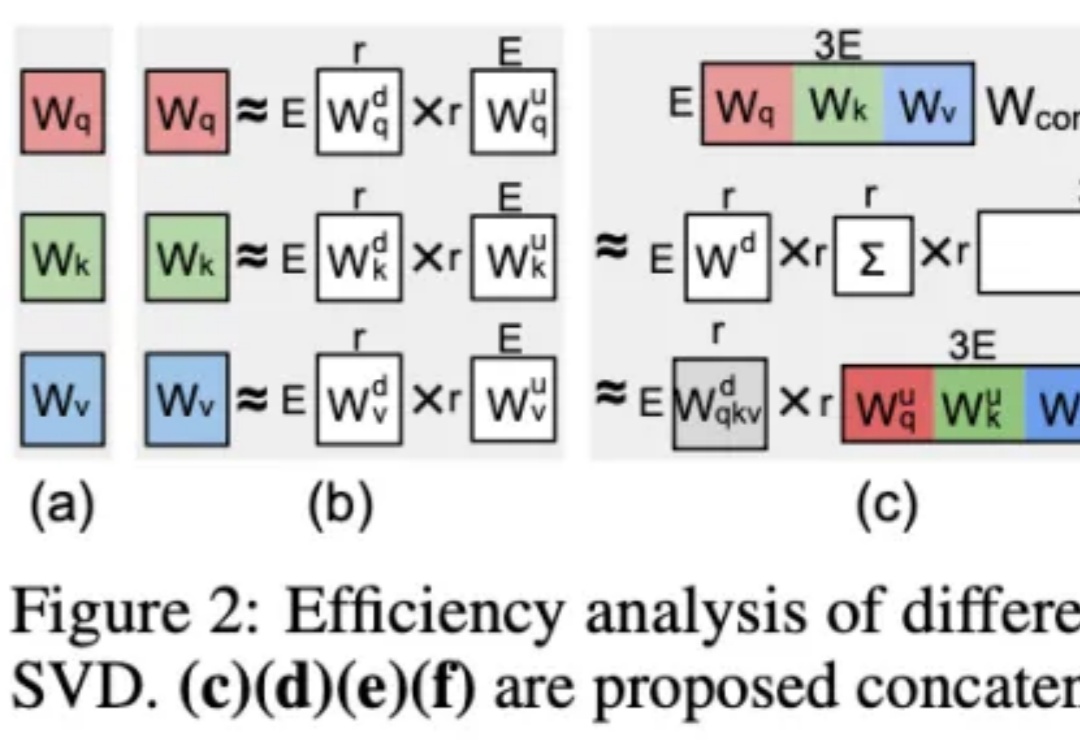
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
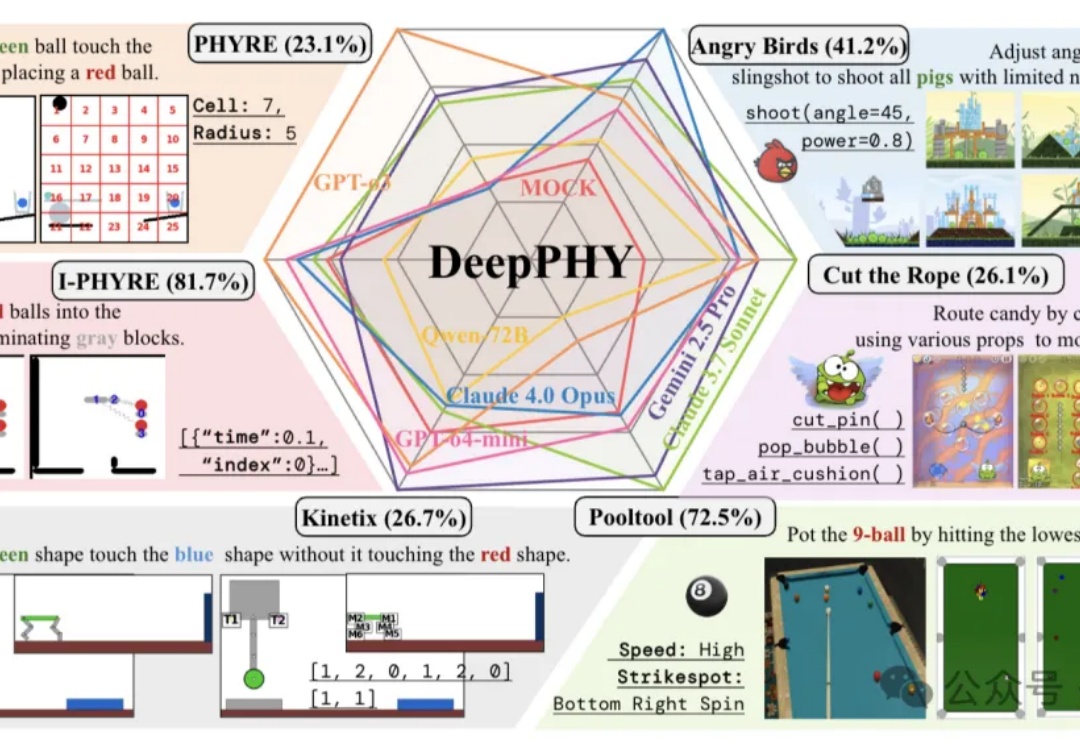
首个系统性评估多模态大模型(VLM)交互式物理推理能力的综合基准来了。

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
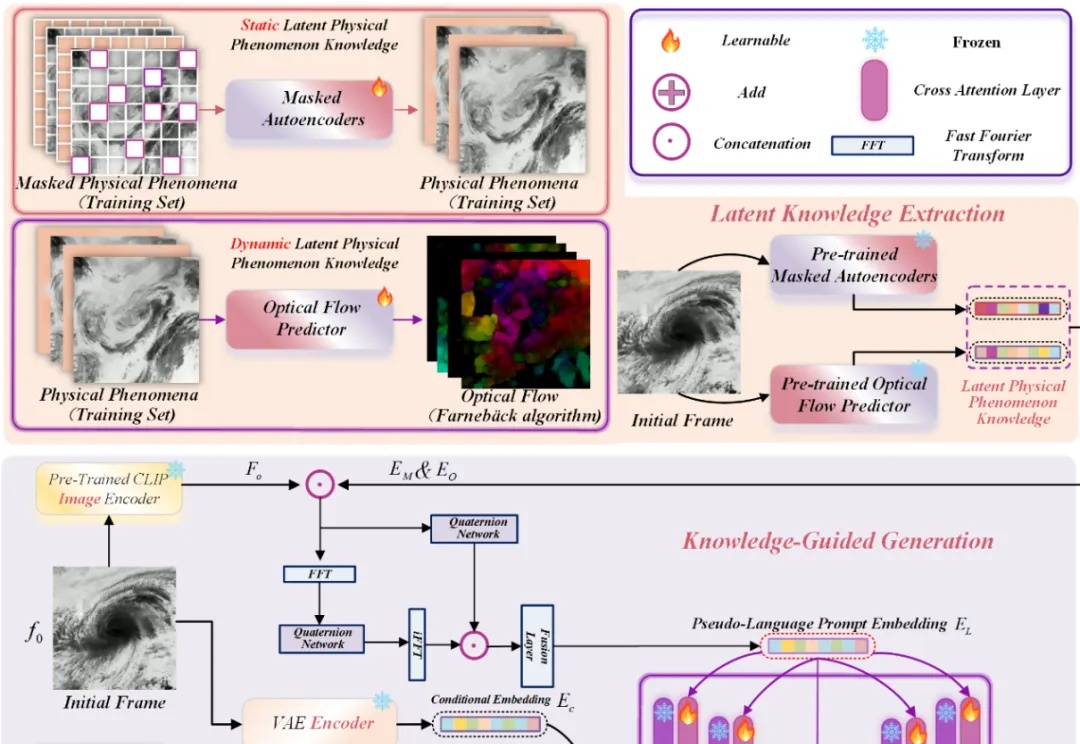
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。

人类的下一个分裂,从算法开始。 作者|Moonshot 编辑|靖宇 在生成式 AI 的早期叙事里,AI 大模型曾被描绘得理性、冷静、无偏见。 然而,不到三年时间,这个叙事迅速崩塌。事实正在变得越来越清

机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
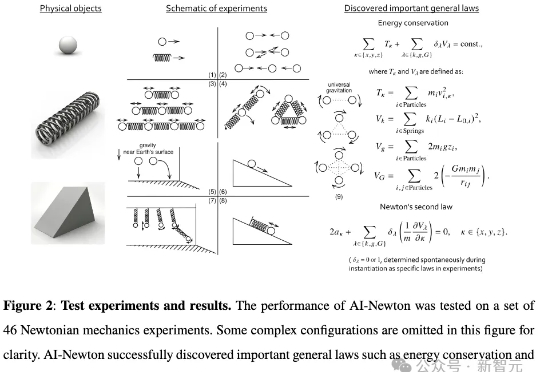
人类数千年的科学探索,如今被AI「顿悟」瞬间复刻。北京大学研究团队推出的名为AI-Newton的AI系统,重新发现了牛顿第二定律、能量守恒定律和万有引力定律等基础规律,这一成果被视作AI驱动自主科学发现的一项重要进展。